
In the modern enterprise, data has become the most valuable asset — yet paradoxically, it's often the most difficult to leverage. Organizations are drowning in data while starving for insights, trapped in a cycle where the very abundance that should empower them instead paralyzes decision-making.
This presentation traces the evolution of data catalogs from simple metadata repositories to sophisticated, AI-powered platforms that are fundamentally reshaping how organizations discover, govern, and derive value from their data assets. We'll explore how technical innovations like Apache Iceberg and open standards like the REST Catalog API have transformed catalogs from passive inventories into active transaction managers and intelligent discovery engines.
From the broken promises of data lakes to the emergence of semantic search and ML model cataloging, this is the story of how data catalogs evolved to become the central nervous system of the modern data platform — enabling not just governance, but true data democratization and AI-driven innovation.
The Data Lake's Broken Promise
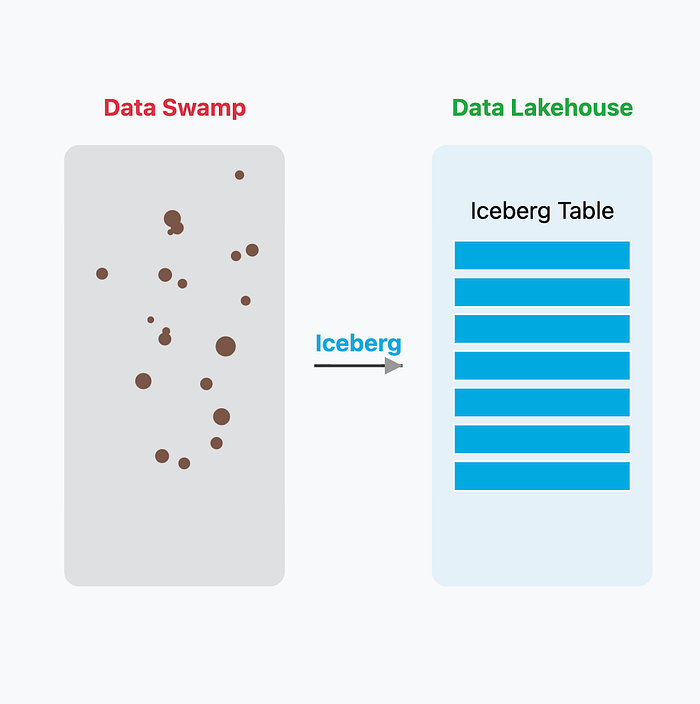
Data lakes promised to be the central repository for all enterprise data, offering massive scale and flexibility. However, this promise was quickly broken. Without the transactional guarantees and metadata management of traditional databases, they became "data swamps" — unreliable, ungovernable, and nearly impossible to query with confidence because a failed write job could leave data in a corrupt, partial state.
This core reliability problem led to a crisis of trust and a massive waste of resources, as users spent more time searching for usable data than analyzing it.

Diagnosing the Swamp: The Failure of Early Catalogs
The root of the data swamp was a failure in metadata management. Early attempts to catalog data in the lake were simply not built for concurrent, transactional workloads.
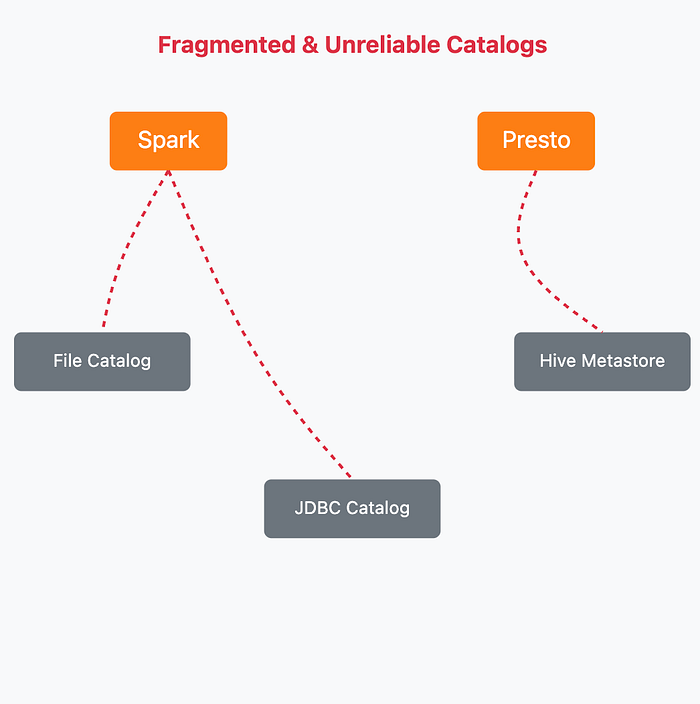
The First Wave of Catalogs
- File-Based Catalogs: Storing metadata in files within the data directory was simple but failed spectacularly under concurrency. Two writers attempting to update the same metadata file at the same time would lead to a "last write wins" scenario, corrupting the table.
