
The Slack message from my lead engineer landed at 4 PM my time (Berlin): "Have you seen this? Opus 4.6 just dropped."
I had. I was already in the middle of a Claude Code session — refactoring our authentication service, the kind of gnarly work that touches twelve files and three microservices si,multaneously. The timing was almost absurd. So I did what any engineer in my position would do: I switched models mid-session.

Quick note: AI helped me tighten the prose here. Everything I am sharing — the testing, the failures, the observations — that is all me.
What happened next surprised me. Not because Opus 4.6 is some magical leap that makes everything effortless — it's not. But because the improvements landed exactly where my daily workflow has friction. After spending the better part of 24 hours putting every major feature through real production work, I can tell you what genuinely changed, what's marketing, and what's too early to judge.
Everyone and their newsletter has published an Opus 4.6 announcement recap by now. I am not going to do that. Instead, here is what it actually feels like to use — from someone who is been building AI development systems with Claude Code for over 12 months.
The Effort Dial Changed How I Work
Here is the feature nobody is talking about, and it is the one that is going to save you the most money.
Opus 4.6 introduced adaptive thinking — the model now reads contextual cues and decides how much reasoning effort to invest. But the real power is the /effort parameter that gives you explicit control.
4 levels: low, medium, high, and max. Default is high (I had problem to use it. I guess because of the high volume of traffic and usage).
I ran the same task at each level: generating a service layer for a new API endpoint in our Node.js backend, including error handling, input validation, and database queries.
Here is what I found:
Low effort responded in about 3 seconds. The code was structurally correct but generic — boilerplate that would need significant editing. Fine for scaffolding, terrible for anything production-bound.
Medium effort took roughly 8 seconds. This is where it got interesting. The output was nearly identical to what Opus 4.5 produced at its default setting, but at noticeably lower token consumption. Anthropic claims medium matches prior performance at 76% fewer output tokens. From my testing, that tracks — my session costs dropped measurably when I stayed at medium for routine tasks.
High effort (the default and if it was working) took around 30 seconds. This is where Opus 4.6 pulls ahead of 4.5 (The model I still love). The code came back with edge cases handled that I didn't mention in my prompt — rate limiting considerations, graceful degradation for the database connection, even a comment flagging a potential race condition I hadn't thought about. Opus 4.5 would have given me correct code. Opus 4.6 gave me code that anticipated problems.
Max effort took over 40 seconds on the same task. Honestly? Overkill for a service layer. The model over-reasoned, exploring architectural alternatives I didn't ask for. But when I pointed it at a genuinely hard problem — debugging a concurrency issue in our message queue that had been open for two weeks — max effort traced the root cause in a single pass. Three senior engineers had spent a combined 18 hours on that bug.
The practical insight: I now toggle effort levels 10+ times per day. Low for boilerplate. Medium for routine code. High for anything production-bound. Max for the problems that have been sitting in the backlog because nobody wants to touch them. This alone changed my workflow more than any single feature in the past year.
What I am still figuring out: the boundary between high and max isn't always intuitive. Sometimes high is plenty. Sometimes max goes on a tangent. There's a learning curve to knowing when the extra reasoning helps versus when it burns tokens on overthinking.
1 Million Tokens Sounds Like Marketing. It's Not.
Yes, Gemini had a million-token context window first. But having a large context window and actually using it well are two very different things. I have learned this the hard way.
Here's the number that matters: on MRCR v2, a benchmark that tests whether a model can retrieve and reason about information buried deep in massive context, Opus 4.6 scores 76%. Sonnet 4.5 scored 18.5%. That is not a typo. It's a 4x improvement in the model's ability to actually use what you put in the window.
For the non-technical readers: imagine reading a 750,000-word document — roughly ten novels — and being able to answer specific questions about a paragraph on page 847 with the same accuracy as a paragraph on page 2. That is what this benchmark measures.
I tested this against our largest repository. Our authentication and authorization system spans 47 files with complex interdependencies — the exact kind of codebase that used to require me to carefully feed Claude files one at a time, hoping it would maintain context about the relationships between them.
With Opus 4.6, I loaded the entire directory structure in one shot and asked it to trace a permission bug from the API gateway through the middleware chain to the database query. It identified the issue in the third middleware layer — a stale cache of permission rules that wasn't invalidated on role changes. Previously, this kind of cross-file debugging required 12+ manual file references across multiple prompts.
