


|LLM|NEUROSCIENCE|BRAIN|ALIGNMENT|
If you talk to a man in a language he understands, that goes to his head. If you talk to him in his language, that goes to his heart. — Nelson Mandela
Deciphering how the brain works and how it processes language are among the main goals of neuroscience. Human language processing is supported in the human brain by the language network (LN), a set of left-lateralized frontotemporal regions in the brain. LN responds robustly and selectively to language input, and researchers have also sought to study it using large language models (LLMs). LLMs are trained to predict the next tokens in a sequence and appear to capture some of the aspects of the human response to language.
Given the intriguing similarities, some open questions remain:
- What drives brain alignment in untrained models?
- Is model-brain alignment related to formal (syntax, compositionality) or v competence (world knowledge, reasoning)?
- What explains this alignment: size or type of training?
This article discusses some recent articles that try to answer these questions.
Artificial intelligence is transforming our world, shaping how we live and work. Understanding how it works and its implications has never been more crucial. If you're looking for simple, clear explanations of complex AI topics, you're in the right place. Hit Follow or subscribe for free to stay updated with my latest stories and insights.
Prior work has shown that the internal representations of certain artificial neural networks resemble those in the brain. — source
In other words, previous studies have shown that there are similar patterns between how the brain processes language (activations in the brain= and how neural network patterns process language. These studies are usually conducted by observing activation patterns in the brain by functional MRI and observing activations in neural networks (especially LLMs).
First, we find that only 2% of supervised updates (epochs and images) are needed to achieve ~80% of the match to adult ventral stream. Second, by improving the random distribution of synaptic connectivity, we find that 54% of the brain match can already be achieved "at birth" (i.e. no training at all). Third, we find that, by training only ~5% of model synapses, we can still achieve nearly 80% of the match to the ventral stream. — source
Together, these findings show that the architectural biases imbued into convolutional networks allow many aspects of cortical visual representation to readily emerge even before synaptic connections have been tuned through experience. — source
Surprisingly, this alignment does not require much training but also few epochs. This would be explained by the choice of architecture (e.g., the inductive bias of convolutional networks mimics in part how humans process images). In other words, choosing a neural architecture suitable for the task would mimic the evolutionary process of animals whereby "at birth," an animal has the ability to be able to see, and this process improves through learning.
So the choice of architecture is important. For example, the chosen optimization function has a bias that impacts generalization capabilities.

This raises the question between how important is architecture and how important is training?
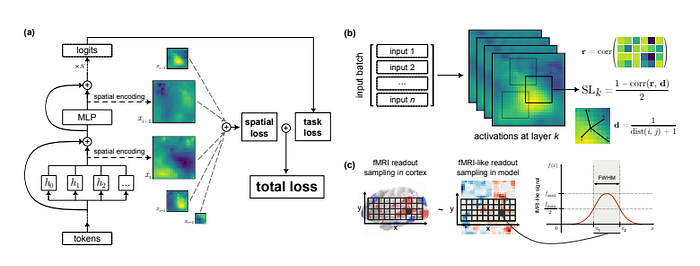
In this study, the authors use a series of neuroimaging datasets (people whose response to an auditory or visual stimulus is recorded) to be able to respond to images.
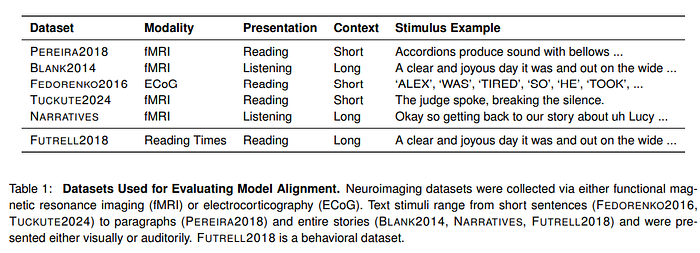
Alignment is usually achieved by predicting neural activity from the brain's internal representation, using the same linguistic cues provided to the human participant and the model. The authors in this work used models of different sizes (14M, 70M, 160M, 410M, 1B, 1.4B, 2.8B, 6.9B), also using the various checkpoints (from untrained to pre-trained model)
For an alignment to be meaningful, the model must be able to show different behavior for random tokens and for linguistic input. Models that are untrained (though much less than a trained model) still achieve relatively decent alignment and outperform models that are evaluated for alignment on random tokens.