- JDBC-Based Catalogs: Using a database to store metadata was an improvement, but it lacked a standard protocol for atomic commits, making it difficult for different engines to coordinate safely.
- Hive Metastore: The de facto standard, Hive Metastore provided a central server but lacked a crucial feature: an atomic operation to guarantee safe, concurrent commits, forcing it to rely on slow, coarse-grained locks.
A New Foundation: Open Table Formats
The solution to the data swamp required fixing the problem at the source: the table format itself. This led to the creation of open table formats like Apache Iceberg.
Enter Apache Iceberg
Iceberg guarantees ACID transactions for massive datasets by decoupling the logical table from the physical data files. It uses an immutable log of metadata files to track a table's state. Committing a change is a single, atomic operation: swapping a pointer from the old metadata file to the new one.
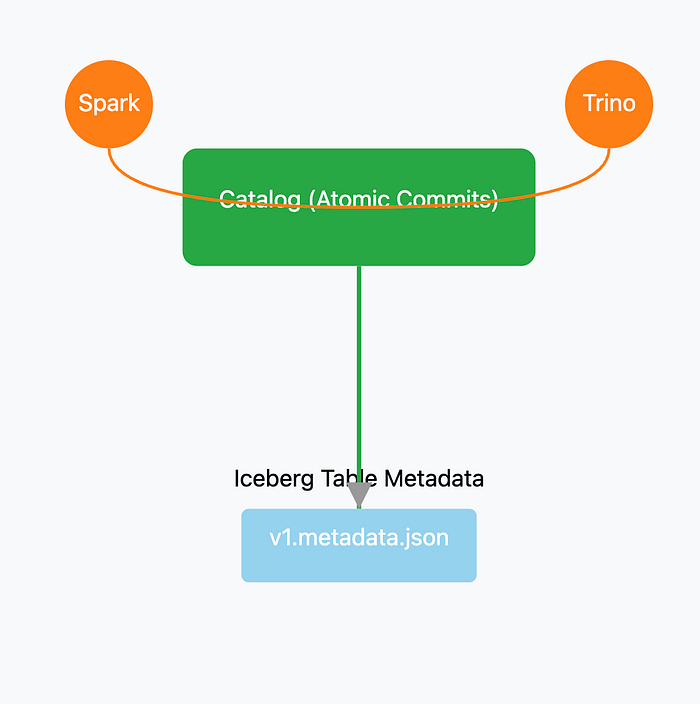
The Catalog's New Role: Transaction Manager
Iceberg's atomic swap operation requires a central, trusted arbiter to prevent conflicts when multiple engines try to write at the same time. This is where the data catalog evolved from a passive inventory into an active transaction manager.
The Source of Truth for Commits
For an Iceberg table, the catalog is the ultimate source of truth. It is responsible for executing the atomic "compare-and-swap" that makes concurrent, serializable transactions possible. Every query engine must consult the catalog to find the current, correct version of an Iceberg table, ensuring perfect consistency for all users.
The Evolutionary Path of Iceberg Catalogs
The need for a transactional catalog led to a rapid evolution, from adapting existing metastore implementations to building new, purpose-built solutions based on open standards.
