
Snowflake, the data cloud company, has released a new model named Arctic that has the enterprise community paying attention for various reasons.
It's a 480B model that yields impressive performance in what they call 'Enterprise Intelligence' (it's okay if you cringe, I did too).
Jokes aside, the truth is that the model is freakishly good in some aspects, and was trained with a budget under $2 million, signifying how good AI engineers are getting at building powerful LLMs.
Also, it's highly reminiscent of one of the most exciting architectures I've seen recently, hyper-specialized MoEs.
You are probably sick of AI newsletters talking about how this or that **just** happened. And these newsletters abound because coarsely talking about events and things that already took place is easy, but the value provided is limited and the hype exaggerated.
However, newsletters talking about what will happen are a rare sight. If you're into easy-to-understand insights looking into the future of AI before anyone else does, TheTechOasis newsletter might be perfect for you.
🏝️🏝️ Subscribe today below:
Cringe, but Awesome
'Enterprise Intelligence' is nothing but a non-weighted average of model results over a combination of 'enterprise-relevant' benchmarks for coding, SQL generation, and instruction following.
In layman's terms, this metric tells us that the model is good at these three things, probably the best if we focus on sup-70-billion-parameter models.
Of course, the benchmarks were cherrypicked (as they always are) but they nevertheless paint a pretty damn good picture for the model.
However, with 480 billion parameters, it's still huge.
That beast alone occupies at the very least 6 state-of-the-art NVIDIA H100s (80GB of HBM each), and that's without considering the KV Cache, the LLMs cache to avoid unnecessary recomputations, which is the biggest limiting memory factor when considering large sequences.
Of course, you can also try and perform partial loads to HBM, as this has been done in academia in cases like Apple, or using LoRA adapters like Predibase (although the latter doesn't really break up the model, it's just loading different fine-tuned versions of the same model into the GPU).
However, a question has to be made on the impact of such variations to latency.
But here's the most exciting thing about this model: It's a deep-mixture-of-experts with 128 experts and one global expert, which paints a completely different reality at inference.
Going Deep into Experts
If you're in for a more in-depth explanation, this architecture is very similar to DeepSeek-MoE's approach you can review here.
In standard Mixture-of-Experts, you divide the network, surprise surprise, into experts. Specifically, for any given prediction the model needs to perform (basically predicting the next word) a router chooses a fixed set of experts to be activated.
In more technical terms, we recall that LLMs are simply a concatenation of Transformer blocks, each having the architecture below, where Attention computes the famous attention mechanism to process the input sequence the model receives, RMS Norm stabilizes the model, and the MLP layer, known as Feedforward layer (FFN) allows the modeling of more complex statistical distributions in language, aka helps the model find more complex patterns in data.
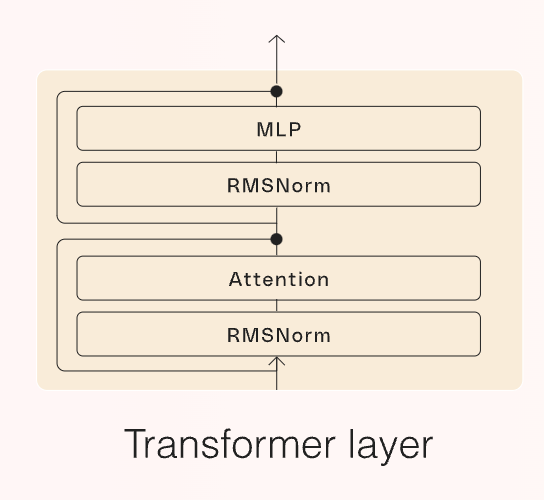
Regarding the latter, due to the amount of hidden units (neurons) they have, they represent the majority of the compute requirements of the model.
Thus, in Mixture-of-Experts, these FFN layers are broken down into identical parts, known as experts, with a softmax gate in front, as below.
Without getting into the detail I provided in the previous link, the gate will rank these experts for every input, choosing the top k preferred for that job.
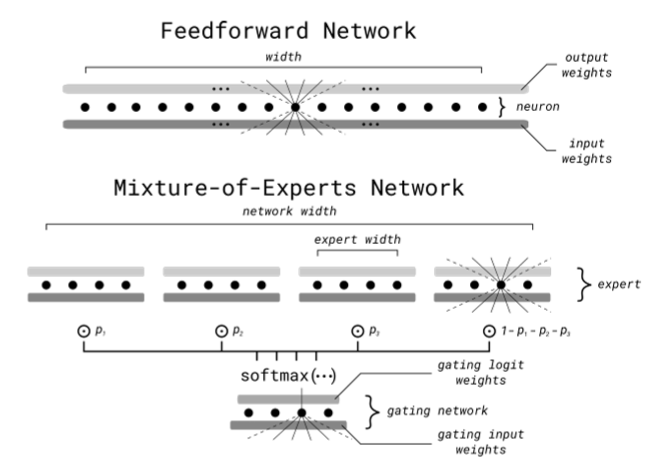
Intuitively, what we are doing is forcing different parts of the network to specialize in specific topics. Thus, we are 'regionalizing' the input space in search of higher quality data compression (better neurons) from the different neurons of each expert and, importantly, fewer costs as a smaller fraction of the network runs for every prediction.
However, Arctic, just like DeepSeekMoE, takes an in-between approach. Specifically, it defines two expert classes:
- A 10 billion-parameter expert runs everytime
- The model includes 128, 3.66B-each additional experts, with the model choosing two for every prediction.
This leaves us with an architecture eerily similar to the one to the right below (with the one on the left being the standard MoE), where expert number 1 (the global expert, the larger one) runs every time, and 2 out of the 128 additional experts will be chosen to participate in the prediction.
Intuitively, the FFN layers are still broken down, but the router will always choose 'Expert 1' and two additional experts out of the remaining 128.
Compute-wise, while the model is indeed 480 billion parameters in size, only 17B, or 3.45% of the model's parameters, are active for a given prediction.
Hence, you have the prowess of a huge model, and the cost of a model is only 4% of its real size.
Please note that the reduction in costs and latency isn't exact, as MoEs only partition the feedforward layers (which account for the vast majority of FLOPs nonetheless) but the attention layers remain untouched.
Enterprise LLMs, Yet Another Option
Despite the cringy marketing stunt to the self-proclaimed king of 'enterprise intelligence', the truth is that Arctic seems like a very interesting option.
Additionally, it again proves how Mixture-of-Experts has become a basic component of most models today, in search for that 'sweet spot' between large models and sustainable inferences.
Good model, and affordable cost.
Also, it's worth mentioning the clear bet of companies like Snowflake or Cohere that, by acknowledging the obvious lack of performance of Generative AI at the enterprise level, are aiming to put an end to the underwhelming "journey-to-AI" it has been for companies until now, while the OpenAIs and Anthropics of our time build the next generation of models, hopefully not destroying humanity in the process (I'm just kidding, worry you not).
On a final note, if you have enjoyed this article, I share similar thoughts in a more comprehensive and simplified manner for free on my LinkedIn.
If preferable, you can connect with me through X.
Looking forward to connecting with you.