But here is the honest caveat: 1M context is still in beta, and I hit the edges. Twice during my testing, the model's responses became noticeably less precise when I pushed past roughly 800K tokens. Not hallucinations — more like losing specificity, giving slightly more generic answers than the context warranted. It's better than anything else available, but it is not the "infinite perfect memory" some of the breathless coverage implies.
For my team of 7, the practical impact is clear: the 15-file modification threshold where I previously documented context accuracy dropping from 89% to roughly 60%? That threshold effectively does not exist anymore. That's the real story — not the headline number, but the ceiling it removes.
Agent Teams Are the Real Story (And the Real Risk)
Buried in the announcement — almost as a footnote — is Agent Teams in Claude Code. It is in research preview. It's rough. And it is the most significant feature in this release.
The concept: instead of one Claude Code agent working through tasks sequentially, you spin up a team of agents. One agent becomes the lead — it reads your intent, breaks the work into pieces, and delegates. The teammates pick up their assigned work, run independently with their own context windows, and coordinate with each other. The lead synthesizes everything at the end.
I tested this on a real task: building a new microservice with API endpoints, database migrations, test coverage, and documentation. Normally, this is a 3–4 hour Claude Code session where I am shepherding one agent through each phase sequentially.
With Agent Teams, I described the full scope to the lead agent. It spawned three teammates: one handling the API layer and routing, one building the database schema and migrations, and one writing tests. The lead coordinated the interfaces between them — making sure the test agent knew the API contracts the API agent was building.
Total time: roughly 90 minutes. And the coordination was genuinely impressive. The lead agent caught an inconsistency between the API agent's response schema and the test agent's assertions, flagged it, and directed the fix before I saw it.
Here's where it gets real, though.
The cost. Each teammate has its own context window. My three-teammate session consumed roughly 4x the tokens of an equivalent sequential session. For a complex task on Opus 4.6 at $5/$25 per million input/output tokens, that single 90-minute session cost approximately $12–15 in API usage. At our team's pace, running Agent Teams for every significant task would roughly triple our monthly Claude Code spend.
The coordination failures. In one of my tests, two teammates made conflicting assumptions about an environment variable name. The lead agent didn't catch it until both had completed their work, requiring a manual reconciliation that ate 20 minutes. It is the kind of bug a human tech lead would have caught in the planning phase
.
The research preview reality. This is beta software behaving like beta software. I had one session where a teammate agent silently stalled, and the lead waited for 8 minutes before I realized something was wrong. No error, no timeout — just a hung process.
My honest assessment: Agent Teams will be transformative when it matures. The parallel execution model is correct. The coordination protocol is promising. But today, I'd only use it for well-defined, parallelizable tasks — not the ambiguous, exploratory work where Claude Code shines brightest. For my team, I'm keeping it in my personal workflow for now, not rolling it out to all seven engineers until it stabilizes.
What Nobody's Talking About
Every Opus 4.6 article I have read in the past 24 hours shares one characteristic:
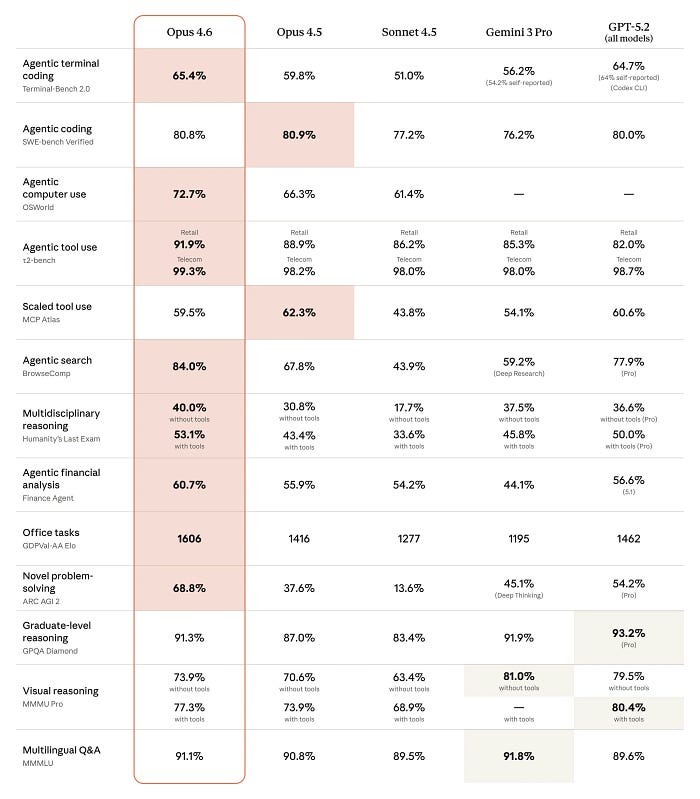
They skip the uncomfortable parts. Here is what the benchmarks don't tell you.