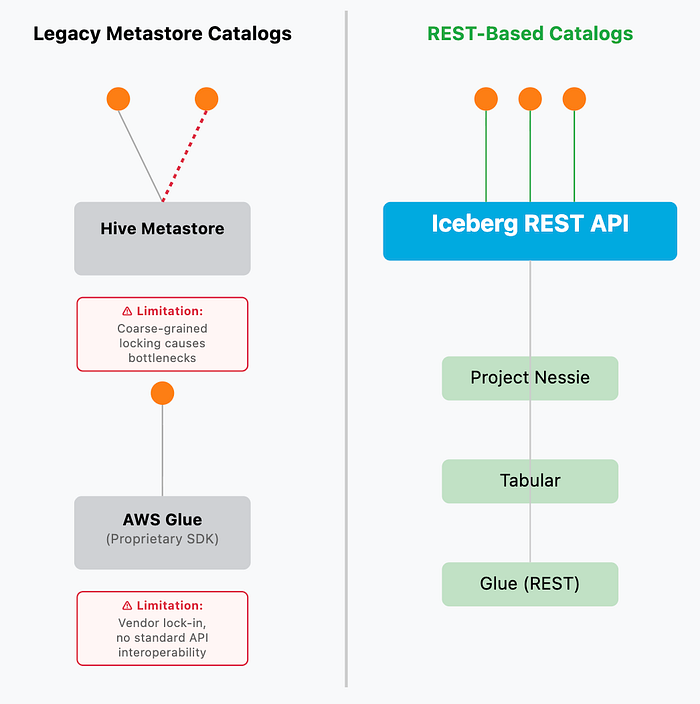
Phase 1: Legacy Metastore-Based Catalogs
Initially, the community used existing metastores not originally designed for Iceberg's optimistic concurrency model. This included the Hive Metastore, which created performance bottlenecks due to locking, and AWS Glue when accessed via its proprietary SDK.
Phase 2: REST-Based Catalog Implementations
The limitations of legacy metastore catalogs proved the need for solutions purpose-built for Iceberg. These REST-based catalogs are designed around the Iceberg REST Catalog Specification, an open standard that guarantees interoperability and performance. Examples include:
- Project Nessie: An open-source catalog that brings Git-like semantics (branching, merging) to data.
- Tabular: A commercial catalog service from Iceberg's original creators.
- AWS Glue (in REST mode): By implementing the REST Catalog Specification, Glue evolved from a legacy metastore catalog into a high-performance REST-based catalog, highlighting the industry's shift to open standards.
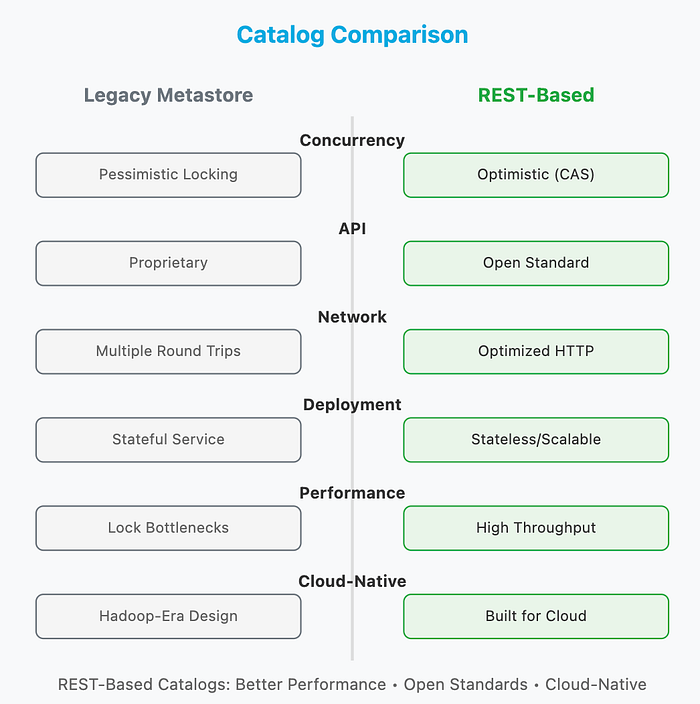
Key Differences: Legacy vs REST-Based Catalogs
Understanding the technical differences between legacy metastore-based catalogs and REST-based catalog implementations is crucial for making informed architectural decisions. These differences impact performance, scalability, and operational complexity.
1. Concurrency Model
Legacy (Hive Metastore): Uses pessimistic locking with coarse-grained table-level locks. When multiple writers attempt concurrent updates, they must wait for locks to be released, creating bottlenecks and reducing throughput in high-concurrency environments.
REST-Based: Implements optimistic concurrency control with atomic compare-and-swap operations. Multiple writers can work simultaneously, with conflicts resolved at commit time through version checking, enabling much higher write throughput.
2. API Standardization
Legacy: Each catalog implementation (Hive Metastore, JDBC, Hadoop) has its own proprietary API and client libraries. Query engines must implement separate connectors for each catalog type, increasing maintenance burden and limiting interoperability.
