
When you feed text into a Large Language Model, something magical (and mathematical) happens before the model ever sees it: tokenization. But this process, and the formats we use to structure data, directly impact your API costs, processing speed, and even model accuracy. Let me break down how tokenization works and why TOON is quietly revolutionizing how we feed structured data to LLMs.
What Is Tokenization? The Bridge Between Text and Numbers
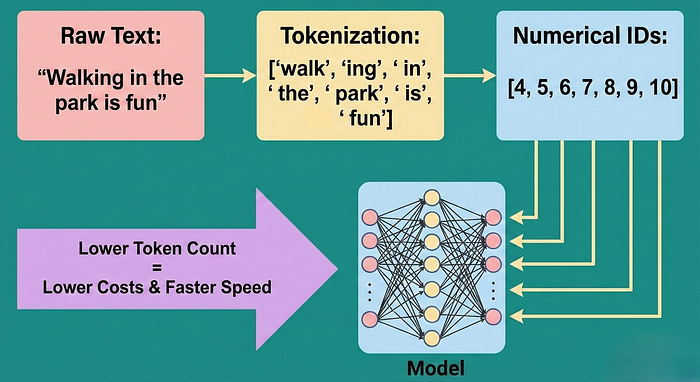
Tokenization is the process of converting raw text into smaller, meaningful pieces called tokens, and then mapping those tokens to numerical IDs that the model understands. It's the crucial preprocessing step that sits between you and the model.
Here's the chain:
1. Raw Text → "Walking in the park is fun" 2. Tokenization → ["walk", "ing", " in", " the", " park", " is", " fun"] 3. Numerical IDs → 4, 5, 6, 7, 8, 9, 10
The model doesn't see words, it sees numbers. And each number represents a token. More tokens = higher costs, slower inference, and more memory consumption.
The kicker? The tokenizer is invisible but omnipresent. OpenAI's tiktoken, Google's SentencePiece, or Hugging Face's tokenizer are quietly deciding how many tokens your input consumes, and therefore how much you'll pay.
How Does Tokenization Actually Work? The BPE Algorithm
Most modern LLMs use Byte Pair Encoding (BPE), a surprisingly elegant algorithm that learns to recognize common character patterns in your training data.
Here's the step by step process:
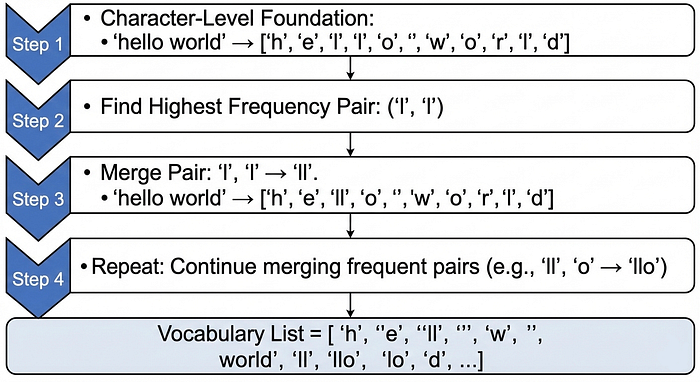
Step 1: Character Level Foundation Start by treating every character as a token:
"hello world" → ['h','e','l','l','o',' ','w','o','r','l','d']Step 2: Find the Pair with the Highest Frequency Scan the entire corpus and count how often each pair of adjacent characters appears:
('l', 'l'): 5,234 times
('o', ' '): 3,421 times
('w', 'o'): 1,892 times
…Step 3: Merge the Most Frequent Pair Replace every occurrence of the most frequent pair with a new token:
('l', 'l') → 'll'
"hello world" → ['h','e','ll','o',' ','w','o','r','l','d']Step 4: Repeat Find the next most frequent pair and merge it. Repeat thousands of times until you've created a vocabulary of the desired size (typically 50,000 tokens for GPT models).
Why this matters: By learning that common sequences should be single tokens, BPE reduces the total number of tokens needed to represent text. Instead of encoding "walking" as 6 characters, it learns to encode it as 2 tokens: "walk" + "ing".
The Token Economy: Context Windows and Costs
Every LLM has a context window, a hard limit on how many tokens it can process in one request. This isn't just an architectural constraint; it's your billing constraint.
