
"The greatest enemy of knowledge is not ignorance, it is the illusion of knowledge."
- Daniel J. Boorstin
Ever wonder why AI can "hallucinate" and confidently states facts that aren't true? Or at what point in training does it become "smart"? A new study by researchers from Google DeepMind and ETH Zürich helps answer these questions. In their paper "How do language models learn facts? Dynamics, curricula and hallucinations," Zucchet and colleagues use synthetic biographies in training to reveal that AI learns in three distinct phases — first absorbing general statistics, then hitting a plateau while building internal circuits, before finally acquiring specific factual knowledge. They also discovered that imbalanced training data (where some individuals appear more frequently) can accelerate learning and that hallucinations emerge simultaneously with knowledge acquisition, both develop from an internal representation of the world. These findings will impact how we train AI systems, improve their factual reliability, and figure out how to update them with new information — all important factors as these systems increasingly become our gateway to knowledge.

The Three Phases of AI Learning
It turns out that when AI models learn facts, they don't simply absorb information all at once. They follow a fascinating three-phase journey that researchers have now mapped out. In the first phase — the Statistical Foundation — the model learns general patterns in the data distribution. In our made-up biography example, it's not yet connecting specific names to specific facts, but rather understanding how often various attributes (like birthplaces or universities) appear across the entire dataset. This is similar to when a child first learns that people have birthdays before understanding when specific people's birthdays are. During this phase, the model builds a framework for understanding what types of information exist in its world.
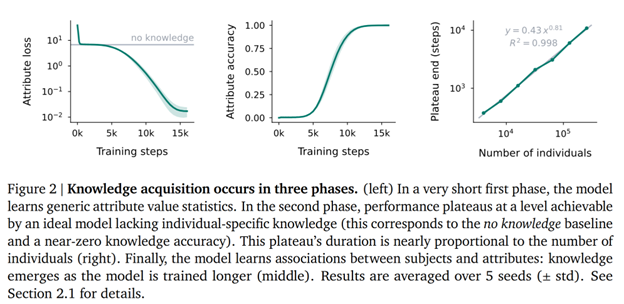
The second phase is perhaps the most interesting: the Plateau. Despite continuing to train on data, the model's performance remains flat, showing no visible improvement in factual recall. But appearances can be deceiving — beneath the surface, the model is developing attention-based circuits that will eventually enable recall. The researchers found that during this plateau, the model is creating internal mechanisms that connect names to their associated information. It's like watching a child who seems to make no progress for weeks while learning to read, only to suddenly demonstrate reading skills that were quietly developing all along. This plateau phase grows longer as the number of individuals in the training data increases; with more people to learn about, the model needs more time to build its recall circuits.
Finally comes the Knowledge Emergence phase, where the model's performance rapidly improves as it begins accurately connecting specific individuals with their attributes. The model can now reliably recall that James Frida Zhu was born in Shanghai or studied at Erasmus University. This last phase parallels the "aha moments" in human learning, when concepts suddenly click after a period of what looks like stagnation. The researchers' discovery of these distinct learning phases helps explain why AI models sometimes seem to make breakthrough improvements after periods of flat performance. Understanding these phases gives us insight not just into AI but potentially into human learning as well, where similar patterns of foundation-building, plateau, and breakthrough often occur when mastering complex skills from language to mathematics.
The Data Distribution Effect
One of the study's most important findings could be called the "celebrity effect" in AI training. When some individuals appear more frequently in the training data than others — creating an imbalanced distribution — the plateau phase shortens dramatically. The model can build its attention-based recall circuits more quickly by focusing on these "celebrity" examples that appear often. Rather than needing to see many different individuals a few times each, the model can learn the fundamental patterns of retrieval by seeing the same individuals repeatedly. The researchers found that an optimal training distribution isn't uniform as you'd expect, but instead follows a power law where some individuals appear much more frequently than others — especially during early training when these critical circuits are forming.