REST-Based: Follows the open Iceberg REST Catalog Specification, providing a standardized HTTP-based API. Any query engine implementing the spec can work with any compliant catalog, enabling true vendor neutrality and reducing integration complexity.
3. Network Efficiency
Legacy: Often requires multiple round trips for metadata operations. For example, Hive Metastore may need separate calls to acquire locks, read metadata, update metadata, and release locks, increasing latency especially in distributed environments.
REST-Based: Designed for efficient HTTP communication with batched operations and optimized request/response patterns. Single API calls can accomplish what previously required multiple round trips, reducing network overhead and improving performance.
4. Deployment & Operations
Legacy (Hive Metastore): Requires deploying and managing a separate Hive Metastore service with its own database backend (typically MySQL or PostgreSQL). This adds operational complexity, requires capacity planning, and creates an additional point of failure.
REST-Based: Can be deployed as lightweight, stateless services that scale horizontally. Many implementations leverage cloud-native architectures with managed backends (like DynamoDB or S3), reducing operational overhead and improving reliability.
5. Feature Support
Legacy: Limited to basic catalog operations (create, read, update, delete tables). Advanced features like multi-table transactions, catalog-level operations, or custom metadata are either unsupported or require proprietary extensions.
REST-Based: The specification includes support for advanced features like namespace management, multi-table transactions, view management, and extensible metadata. New capabilities can be added to the spec while maintaining backward compatibility.
6. Cloud-Native Design
Legacy: Designed for on-premises Hadoop environments with assumptions about network locality and persistent connections. May not perform optimally in cloud environments with ephemeral compute and object storage.
REST-Based: Built from the ground up for cloud-native architectures. Stateless design, HTTP-based communication, and integration with cloud services (IAM, object storage) make it naturally suited for modern cloud data platforms
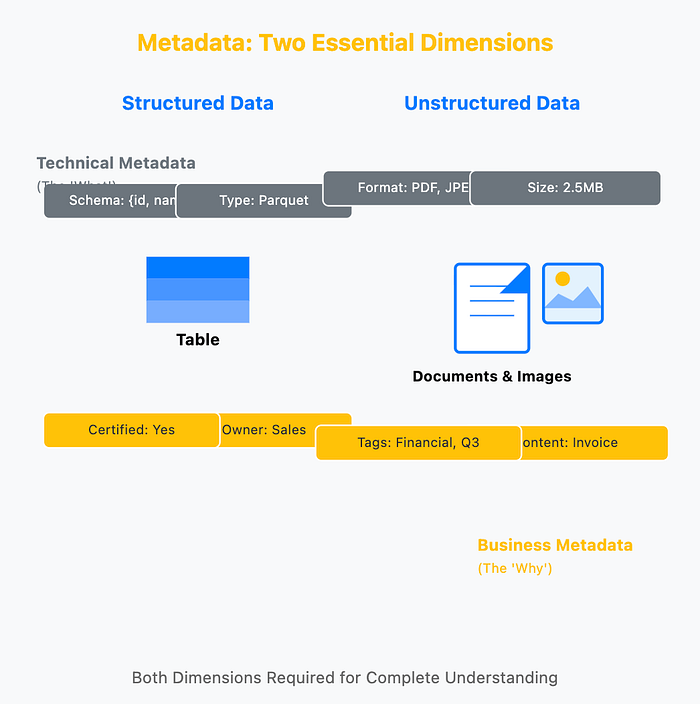
Metadata: The Foundation of Data Understanding
Before we can govern data effectively, we must understand it. This is where metadata becomes critical — the "data about your data." It translates cryptic technical details into meaningful business context. To truly understand a data asset, you need both sides of the coin.
Business Metadata (The "Why")
This provides context that makes data meaningful. Who owns this data? What business process does it support? Is it certified for financial reporting? What does "customer" mean in this context? This is the knowledge that turns raw data into a trusted asset that business users can confidently use.
Technical Metadata (The "What")
This describes the structure and characteristics. What is the schema? What data types are used? What format is the file? When was it last updated? Where is it stored? This is essential for actually using the data correctly and understanding its technical constraints.
Capturing Metadata for Structured Data
For structured data (databases, tables, data warehouses), technical metadata includes schemas, column names, data types, primary/foreign keys, indexes, and partitioning strategies. Business metadata adds descriptions, business glossary terms, data ownership, quality rules, and certification status. Together, they enable users to find the right table, understand what each column means, and trust the data quality.