Real world example: - GPT 4 with 8K context window = ~6,000 words of usable space (accounting for output) - GPT 4 Turbo with 128K context window = ~100,000 words of usable space - OpenAI charges $0.03 per 1K input tokens for GPT 4
If you waste tokens on unnecessary formatting characters (braces, quotes, commas), you're literally paying to send garbage to the model.
This is where data formats start mattering intensely.
JSON: Universal but Verbose
JSON is everywhere. It's battle tested, supported by every language, and developers love it. But for LLMs, JSON is tokenization inefficient.
Here's why. Consider this simple user list:
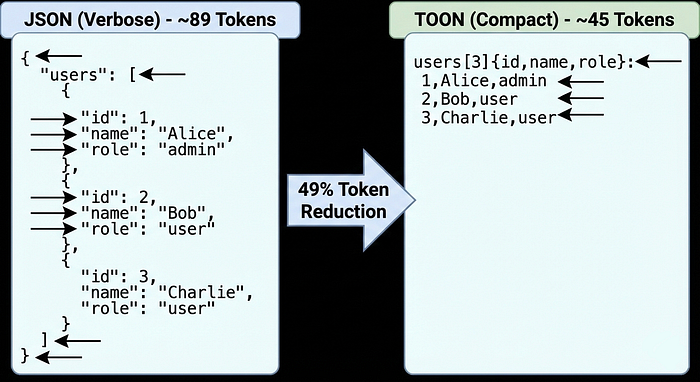
{
"users": [
{"id": 1, "name": "Alice", "role": "admin"},
{"id": 2, "name": "Bob", "role": "user"},
{"id": 3, "name": "Charlie", "role": "user"}
]
}Tokenizing this with OpenAI's tiktoken? 89 tokens.
What's consuming those tokens? - Each `{` and `}` → token - Each `[` and `]` → token - Each `:` and `,` → token - Every key name like `"id"`, `"name"`, `"role"` repeated three times → multiple tokens per repetition - Every quote `"` → tokens
For structured data with repeating fields (which is 80% of real world LLM prompts), JSON is remarkably wasteful.
Minified JSON helps slightly, removing whitespace saves ~30% compared to pretty printed JSON. But even minified JSON retains all the structural characters that inflate token count.
YAML: More Readable, Still Not Optimal
YAML represents an improvement over pretty printed JSON by leveraging indentation instead of braces:
users:
- id: 1
name: Alice
role: admin
- id: 2
name: Bob
role: user
- id: 3
name: Charlie
role: userYAML tokenizes to around 133 tokens for the same data.
That's 50% worse than minified JSON, the opposite of what you might read on LinkedIn.
Why? YAML requires whitespace to convey meaning. Every indentation level, every newline, these are semantically significant, so they can't be stripped without breaking the structure. You can't "minify" YAML the way you minify JSON.
The research claiming YAML is more token efficient compared pretty printed JSON against minified JSON, an unfair comparison. When you control for whitespace properly, minified JSON edges out YAML.
TOON: Rethinking Structured Data for LLMs
Now enter TOON (Token Oriented Object Notation), a format designed from the ground up for LLM consumption.
The same user list in TOON:
users[3]{id,name,role}:
1,Alice,admin
2,Bob,user
3,Charlie,userToken count: 45 tokens.
That's a 49% reduction compared to JSON, not minified, just regular JSON.
What makes TOON so efficient?
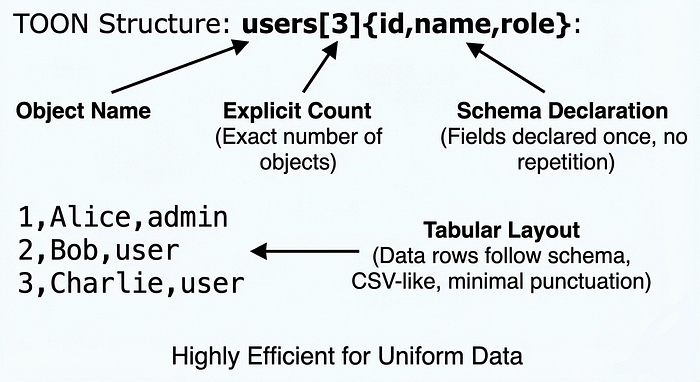
1. No Repeated Field Names In JSON, every object repeats `"id": `, `"name": `, `"role": `. In TOON, you declare the fields once: `{id,name,role}`. The model understands these are the fields for the following rows.
