

Don't forget to get your copy of Designing Data Intensive Applications, the single most important book to read for system design interview prep!
Check out ByteByteGo's popular System Design Interview Course
Consider signing-up for paid Medium account to access our curated content for system design resources.
Introduction
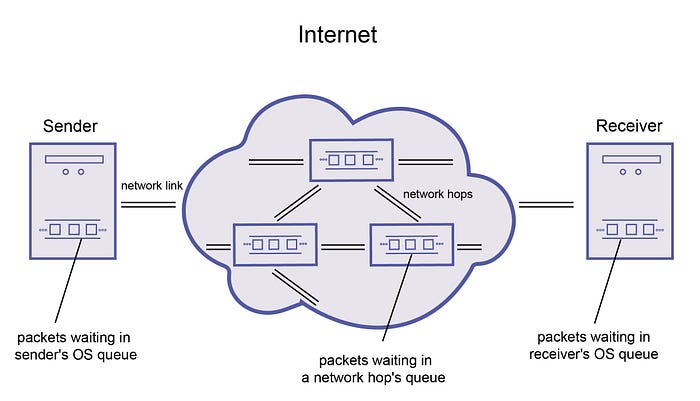
As discussed earlier, distributed systems run on commodity machines interconnected by an IP network, which is usually Ethernet. The network connecting the machines is an asynchronous packet network, which means that a sender can't determine the status of the sent packet other than when the sender receives a confirmation response from the receiver.
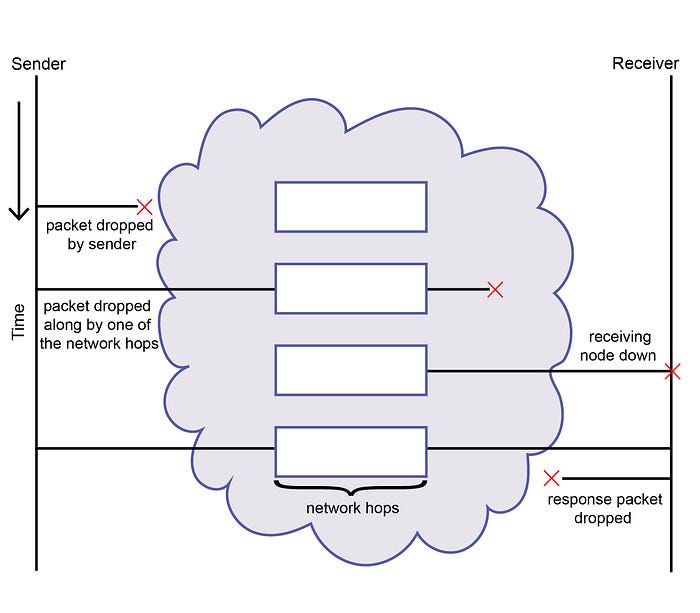
For instance, a packet sent may be in any of the following states:
- Packet is waiting in an OS queue on the sender's machine waiting to be sent out
- Packet is lost on its way to the recipient due to any variety of reasons such as network switches not working properly, physical cables being damaged, load-balancer failures, buggy software running on networking gear etc
- Packet is waiting in a queue at any one of the intermediate network hops connecting the sender and the receiver
- Packet has been received at the receiver but is waiting in an OS queue to be delivered to the receiving application
- Packet has been received and processed by the receiver application but the response packet has been lost
From a sender's perspective all of the above scenarios and many others like them are indistinguishable from a failed delivery. The sender can't determine if the packet was truly lost in transmission or that the packet is just experiencing a delay and will eventually be delivered to the recipient. Even if a packet is successfully delivered and processed, but the response from the recipient is lost, it is still counted as a failure from the sender's perspective. Note that if a TCP connection is used between the sender and the receiver, it is possible that the sender receives a TCP acknowledgement packet but that would still not imply that the receiver of the packet was able to process the sender's packet successfully. The receiving application may have received the packet and crashed while processing it. The only guaranteed way for the sender to receive a confirmation of successful delivery and processing is to receive an acknowledgement from the receiver at the application layer and not at any of the other OSI defined layers.
Detecting failures
Given this context a sender can only wait for a period of time that should take for the receiver to send back a success/acknowledgement response. If this time period elapses, also known as the timeout period, without a response from the receiver, then the sender assumes that its packet was lost and a retry should be attempted. Note that after the timeout period, the sender makes an assumption that the packet it sent was lost, however, it is very much possible that the packet still ends up being delivered to the recipient or that it may already have been delivered to the recipient.
Calculating timeouts is not an exact science and requires a delicate balance between being too short so as not to unnecessarily resend successfully transmitted messages and being too long so as not to unnecessarily wait an extended period of time before retrying. Asynchronous networks that are used by distributed systems for communication, promise message delivery as soon as possible but don't place an upper bound on the maximum delivery delay, which is unbounded. It may be tempting to keep a short timeout to detect failure early, but short timeouts can be double-edged swords. A node which suddenly experiences heavy traffic may be slow to respond, breaching the timeout threshold and leading other nodes in the system to declare the busy node dead. In some distributed systems, declaring a node dead may trigger other actions within the system such as leader election or moving data assigned to partition to other nodes in the system, all of which can be costly and a toll on performance. A system already under heavy load will see performance suffer further when one of the participant nodes is prematurely declared dead.
Failures with feedback
Network failures can be detected and addressed in a variety of ways. For instance, if the receiving application crashes, then there will be no process listening on the receiving port causing the OS to refuse connection. Sometimes, the OS can be set up to monitor a process on a node and incase of failure, the OS may run a script that notifies other participants in the system of the failure. Similarly if the recipient isn't reachable via the network, then the router may indicate a failure or the DNS may fail to resolve the hostname etc.