Capturing Metadata for Unstructured Data
Unstructured data (documents, images, videos, logs) presents unique challenges. Technical metadata includes file format, size, creation date, storage location, and extracted features (for ML models). Business metadata adds content descriptions, tags, business context, sensitivity classifications (PII, confidential), and usage rights. Modern catalogs use AI to automatically extract and classify this metadata, making unstructured data discoverable and governable.
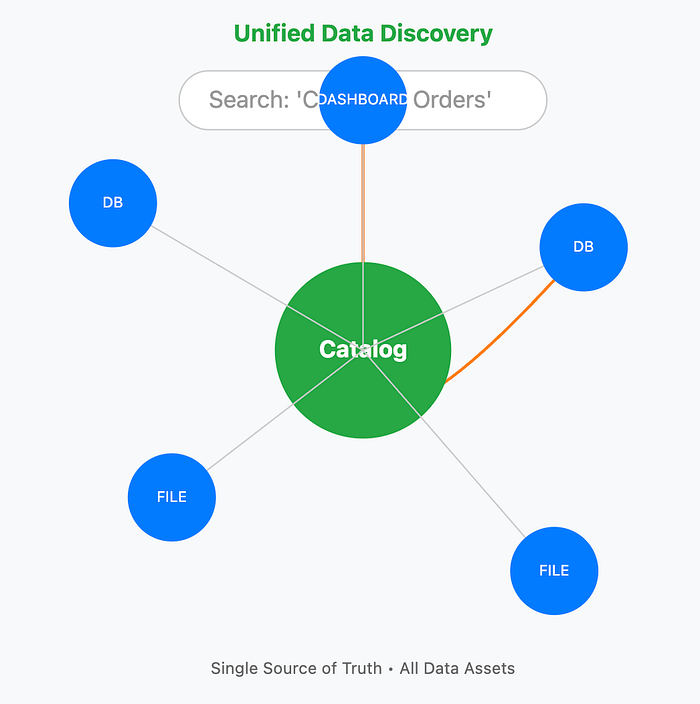
Unlocking Governance on a Trusted Foundation
With a reliable, transactional foundation provided by Iceberg and a modern catalog, it finally becomes possible to build the rich governance and discovery capabilities that users have always needed.
A True Search Engine for Data
A modern catalog provides a powerful, Google-like search experience, allowing users to discover data using business terms and see its quality, lineage, and security policies at a glance. It becomes the home for both technical and business metadata, turning raw data into a trusted, understandable asset.
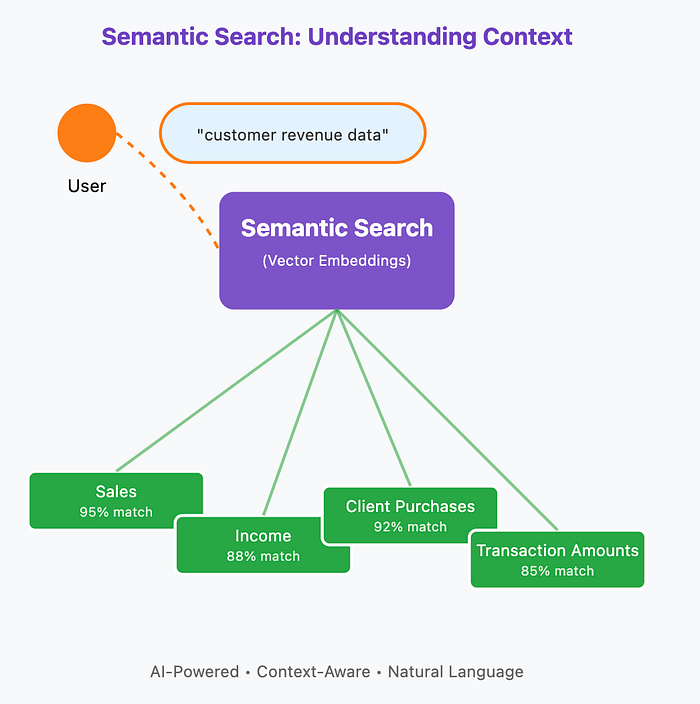
Beyond Keywords: Semantic Search Revolution
Traditional catalog search relies on exact keyword matches — you must know the precise table name or column to find what you need. Modern catalogs are evolving beyond this limitation by leveraging AI-powered semantic search that understands meaning and context, not just words.