The SWE-bench regression is real. Opus 4.6 actually scores slightly lower on SWE-bench Verified than its predecessor. Anthropic hasn't explained why. It's a small dip, and the model dominates Terminal-Bench 2.0 (65.4%, the highest score ever recorded) — but SWE-bench tests something specific: resolving real GitHub issues. If your workflow is heavily issue-resolution focused, test before you commit.
MCP Atlas dipped too. There's a small regression on the MCP Atlas benchmark for tool usage. For anyone building MCP-heavy workflows — which is increasingly how production Claude Code setups operate — this matters. I haven't hit issues in my testing, but the benchmark exists for a reason.
128K output tokens + agent teams = budget surprise. Opus 4.6 can now output up to 128,000 tokens in a single response. Combine that with Agent Teams where each agent can produce lengthy outputs, and your bill scales faster than you'd expect. I burned through roughly 1 Mio. in tokens during my first full day of testing. That is fine for evaluation — less fine as a daily operating cost.
Context compaction is useful but lossy. The new context compaction feature (API/beta) lets Claude summarize earlier parts of a conversation to stay within context limits during long sessions. It works — I ran sessions that would have previously hit the wall at 200K. But compacted context isn't the same as full context. Twice I noticed the model losing specificity about early-session decisions after compaction kicked in. It is a reasonable tradeoff, but worth understanding what you're trading.
US-only inference pricing. If your compliance requirements mandate US-based inference, that's now available — at a 10% premium. For teams in regulated industries (healthcare, finance), this matters. For everyone else, it's an extra cost for no functional benefit.
The Bottom Line: Who Should Upgrade and When
After 24 hours of real testing across my daily workflow, here is my honest calibration:
Upgrade now if you're a Claude Code power user running complex, multi-file tasks daily. The effort dial alone is worth the switch — you will save money on routine tasks and get better results on hard problems. The 1M context window removes a real ceiling that's been limiting serious codebase work.
Wait 2–4 weeks if you're planning to rely on Agent Teams. It is promising but rough. Let the research preview mature before building workflows around it.
Wait for benchmarks if SWE-bench performance is critical to your use case. The regression is small but unexplained, and I'd want to see community testing confirm whether it's a benchmark artifact or a real capability shift.
Skip if you are primarily using Sonnet for cost efficiency. Opus 4.6 is still 10x the price of Sonnet 4.5. The capability gap is real but so is the cost gap. For many tasks, Sonnet remains the right tool.
You can also read the Anthropic Opus 4.6 System card (PDF)
The bigger picture:
Opus 4.6 isn't a revolution. It's something more useful — a meaningful upgrade that lands precisely where production workflows have friction.
The effort dial, the expanded context, the early agent coordination work. These are the building blocks of what AI-augmented development will look like in 12 months. The teams that start integrating these patterns now will have a significant head start.
I am still not sure Agent Teams will work for my full team anytime soon. But I am more confident than ever that the trajectory is right. And the effort dial? That is already permanent in my workflow. No going back.
What has been your first experience with Opus 4.6? I'm particularly curious whether others are seeing the same effort-level patterns. Drop your observations in the comments.
✨ Thanks for reading! If you'd like more practical insights on AI-augmented development, hit subscribe to stay updated.
About the Author
I'm Alireza Rezvani (Reza), CTO building AI development systems for engineering teams. I write about turning individual expertise into collective infrastructure through practical automation.
Connect: Website | LinkedIn Read more on Medium: Reza Rezvani