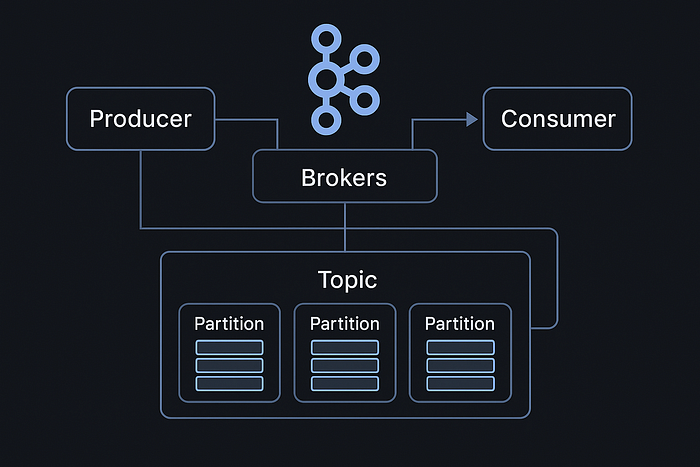


Apache Kafka is a distributed event streaming platform designed for high-throughput, low-latency, and durable log storage. Kafka acts as a commit log where producers append records and consumers read them in order.
Kafka is fundamentally a storage system optimized for sequential writes. Instead of deleting data after consumption, it retains logs for a configured time or size. This enables replay and decouples producers from consumers.
Scenario: In an e-commerce system, Kafka stores all order events. Downstream systems (billing, analytics, fraud detection) consume these events independently at their own pace.
Topics, Partitions & Offsets
- Topics: Logical categories of messages.
- Partitions: Logs within topics, ordered and immutable.
- Offsets: Sequential IDs for each record within a partition.
Partitions are the unit of parallelism. More partitions = more consumer concurrency. Offsets are managed per consumer group, enabling fault-tolerant parallel consumption.
Scenario: A payments topic with 12 partitions allows 12 consumers in a group to process events concurrently, scaling throughput linearly.
Storage Internals
Kafka stores messages as log segments on disk:
- Append-Only: Producers append records sequentially.
- Log Segments: Files split by size/time (default 1GB). Partition data split into
.logand.indexfiles. - Index Files: Maintain mapping between offsets and physical positions.
- Compaction: Retains the latest record per key, discarding older ones.
- Tiered Storage (2.8+): Moves cold data to S3/GCS while hot data stays local.
Sequential writes + page cache usage enable Kafka to outperform many databases. Compaction is critical for topics like user profiles, where only the latest value matters.
Scenario: A user settings topic uses log compaction, ensuring only the latest preference survives, keeping storage efficient.
Producers
Producers send records to brokers:
- Partitioner: Chooses partition (round-robin, hash key, custom).
- Batching: Groups messages for efficiency.
- ACKs: Configurable (
acks=0,acks=1,acks=all).
Choosing acks=all with replication factor >1 ensures durability. acks=0 maximizes throughput but risks data loss.
Scenario: A metrics pipeline uses acks=0 for ultra-low latency. A financial trading system uses acks=all with idempotence enabled for strict durability.
Pitfalls
- Hot partitions → broker imbalance.
- Compression saves network but may saturate CPU.
Consumers
Consumers read sequentially:
- Consumer Groups: Coordinate parallel processing.
- Rebalancing: Redistributes partitions when group members change.
- Offset Management: Committed to Kafka or external stores.
- Consumer lag ≠ data loss; often a sign of downstream bottlenecks.
- Large-scale deployments face thundering herd issues during rebalances.
Rebalancing pauses consumption temporarily. Kafka 2.4+ introduced incremental rebalancing to reduce disruption.
Scenario: In a fraud detection system, if a consumer crashes, its partitions are reassigned to healthy instances, ensuring no events are skipped.
Replication & Fault Tolerance
Kafka ensures durability with replication:
- Replication Factor: Number of copies per partition.
- Leader & Followers: One broker is leader, others replicate.
- ISR (In-Sync Replicas): Followers fully caught up with leader.
- Unclean leader election favors availability but risks durability.
- Re-replication floods network unless throttled.
- Cross-region replication (MirrorMaker 2.0) → eventual consistency vs synchronous high-latency trade-offs.
Producers can require writes to be acknowledged only if committed to ISR. Leader elections occur when leaders fail; unclean leader election risks data loss.
Scenario: A 3-replica topic ensures durability. If one broker fails, another replica takes over without losing data.
Controller & Metadata Management
- Controller Broker: Manages partition leaders and replicas.
- Zookeeper (Legacy): Stored metadata, coordinated elections.
- KRaft Mode (Kafka 2.8+): Replaces Zookeeper with internal Raft consensus.
- Zookeeper vs KRaft: KRaft uses Raft consensus, simplifying ops
Metadata is cached in brokers and updated via controller notifications. Modern deployments use KRaft for simplified operations.
Scenario: A cluster upgrade moves from Zookeeper to KRaft, reducing operational complexity by eliminating external coordination service.
Networking & Protocols
Kafka uses a custom TCP protocol:
- Request/Response: Producers/consumers communicate with brokers.
- Zero-Copy Transfers: Kafka uses
sendfile()to stream data directly from disk to network. - Compression: Batch compression (gzip, snappy, lz4, zstd).
- TLS/SASL: Secure but CPU intensive — requires hardware acceleration.
Zero-copy is why Kafka achieves high throughput — no extra memory copies between user and kernel space.
A video analytics pipeline compresses logs with lz4, balancing CPU usage and throughput.
Transactions & Exactly-Once Semantics
Kafka provides exactly-once semantics (EOS):
- Idempotent Producers: Prevent duplicate writes.
- Transactions: Commit multiple writes atomically.
- Consumer Isolation: Read only committed messages.
EOS requires coordination between producer IDs, transaction coordinator, and consumer offsets. It guarantees messages are delivered once even with retries.
Operational Challenges & Scaling Patterns
Capacity Planning
- Partition sizing must balance throughput vs metadata overhead.
- Retention policies determine storage costs (petabytes for week-long retention at high event rates).
Fault-Tolerance Edge Cases
- Zombie Producers: Must be fenced.
- Lagging Consumers: Cause storage blowups if retention mismatches demand.Optimization Strategies
- Tiered Storage: Reduces cost.
- Cluster Sharding: Domain-level isolation.
- Hybrid Topics: Both compaction + deletion.
📌 Scenario: Uber shards clusters by business vertical (Mobility, Eats, Freight) and deploys autoscaling consumers tied to lag metrics.
Closing Thoughts
To a developer, Kafka looks like a queue, but it is:-
- Designing partition & replication strategies at scale.
- Managing trade-offs between latency, durability, and cost.
- Running hundreds of brokers across regions reliably.
- Debugging ISR shrinkage, controller failovers, and consumer lag during real outages.
Kafka is not just a pub/sub system. It is the nervous system of modern data architectures.
Enjoyed the article? Follow me on X.com for more interesting content, and check out my website at anuraggoel.in !😊🚀
A message from our Founder
Hey, Sunil here. I wanted to take a moment to thank you for reading until the end and for being a part of this community.
Did you know that our team run these publications as a volunteer effort to over 3.5m monthly readers? We don't receive any funding, we do this to support the community. ❤️
If you want to show some love, please take a moment to follow me on LinkedIn, TikTok, Instagram. You can also subscribe to our weekly newsletter.
And before you go, don't forget to clap and follow the writer️!