How Semantic Search Works
Using large language models and vector embeddings, semantic search converts data descriptions, schemas, and business glossaries into mathematical representations that capture meaning. When you search for "customer revenue," it understands this relates to "sales," "income," "client purchases," and "transaction amounts" — even if those exact words don't appear in the metadata.
Natural Language Queries
Users can ask questions in plain English: "Show me tables with customer purchase history from last quarter" or "Find datasets about product returns." The catalog interprets intent, searches across all metadata dimensions, and ranks results by relevance — dramatically reducing time-to-insight and democratizing data access for non-technical users.
Contextual Recommendations
Semantic search enables intelligent recommendations. When viewing a sales table, the catalog can suggest related datasets like customer demographics, product catalogs, or marketing campaigns — connections that traditional keyword search would miss. This transforms discovery from a search problem into a guided exploration.
Ensuring Integrity with Lineage and Quality
Discovery is only the first step; trust is what truly matters. A modern catalog builds this trust through radical transparency.
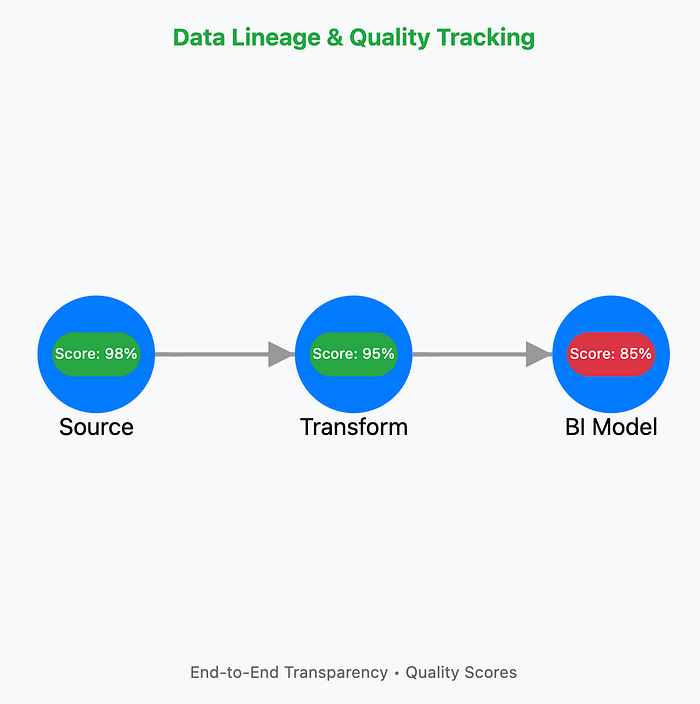
End-to-End Data Lineage
Lineage graphically maps the journey of data from its origin to its final use. This allows analysts to perform impact analysis, trace errors to their source, and understand exactly how key metrics were derived.
Integrated Data Quality
By displaying data quality scores directly within the catalog and on lineage graphs, users can immediately assess the reliability of data at each stage, ensuring they are building their analyses on a solid foundation.
Securing Data with Fine-Grained Access Control
A trusted data asset must also be a secure one. The data catalog evolves from a system of record into a central control plane for data security, moving governance from a reactive to a proactive process.
Policy-Driven Governance
Instead of managing permissions across hundreds of different systems, data owners can define access policies within the catalog based on roles or data sensitivity (e.g., PII). These policies are then automatically enforced across all query engines, ensuring users only see the data they are authorized to see.

Powering Modern Architectures and Optimizing Costs
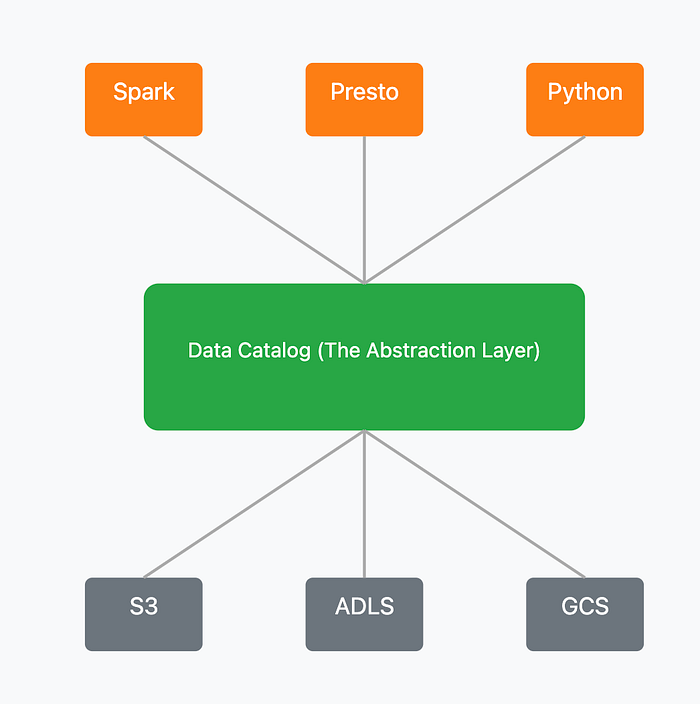
With a standard API and a catalog managing reliable tables, a powerful new architecture emerges. The catalog becomes the critical abstraction layer that decouples data storage from data processing, which is the key to flexibility and cost-efficiency.