But what is the cause of this surprising alignment?
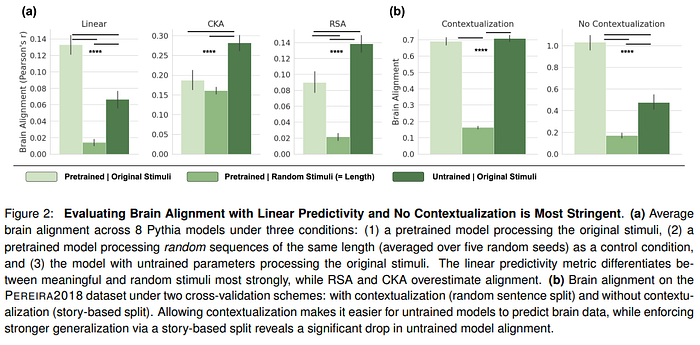
The authors try to investigate what factors might be. Results show:
- Models that are designed for sequences (GRU, LSTM, TRANSFORMERS) have higher brain alignment than models such as linear or MLP. In other words, the use of context and temporal integration has an impact on alignment. The use of static positional embeddings gives an advantage for alignment over rotary position encoding because it allows capturing intrinsic temporal dynamics in sentences.
- Through ablation, attention mechanisms and positional encoding turn out to be the most important components of the transformer for alignment.
- Alignment is driven by formal, rather than functional, linguistic competence. Linguistic competence pertains to the knowledge of linguistic rules and patterns, while functional linguistic competence involves using language to interpret and interact with the world. There is also an impact in the way the model is initialized.

Once the authors have identified why a untrained model is already partly brain-aligned, they investigate what happens during training. For this, they use a model such as Pythia, where different dimensions and checkpoints are available for each. Brain alignment is similar to the untrained model until approximately 128M tokens. Then there is a sharp increase (around 8B tokens) and then saturation for the remaining part of the training.
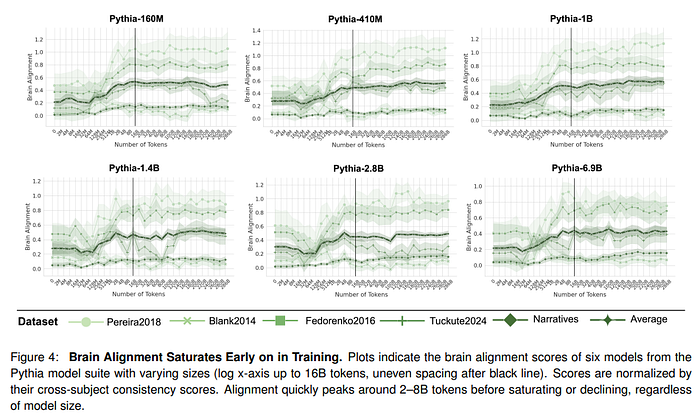
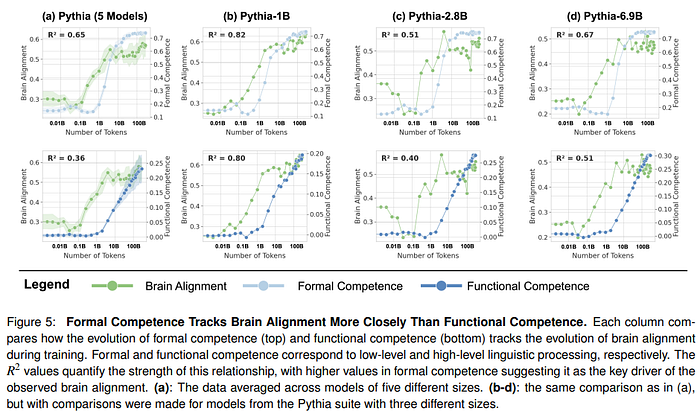
The authors investigate how both formal and functional linguistic competencies evolve during training. Interestingly, formal competence is most correlated with alignment
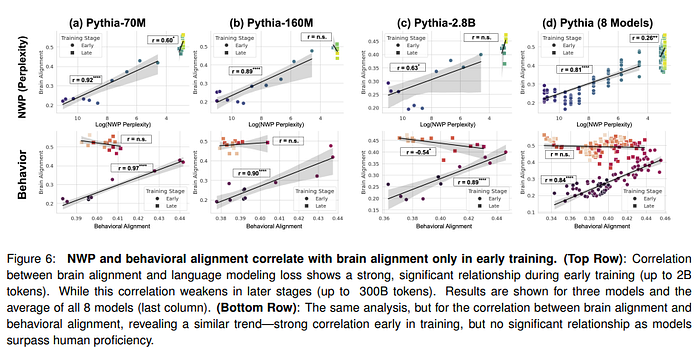
Humans process language predictively, with unexpected words taking longer to read. This behavior is reflected in LLMs during the initial period of training, but when they pass into proficiency, humans begin encoding statistical regularities that diverge from human intuition. At this time,e alignment also decreases, suggesting that more capable models rely on different mechanisms than those underlying human language comprehension. Results with alignment show that during early training, the model aligns with human-like processing, while language mechanisms diverge later
We demonstrated that alignment with the human language network (LN) primarily correlates with formal linguistic competence, peaking and saturating early in training. In contrast, functional linguistic competence, which involves world knowledge and reasoning, continues to grow beyond this stage. — source