2. No Unnecessary Punctuation - No braces around objects within the array - No quotes around string keys - No commas between fields inside braces - Minimal structural overhead
3. Tabular Layout for Uniform Data When data is uniform (multiple objects with identical fields), TOON adopts a CSV like structure. This visual similarity helps LLMs parse the structure correctly while minimizing tokens.
4. Schema Declarations users[3] tells the LLM: "There are exactly 3 user objects." This explicit boundary marker actually helps LLM accuracy: fewer hallucinations, better parsing.
The Dark Knight: SentencePiece (Nobody Talks About This)
Here's the honest truth: while everyone discusses TOON, JSON, and YAML, there's a tokenizer working silently in production models like Google's T5, Facebook's XLM-R, and hundreds of transformer models, SentencePiece and almost nobody understands how it actually works.
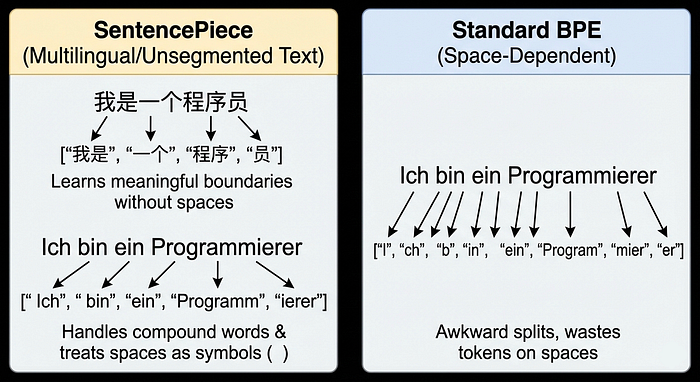
SentencePiece isn't a data format. It's a different tokenization philosophy entirely. While BPE (used by ChatGPT) looks at your already segmented text and finds optimal byte pairs, SentencePiece looks at raw, unsegmented text and builds tokens from scratch without assuming word boundaries exist.
The Problem SentencePiece Solves
Imagine you're building a multilingual model supporting Chinese, Japanese, English, and Arabic. BPE has a fatal weakness: it assumes spaces mean word boundaries. English has spaces. Chinese doesn't. Japanese has no spaces. Arabic is ambiguous.
Standard BPE on Chinese:
"我是一个程序员" (I am a programmer)BPE sees this as a continuous stream with no word breaks. It might tokenize arbitrarily: ["我是", "一个", "程", "序", "员"]
SentencePiece on Chinese:
"我是一个程序员"
→ Learns statistically meaningful boundaries
→ ["我是", "一个", "程序", "员"]The key difference: SentencePiece treats spaces as explicit symbols (▁) rather than implicit delimiters. This subtle but radical shift makes it language agnostic.
Real Example: The Honest Comparison
Let's tokenize the same sentence three ways on a non English dataset:
Sentence: "Ich bin ein Programmierer" (German for "I am a programmer")
SentencePiece wins here, but it's completely invisible in English NLP discourse.
Why Nobody Talks About SentencePiece
1. It just works: SentencePiece is buried inside model training pipelines. You download a pretrained model, and the tokenizer comes with it. You never think about it.
2. Documentation is academic: The original paper is excellent but dense. Most tutorials skip explaining why it matters for practical applications.
3. Naming confusion: People say "use SentencePiece BPE" and "use BPE", sounds the same. In reality, SentencePiece handles raw text; standard BPE expects pre-tokenized input. Massive difference.
4. English-centric mindset: In English NLP, spaces happen to work fine as word boundaries. For 90% of online NLP content (written in English, by English speakers), SentencePiece seems unnecessary. For Chinese, Japanese, Thai, Korean? It's non negotiable.
The Honest Drawback
SentencePiece isn't magic. Training it is slower than BPE, you're learning probabilistically optimal splits rather than just greedy merges. For a 10GB corpus, SentencePiece training might take 2-3x longer than BPE training.
Also, the output can be unpredictable if you're not careful with hyperparameters. Character coverage (the percentage of characters to handle), vocabulary size, and unigram smoothing all dramatically affect tokenization. Get it wrong, and you'll have weird segmentation artifacts.
The real issue: SentencePiece excels at languages without word boundaries. For English and similar languages, it's not obviously better than BPE. It's more like "SentencePiece is required for multilingual systems; BPE is fine for English only systems."