Separation of Storage and Compute
By acting as the central metadata brain, the catalog allows you to store data in cost-effective object storage (like S3) and use the best-fit query engine (like Spark or Presto) for any given workload. This eliminates vendor lock-in and dramatically reduces compute costs.
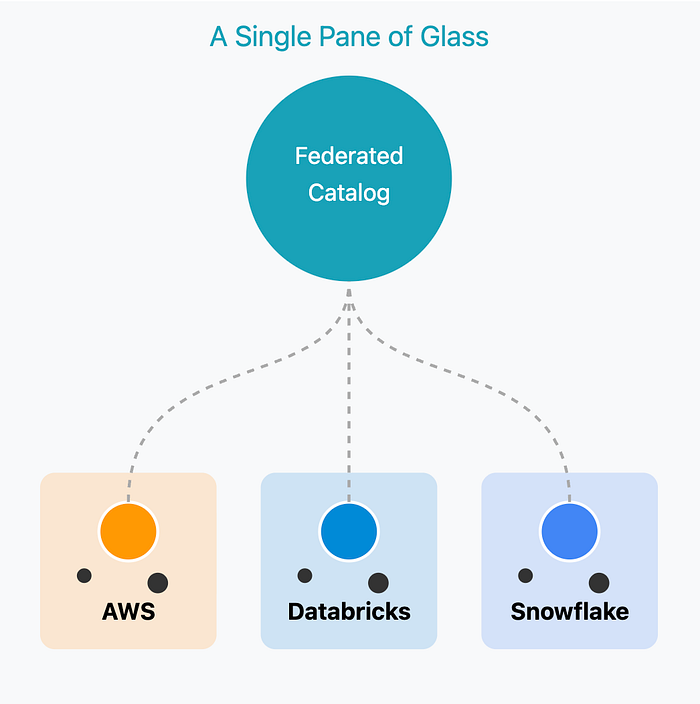
Unifying the Enterprise with Catalog Federation
The power of a standard API is that it allows different systems to connect. Large organizations inevitably have multiple platforms and clouds, often with their own catalogs. A modern catalog can leverage open standards to unify them.
A Single Pane of Glass
Advanced catalogs can connect to and unify these disparate catalogs using federation, creating a "single pane of glass" for the entire enterprise. This federated view provides a complete, holistic map of all data assets, achieving true enterprise-wide data governance and discovery.
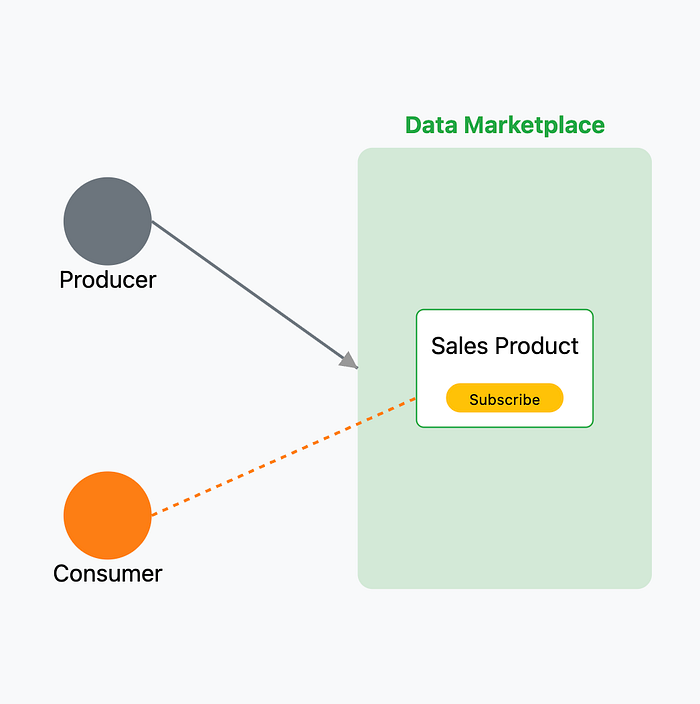
Enabling a Data Marketplace with Data Products
Once you have a unified, governed, and discoverable data landscape, you can change your mindset from simply managing data to delivering it. This leads to the concept of "Data Products" — curated, documented, and trustworthy assets packaged for a specific business purpose.