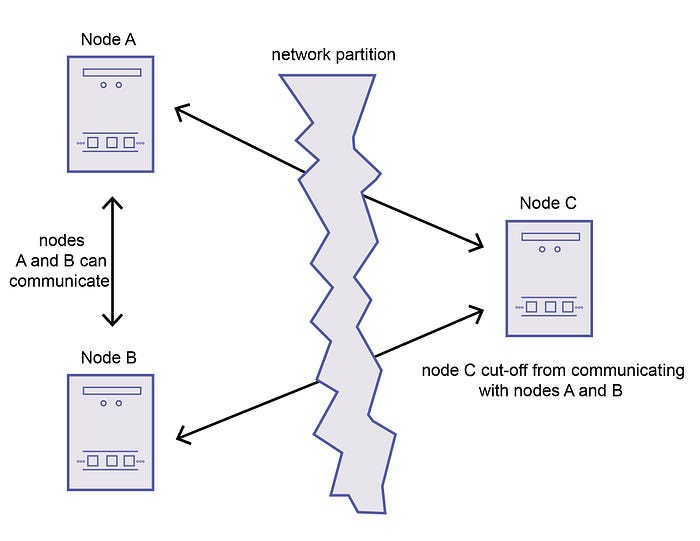
Network Partition
A network partition occurs when part of a network connecting nodes running a distributed service becomes disconnected from the rest of the network due to a network fault. There can be multiple network partitions in a network at the same time. A network partition prevents one component of a distributed service from communicating bidirectionally with the rest of the components in the distributed system, leading the other components to believe that the affected component has crashed or died. Software running on distributed systems should anticipate such situations and usually has logic built-in to recover from network partitions.
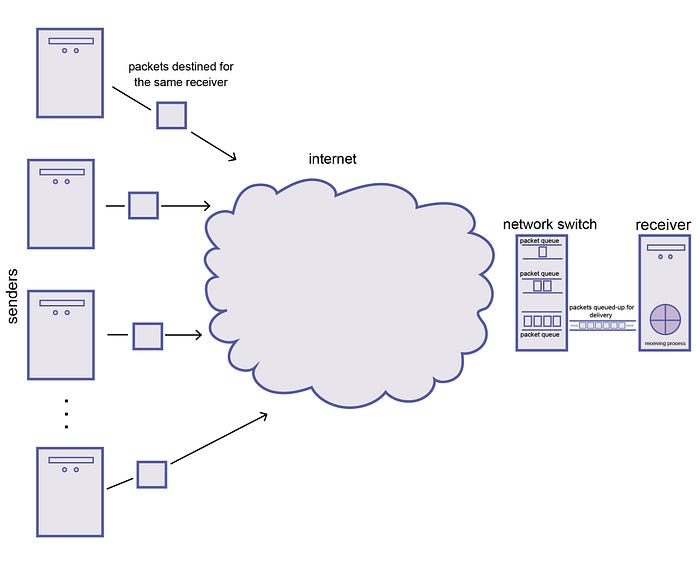
Network Congestion
We learnt that asynchronous networks don't guarantee delivery within a certain time period and one can expect unbounded delays when sending messages on such a network. The cause for delivery delays in asynchronous networks can be primarily attributed to network congestion and messages waiting in queues to be processed. Consider several nodes sending messages to the same receiver node at the same time. These packets will start to fill up the network switch queue until all of them are put out on the destination network link one by one. As messages fill-up the queue, eventually hitting queue capacity, they'll be dropped and the senders will have to send the messages again.
There can also be other reasons for delays, for example, if the receiving application runs in a VM while sharing hardware resources with other VMs, then the receiving application may have to wait for its turn to be assigned a CPU core and consume the waiting message destined for it. A receiving application may be experiencing a GC pause when a message for it arrives in the OS queue. Finally, the TCP protocol itself may be the culprit for delays as it may throttle sender's packets to avoid overwhelming the network link or the receiving application. Additionally, TCP also waits to receive an acknowledgment from the receiver and if none is received within a timeout period, the packets are sent again. The retransmission of packets is hidden from the application layer but the delay is nevertheless experienced by the application.

Congestion and queueing are a hallmark of packet-switched networks in contrast to circuit-switched networks. Placing a phone call takes over a circuit-switched network, where bandwidth is exclusively reserved across the entire route between the two persons. With reserved bandwidth the data traveling in either direction doesn't have to queue up at any of the hops. In packet-switched networks there's no reservation of bandwidth and the participants compete with each other over bandwidth when sending out packets. This allows maximum use of the network bandwidth, which supports bursty traffic very well but then experiences congestion, queueing and lost packets.
In summary, timeouts are determined experimentally and vary significantly depending on a host of variables. Some systems such as Cassandra dynamically determine the timeout by continually measuring the response time distribution.
Any network link has a given bandwidth and on an asynchronous network, the bandwidth is never reserved for a connection.
Your Comprehensive Interview Kit for Big Tech Jobs
0. Grokking the Machine Learning Interview This course helps you build that skill, and goes over some of the most popularly asked interview problems at big tech companies.
1. Grokking the System Design Interview Learn how to prepare for system design interviews and practice common system design interview questions.
2. Grokking Dynamic Programming Patterns for Coding Interviews Faster preparation for coding interviews.
3. Grokking the Advanced System Design Interview Learn system design through architectural review of real systems.
4. Grokking the Coding Interview: Patterns for Coding Questions Faster preparation for coding interviews.
5. Grokking the Object Oriented Design Interview Learn how to prepare for object oriented design interviews and practice common object oriented design interview questions
6. Machine Learning System Design