
Why GPU scheduling has become the most expensive problem nobody's talking about
The AI industry has a dirty secret: while everyone obsesses over model architectures and training techniques, billions of dollars in GPU compute sits idle due to catastrophically bad scheduling.
This isn't a theoretical problem. It's happening right now at companies with names you'd recognize, and it's getting worse as models scale.
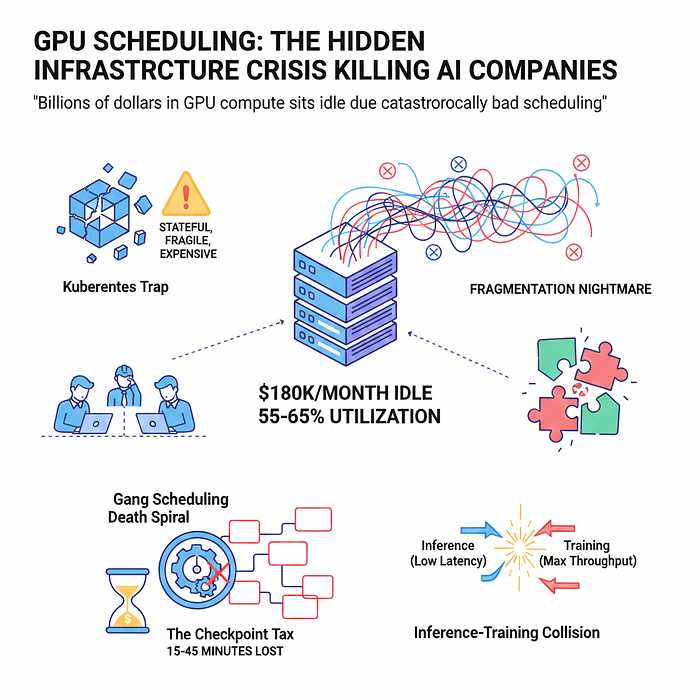
The $180K/Month Paperweight
Picture a cluster of 64 H100 GPUs — roughly $180,000 per month in cloud costs. Industry surveys show these clusters typically run at 55–65% utilization. That means nearly half the hardware sits idle while engineers wait days for resources.
The math is brutal. A company with a modest 100-GPU cluster running at 60% utilization is effectively throwing away $1.4M annually. Scale that to the GPU farms at major AI labs, and the waste reaches hundreds of millions.
But low utilization is just a symptom. The real disease runs deeper.
The Gang Scheduling Death Spiral
Modern AI training relies on distributed computing across multiple GPUs running in perfect synchronization. This creates a brutal constraint: you need all GPUs available simultaneously, or you get nothing.
Consider a training job requiring 32 GPUs. The scheduler finds 28 available immediately, then waits for the remaining 4. Those 28 GPUs burn money doing nothing. Hours pass. When the 29th GPU finally frees up, the 30th goes offline for maintenance. Back to square one.
This isn't an edge case. It's Tuesday.
The problem compounds with scale. Distributed training across 128+ GPUs means any single failure — a network hiccup, a memory error, a cosmic ray — can crash the entire job. Without sophisticated checkpointing, days of compute evaporate instantly.
The Kubernetes Trap
Most AI infrastructure teams make a fatal mistake: treating GPU workloads like regular containers.
They deploy Kubernetes with standard schedulers and quickly discover the mismatch. Kubernetes was designed for stateless web services that scale horizontally, fail gracefully, and recover quickly. AI training jobs are the opposite: stateful, fragile, and expensive to restart.
The default Kubernetes scheduler has no concept of:
- GPU topology and interconnect speed
- Checkpoint costs for preemption
- Job priority based on deadline urgency
- Gang scheduling requirements
- Fair sharing across teams with vastly different workload patterns
Teams spend months building custom operators and schedulers on top of Kubernetes, essentially recreating a GPU-aware batch system from scratch. Many abandon Kubernetes entirely after burning six figures on wasted engineer time.
The Fragmentation Nightmare
GPU allocation isn't like CPU allocation. CPUs can be sliced into tiny units. GPUs are chunky, indivisible resources with complex dependencies.
Training jobs arrive with specific requirements: "I need exactly 8 GPUs with NVLink, preferably on the same physical node, definitely in the same availability zone." The scheduler looks at the cluster: 2 GPUs free here, 3 there, 4 somewhere else. Perfect total, impossible to allocate.
This fragmentation gets worse throughout the day. As jobs complete and new ones start, the cluster becomes a jigsaw puzzle where pieces don't fit. Eventually, multiple GPUs sit unused because no pending job matches the available configuration.
The standard solution — wait for better opportunities — means accepting permanent inefficiency. The aggressive solution — preempt running jobs to defragment — means checkpoint overhead that can exceed 30 minutes for large models.
The Inference-Training Collision
Production AI companies face a unique scheduling nightmare: training and inference workloads compete for the same hardware.
Inference serving demands low latency and consistent throughput. Training tolerates latency but needs maximum throughput. These requirements are fundamentally incompatible.
During business hours, inference traffic spikes. Training jobs get throttled or preempted. At night, inference quiets down, but the training jobs that should backfill are stuck in queue behind the scheduling decisions made at 2 PM.
Some companies solve this by maintaining separate clusters. This "solves" scheduling at the cost of 40% higher infrastructure spend and underutilized capacity when workload patterns shift.
The Checkpoint Tax
Every preemption decision carries a hidden cost: checkpointing overhead.