Publish-Subscribe Workflow
The catalog becomes a marketplace where producers can publish certified data products. Consumers can then browse this marketplace, understand the products through rich metadata, and subscribe to them. The catalog manages the entire workflow, fostering a scalable, self-service data culture.
Cataloging AI Models: The Next Frontier
As organizations deploy hundreds or thousands of machine learning models, they face a new challenge: model sprawl. Just as data became ungovernable without catalogs, AI models risk becoming a chaotic landscape of duplicates, outdated versions, and unknown dependencies. Modern catalogs are evolving to solve this by treating models as first-class assets.
Model Metadata and Lineage
Cataloging an AI model means capturing comprehensive metadata: the training datasets used, feature engineering pipelines, model architecture, hyperparameters, performance metrics (accuracy, F1 score, latency), and deployment environments. Critically, it includes full lineage — tracing from raw data through transformations to the final model, enabling reproducibility and impact analysis when upstream data changes.
Model Versioning and Governance
Models evolve through retraining and experimentation. The catalog tracks every version with its performance characteristics, making it easy to compare versions, roll back to previous iterations, or understand which model version is deployed in production. Governance policies ensure models meet fairness criteria, comply with regulations, and are approved before deployment.
Feature Store Integration
Modern catalogs integrate with feature stores to provide a unified view of the entire ML lifecycle. Data scientists can discover reusable features, understand which models consume which features, and trace data quality issues from model predictions back to source data. This creates a closed-loop system where data, features, and models are all discoverable, governed, and trustworthy.
Model Discovery and Reuse
Instead of rebuilding models from scratch, teams can search the catalog for existing models: "Find fraud detection models trained on transaction data with >95% accuracy." This promotes reuse, reduces redundant work, and accelerates time-to-production while maintaining quality standards.

Accelerating AI: The Catalog as a Brain for Agents
The ultimate consumer in a data marketplace is often an AI agent. However, AI operates on a "garbage in, garbage out" principle. Without context, it cannot find the right data, understand its meaning, or use it safely. The catalog provides this essential context.
How Catalogs Empower AI
The catalog acts as a trusted "brain" for AI. It allows an agent to discover available data, understand business terminology through glossaries, generate accurate queries from schemas, and automatically adhere to governance rules, transforming AI from a liability into a reliable, enterprise-grade asset.
Semantic Search for AI Agents
AI agents leverage semantic search to understand user intent and find relevant data without requiring exact technical knowledge. When a user asks "analyze customer churn," the agent uses semantic search to discover customer tables, subscription data, and usage metrics — then automatically generates queries using the catalog's schema information. This combination of semantic understanding and metadata-driven query generation makes AI agents truly autonomous and reliable.

The Path Forward: Catalogs as Strategic Assets
The evolution of data catalogs represents more than just technological progress — it reflects a fundamental shift in how organizations think about data. What began as a solution to the "data swamp" problem has matured into a comprehensive platform that addresses discovery, governance, quality, security, and AI enablement in a unified way.
Today's catalogs leverage open standards like Apache Iceberg and the REST Catalog API to provide transactional reliability, semantic search to enable natural language discovery, and comprehensive metadata management for both structured and unstructured data — including ML models. They've evolved from passive repositories into active participants in the data lifecycle, managing transactions, enforcing policies, and powering AI agents.
As organizations continue their digital transformation journeys, the data catalog has emerged as a strategic asset — not just a tool for data teams, but a platform that democratizes data access, accelerates AI adoption, and transforms data governance from a restrictive chore into a business enabler. The future belongs to organizations that recognize the catalog not as an afterthought, but as the foundation of their data strategy.