
Benchmarks are central in artificial intelligence research and in LLM development in general. Their purpose is to serve as neutral points of comparison between models, to structure competition dynamics, and to contribute to building a collective vision of progress. When a benchmark is released, it immediately influences how the community interprets progress in AI systems.
The MMLU (Massive Multitask Language Understanding) benchmark will be a good example in our article through its structuring role. This benchmark was introduced to evaluate models across a vast range of 57 subjects, spanning STEM, the humanities, and social sciences. It is a demanding and informative benchmark, precisely because it deviated from basic language understanding to focus on specialized knowledge across diverse domains.
Why new benchmarks matter
When a benchmark is introduced, it is, by definition, unsaturated. No model has seen it neither directly nor indirectly. Therefore, the observed performances give a valuable signal on real capacities of the tested systems.
It was the case of MMLU at its launch. The huge gaps between human and models' performances were interpreted as a credible indicator of the limits of artificial reasoning. The benchmark fully fulfilled its role as a measurement tool.
A familiar trajectory: analysis, adaptation, and saturation
Though, through time, this known dynamic gets installed. Benchmarks are then analysed, broken down and reused. The tasks are categorised, the patterns identified and architectures or pipelines are progressively adapted to their specificities.
This phenomenon is mostly positive : it reflects a collective progression of the understanding of the proposed problems. However, it also has a structural side effect. As models and methods get adapted, scores end up reflecting a certain familiarity with the benchmark itself rather than the general capacity it was initially meant to measure…
Here again, MMLU illustrates this dynamic. Over the years, specific prompting strategies appeared, dedicated fine-tuning methods have been developed and the benchmark has largely been used in every major LLM release announcement.
When familiarity becomes exposure
In some cases, this familiarity is going further and turns into a contamination of the evaluation dataset. Examples of the benchmark (or very similar) can be found incorporated inside training datasets of several models (it can be by crawler web ingestion, creation of derivative datasets or through repeated public exposure).
At this point, this leads to a natural question: Is a good score really reflecting a better general capacity, or only a past exposure to the test?
MMLU is not an isolated case, but it makes this issue particularly visible given its massive presence in training corpora.
Nevertheless, this design improvement is not solving everything. That is, a well designed benchmark stays vulnerable if its usage is not restrained.
At its core: trust and data leakage
We can then reformulate the main problematic simply : How to compare models without ever revealing to the model the evaluation dataset ?
This question highlights a trust issue between the different involved stakeholders, the benchmarks' designers, the models' owners and the competitions' organisers. The background of MMLU, largely used in public leaderboards, illustrated the difficulty to ensure the absence of data leakage of evaluation dataset in an open ecosystem.
Private benchmarking as a shift in perspective
It is in this context that the idea of private benchmarking arises. The perspective shift is fundamental, the evaluation is no longer seen as a simple shared data but as a secure computation task.
The core idea is simple :
- The evaluation dataset must be never revealed to the model,
- The model can stay secret,
- And only the final metric is published.
The work made in the TRUCE article shows that this approach can be implemented on different levels of trust granted to the stakeholders.
A spectrum of solutions, from the most simple to the safest
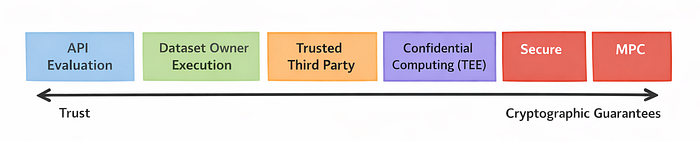
The first option consists in evaluating models from their API. This solution is simple, low-cost but relies on a strong assumption : we have to trust the model's owner to not exploit the evaluation dataset.
If a model is open-source ou locally executable, the evaluation can be moved to the benchmark's owner. Then, the dataset stays in its infrastructure but the trust is totally on the designer of the benchmark.
A third option is based on a trusted third-party validated by all stakeholders, who execute the evaluation with limited contracts. This approach separates responsibilities but need an actual trust on a human entity.
To reduce this dependence, the confidential computing introduces secure hardware enclaves (TEE) in which the model and the dataset are encrypted. It is only readable inside the enclave. Contrary to popular belief, these solutions are nowadays practically feasible, including large models with a limited extra cost.
Finally, sometimes requirements are maximal, namely, that no party should learn anything beyond the final result. In those cases, cryptographic approaches such as Secure Multi-Party Computation provide formal guarantees, at the cost of higher latency and communication overhead.
What MMLU teaches us about evaluation
Public benchmarks have played a major role in AI progress. The observation of their evolution however shows that their public release raises structural problems as models became more capable.
The example of MMLU illustrated a clear trajectory. While improvements in benchmark design are important (such as the recent MMLU-Pro), they may by themselves fall short. To further support the reliability of evaluation, these improvements can be complemented by private benchmarking mechanisms and secure computation methods, where appropriate.
The challenge is not to make evaluation dark but to preserve what it is meant to measure, the real general capacities and not simple exposure to tests.
Sources
- MMLU Original Paper Measuring Massive Multitask Language Understanding Dan Hendrycks et al., 2020 arXiv:2009.03300
- TRUCE paper TRUCE: Trustworthy and Robust Uncontaminated Evaluation → private benchmarking, trust models, secure computation
- MMLU-Pro (Example of design improvement) MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark Wang et al., 2024