

I wrote this blog post in order to share my experience of writing a small scalable worker service on top of Node.js and Kafka. Source code of the idea presented here can be found here.
This is also a nice showcase of a really good library called KafkaJS.
What are the problems this library is trying to solve?
- Workers(Kafka Consumers) can be run in parallel in order to scale processing of messages.
- Task will be processed by only one worker. Make sure no two workers working on the same task.
- Retry of failed tasks will be accomplished by placing them again on Kafka based on retry policy.
- Tasks published to Kafka at any given moment need to be independent of each other
- Sequential execution or dependent tasks are supported, but they are placed on Kafka after their parent task is finished.
Is there an example of a real world app that would use this?
I am glad you asked! Imagine you have an app that allows user to store files and perform some operation against them. App needs to perform some long running tasks against each file that gets uploaded.
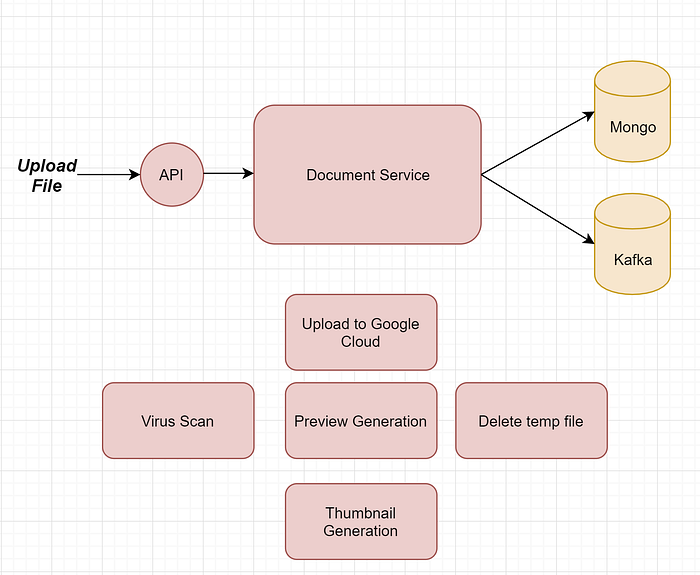
Uploaded file is saved to temporary file location, before it gets uploaded to the final one on Google Cloud Storage. On the image above you can see that we have 5 main tasks, virus scan, upload to GC, preview generation(conversion to PDF), thumbnail generation and final temp file cleanup.
Virus scan needs to be done before other 4, and upload, preview and thumbnail generation can be executed in parallel. Deletion of temp file needs to be executed only after all previous tasks are finished(either successfully or unsuccessfully).
ITaskHandler Interface
Our app needs to register 5 long running tasks and each of them needs an implementation of an interface called ITaskHandler.

Method handle will be called by engine when new message gets received from Kafka. Before calling that method worker engine will find appropriate registered instance of ITaskHandler based on type of task.
Examples: VirusScanTaskHandler, UploadFileTaskHandler etc..
From the interface you can see that return type is a list of tasks, and this is what will allow main app to easily tell worker engine to schedule for execution another batch of tasks. They will be sent to Kafka and that same or some other instance of worker service will pick them up. Those returned tasks will be executed in parallel.
How does the worker service work internally?
Let's start from the visual:
Worker service communicates with Kafka directly by using quite good KafkaJs library. All instances of worker service are belonging to the same Kafka Consumer Group. This is important in order to make sure they are all consuming unique messages. This also means that in order to scale consumption of messages it is not enough to increase number of worker instances, we also need to increase number of partitions on Kafka.
One worker service instance will get a batch of messages that will process in parallel. Every batch is taken from only one partition at any given moment.
Because all worker instances belong to the same consumer group, every instance will get one or more dedicated partitions. Worker instance can get 0 partitions, if the number of workers is larger then the number of partitions.
Why Message Handler when there is already a Task handler?
Message Handler is responsible for tracking the execution of each task.
The image below shows that Message Handler is responsible for tracking task processing state and main information includes status, duration of task and error details in case of failure. It stores task execution info that can be later used for analyzing and reporting.
Task Execution State
Tasks and task execution data is stored in MongoDB. These two collections contain information against which we can run different queries that might alarm us in case of some indicator of bad processing.
Some indicators might be:
System has N workers but only a subset executes task. Kafka has N partitions but only messages from a subset of them is being consumed and executed.
Task State Manager component is being used by Message Handler to store all this information about each task. You can easily replace the default Task State Manager with your own. The default one stores tasks in MongoDB.
Rescheduling of tasks in case of failure is done by Worker Service.
What about backpressure?
One of the first articles that I have stumbled upon was this one: https://medium.com/walkme-engineering/managing-consumer-commits-and-back-pressure-with-node-js-and-kafka-in-production-cfd20c8120e3
Luckily, the engine itself did not have to implement this, because the library KafkaJS will not push next batch of messages until the previous one has finished.
Method "eachBatch" returns a Promise and our implementation resolves that promise after all messages from that batch have been processed in parallel.
But what about batch size?
At the moment of writing this article KafkaJS did not support batch size limit.
That is something that we need to be able to control, mostly because of memory limits.
What's Next
Worker Engine represents just one out many different ways this small Document Service can be implemented. I think it would be quite good exploring Event Driven Serverless Approach. So, please stay tuned.