In line with previous literature, this study shows that during the first phase of training, the model first learns language rules (such as grammar and syntax) and then later processes such as language competence and reasoning emerge. During the first phase of training, alignment between brain activity and the model begins, especially on formal linguistics, until it peaks and then saturates. Intriguingly, even models that are not trained show basic alignment. This is derived from architectural choices ( inductive biases, token integration mechanisms, and training dynamics). This also means that different choices may bring better alignment in the future.
On the other hand, during the later phase of training (especially for large models), a divergence between LLMs and human brain activity begins. When the model reaches a high level of proficiency in language, the model begins to encode different patterns than expected. On the one hand, this opens up intriguing prospects for developing architectures that may have better similarity to the human brain. On the other hand, it means that the models are not able to match the human brain's language processing capabilities fully.
What do you think? Let me know in the comments
If you have found this interesting:
You can look for my other articles, and you can also connect or reach me on LinkedIn. Check this repository, which contains weekly updated ML & AI news. I am open to collaborations and projects, and you can reach me on LinkedIn. You can also subscribe for free to get notified when I publish a new story.
Here is the link to my GitHub repository, where I am collecting code and many resources related to machine learning, artificial intelligence, and more.
or you may be interested in one of my recent articles:
Reference
Here is the list of the principal references I consulted to write this article, only the first name for an article is cited.
- Alkhamissi, 2025, From Language to Cognition: How LLMs Outgrow the Human Language Network, link
- Schrimpf, 2021, The neural architecture of language: Integrative modeling converges on predictive processing, link
- Rathi, 2024, TopoLM: brain-like spatio-functional organization in a topographic language model, link
- Tuckute, 2023, Driving and suppressing the human language network using large language models, link
- Geiger, 2020, Wiring Up Vision: Minimizing Supervised Synaptic Updates Needed to Produce a Primate Ventral Stream, link
- Kazemian, 2024, Convolutional architectures are cortex-aligned de novo, link
- Teney, 2024, Neural Redshift: Random Networks are not Random Functions, link