This insight will help us develop more efficient training regimens through what the researchers call "curriculum learning." Starting with a small subset of individuals and gradually expanding to the full population produces better results than training on everyone at once. In the researchers' experiments, this approach resulted in significantly more knowledge acquisition in the same amount of training time. More efficient training means less computing power required, which translates to lower costs and reduced environmental impact. Given that training large AI models can consume enormous amounts of energy, any technique that makes training more efficient contributes to more sustainable AI development. This research provides concrete evidence that how we distribute examples in training data matters just as much as the data itself.
The Hallucination Problem
Perhaps the most concerning discovery in this research is that hallucinations — confidently stated but incorrect facts — emerge simultaneously with accurate knowledge. As the model begins acquiring specific factual associations during the knowledge emergence phase, it also becomes increasingly confident in its predictions about individuals it has never seen before. Rather than expressing uncertainty about unknown people, the model makes up information with nearly the same confidence as its accurate recalls of information. The researchers found that while models are slightly less confident in their hallucinations than in their grounded predictions, this distinction is subtle — certainly not enough to rely on confidence scores alone to detect false information. The model has built an internal representation of the people in the dataset but has trouble distinguishing its overall confidence from confidence about any particular info. This phenomenon helps explain why even sophisticated AI systems often present fabricated information as if it were established fact.

The research also reveals why fine-tuning — the process of updating an AI model with new information — is so challenging. When researchers fine-tuned models on new individuals, they observed a rapid collapse in performance on previously learned information, with the model quickly forgetting what it knew before. This "catastrophic forgetting" occurred mainly in the feed-forward layers where associative memories are stored. Even techniques like replaying old data only partially fixed the problem. This issue creates a significant dilemma for AI reliability: systems trained on static datasets struggle to incorporate new knowledge without corrupting existing information. In real-world applications like medicine or law, where facts change as new discoveries are made or new precedents are established, this limitation poses serious challenges for keeping AI systems trustworthy and up-to-date. It is important to develop better methods for incrementally updating AI knowledge without sacrificing previously learned information. Having to fully bake each model before being useful will continue to be a significant issue until this issue is resolved.
What This Means for the Future
This research could reshape how we develop the next generation of AI systems. Rather than treating all training data equally, future models might employ a carefully designed curricula that strategically manipulates data distribution. It might start with concentrated exposure to a smaller set of entities before broadening to more diverse examples. This approach could significantly reduce computational requirements for training while improving factual reliability. The findings also suggest that we may need to rethink fine-tuning approaches entirely, perhaps designing modular architectures where new knowledge can be added without disrupting existing information. Some researchers are already exploring "neural editing" techniques that can modify specific memories without wholesale retraining, while others are investigating external memory mechanisms that could store factual information separately from the model's internal parameters, allowing for easier updates.

Understanding these learning dynamics is important for creating trustworthy AI systems that can reliably serve as interfaces to human knowledge. If we don't address the hallucination problem or develop better approaches to knowledge updating, AI systems will give us outdated information and confidently assert falsehoods even as our collective understanding evolves. These issues will prevent truly widespread adoption. Many questions still remain unanswered, however. We don't fully understand how hallucinations emerge alongside accurate knowledge or whether this phenomenon can be mitigated through architectural changes. It's also unclear how these dynamics scale to the massive models powering today's AI assistants or whether similar patterns appear when learning different types of knowledge beyond biographical facts. Researchers may need to mirror how human brains acquire and update factual knowledge — potentially offering insights that bridge artificial intelligence and cognitive neuroscience.
Conclusion
This research on how language models learn facts gives us important insights into the inner workings of today's AI systems. We now understand that factual learning follows three distinct phases, that data distribution significantly impacts learning efficiency, and that hallucinations emerge alongside knowledge while fine-tuning often causes catastrophic forgetting. This research provides a roadmap for developing more efficient, reliable, and updatable AI systems. As we increasingly rely on AI as a gateway to information, we need to understand how to build systems that serve human needs without amplifying misinformation. By revealing both the promise and limitations of how machines learn facts, this research helps us plot a course toward AI systems that can truly augment human knowledge rather than simply mimic it with all its limitations and flaws.