Modern large models checkpoint hundreds of gigabytes of state. Saving to storage takes 15–45 minutes. Restoring takes another 15–45 minutes. For a job that gets preempted twice during a 24-hour run, that's 2 hours of pure overhead — 8% efficiency loss right off the top.
Schedulers that ignore checkpoint costs make objectively wrong decisions. Preempting a job that's 90% complete to free resources for a new job wastes more compute than letting it finish. But without checkpoint-aware scheduling, these inefficiencies are invisible.
The problem scales non-linearly. As models grow larger and training runs extend to weeks, checkpoint overhead becomes prohibitive. Some teams simply disable preemption, accepting fragmentation rather than paying the checkpoint tax.
The AI-Native Reckoning
Traditional HPC schedulers like Slurm don't understand modern AI workloads. Kubernetes doesn't understand batch semantics or GPU topology. Cloud-native solutions assume elastic, fungible resources — the opposite of GPU reality.
The industry needs AI-native scheduling built around these principles:
Gang scheduling as a first-class primitive, not an afterthought. The scheduler must understand that 8 GPUs allocated together are fundamentally different from 8 GPUs scattered across the cluster.
Topology awareness at every layer. NVLink speed, PCIe topology, network fabric — these aren't minor optimizations, they're 10x performance differences. The scheduler must optimize placement accordingly.
Checkpoint-aware preemption. Every scheduling decision must account for the cost of saving and restoring state. Sometimes the right answer is "don't preempt."
Multi-objective optimization. Maximize utilization AND minimize queue time AND respect priorities AND maintain fairness. These goals conflict, requiring sophisticated policy engines.
Inference-training co-scheduling. Rather than segregating workloads, dynamically share resources based on real-time demand patterns with millisecond-level responsiveness.
The Companies Solving This
A new generation of infrastructure tools is emerging specifically for AI workloads:
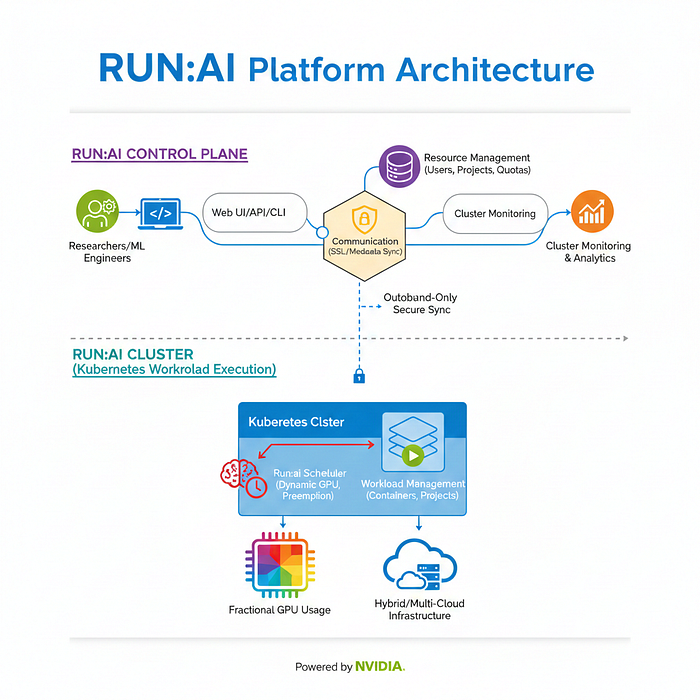
Run:ai pioneered fractional GPU sharing and dynamic allocation, allowing inference and training to coexist efficiently.
SkyPilot and Modal abstract away cluster management entirely, automatically finding and provisioning the cheapest GPU resources across clouds.
Anyscale (built on Ray) handles distributed training orchestration with sophisticated gang scheduling and fault tolerance.
Determined AI treats checkpointing as a first-class concept, enabling aggressive preemption without waste.
These aren't incremental improvements on Kubernetes. They're ground-up reimaginations of what GPU scheduling should look like.
The Economics of Better Scheduling
The potential savings are staggering. Improving GPU utilization from 60% to 85% on a 100-GPU H100 cluster saves $1.8M annually. At enterprise scale with 1,000+ GPUs, the savings reach eight figures.
But the real cost isn't just wasted compute — it's wasted time. Engineers waiting days for GPU access can't iterate quickly. Research velocity drops. Competitive advantage erodes.
The companies winning the AI race aren't necessarily those with the most GPUs. They're the ones whose GPUs are actually working.
What This Means for You
If you're building AI infrastructure, assume your GPU scheduling is broken until proven otherwise. Measure actual utilization, not theoretical capacity. Track queue wait times. Calculate the cost per training run including all the failed attempts and restarts.
If you're considering Kubernetes for GPU workloads, understand you're signing up for months of custom development. The ecosystem is maturing, but the gap between "works for demos" and "works at scale" remains enormous.
If you're evaluating vendors, ask specifically about gang scheduling, checkpoint costs, and topology awareness. Most solutions handle the easy cases but break under real-world complexity.
The infrastructure layer of AI is still being built. GPU scheduling is one of those rare problems where better solutions can unlock billions in efficiency gains.
The question is whether companies will recognize this before their $2M GPU cluster becomes a very expensive paperweight.
The GPU scheduling problem represents a fascinating inflection point: as AI workloads become the dominant computing paradigm, infrastructure built for the web-service era increasingly shows its limitations. The next generation of cloud infrastructure will look nothing like what came before — and GPU scheduling is where that future is being built today.