Comparing All Four Approaches
Here's a benchmark on a realistic dataset with 50 user objects:
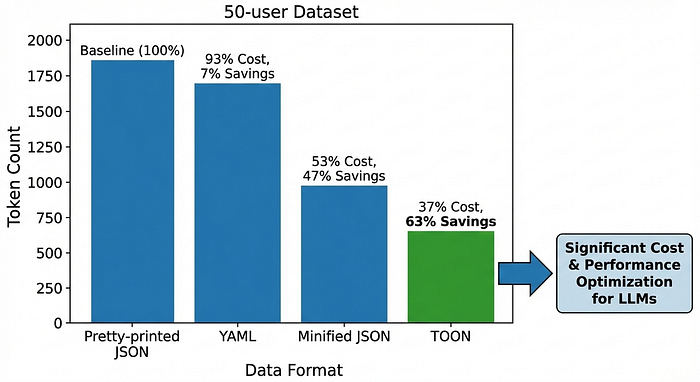
For a 10,000-token prompt that's currently JSON: - TOON version uses ~3,700 tokens instead of ~10,000 - At $0.03 per 1K tokens (GPT-4) = $0.22 saved per request - Scale to 10,000 requests per day = $2,200 daily savings
When to Use Each Format
Use JSON when: - You need universal API compatibility - Your data is deeply nested or irregular - Your team's entire pipeline expects JSON - The token savings don't justify refactoring
Use YAML when: - You're generating readable output from an LLM (not feeding it input) - Your data has moderate complexity - Human readability is more important than token efficiency
Use Minified JSON when: - You want a 2-minute optimization that saves ~50% without format changes - You're already in the JSON ecosystem - You can't refactor to TOON
Use TOON when: - You're passing structured, uniform data to an LLM (RAG chunks, database records, logs) - Token costs are a primary concern - Your data has repeating field structures - You can tolerate a format conversion step in your pipeline
Use SentencePiece Tokenizer when: - You're building multilingual or non English models - You need language agnostic preprocessing - You're working with unsegmented languages (Chinese, Japanese, Thai) - Standard BPE is producing weird cross boundary segmentations
The Practical Integration Path
For TOON: Adopting TOON doesn't mean rewriting your entire stack. Start small:
- Measure your token usage in one high volume prompt
- Convert a sample to TOON format
- Benchmark the tokens saved
- If savings are meaningful (>20%), integrate conversion into your prompt building code
- Monitor LLM output quality: TOON's explicit schema actually helps with structured generation
Libraries like toon-parse (JavaScript) and community implementations make this straightforward.
For SentencePiece: If you're training a model:
import sentencepiece as spm
# Train a SentencePiece model
spm.SentencePieceTrainer.train(
input='raw_text.txt',
model_prefix='my_tokenizer',
vocab_size=32000,
model_type='bpe', # or 'unigram'
character_coverage=0.9995, # for CJK languages
)
# Use the trained tokenizer
sp = spm.SentencePieceProcessor()
sp.Load('my_tokenizer.model')
# Tokenize text
tokens = sp.EncodeAsPieces("こんにちは世界") # Japanese
print(tokens) # Output: ['▁こんに', 'ちは', '▁世界']SentencePiece's advantage shines when you have multilingual data. The tokenizer learns what constitutes a meaningful token across all languages simultaneously, producing more uniform token lengths and better cross-lingual transfer.
Why This Matters More Than You Think
Tokenization efficiency isn't just about cost, it's about capability:
- Longer context: Same context window, more actual content
- Better retrieval: RAG systems can fit more document chunks into context
- Faster inference: Fewer tokens = faster computation
- Reduced hallucination: More space for precise, relevant context instead of structural noise
As LLM token limits expand but costs remain per token, the optimization pressure will only increase. Understanding and choosing the right format and tokenizer isn't premature optimization. It's architectural thinking.
The takeaway: Tokenizers are everywhere, silently dividing your text into numbered pieces. JSON is great for APIs but wasteful for LLMs. YAML is more readable but not necessarily more efficient. TOON is a quiet revolution, 30-60% fewer tokens for structured data. And SentencePiece? It's the actually important tokenizer that almost nobody in English language NLP circles understands, but it powers production multilingual models and handles non English text far better than BPE ever could.
Start by measuring your token consumption today. Then choose your format, or your tokenizer based on your actual use case. The savings (or the unlocked capabilities) might surprise you.
Thanks for reading! :)