


Introduction
Algorithms, Part 1 is a solid course for IT or software engineers to learn algorithms which are provided by Princeton. Of course, we still have to take time to clarify the concepts after completing the class.
Union-Find is a data structure for recording whether points are in the same set. In this article, we will focus on Union-find and its improvements algorithms.
About this Series
This series aims to wrap up contents of Algorithms, Part 1.
- week 1: this article
- week 2: Stack, Queue, and Week 2 Assignment Deques and Randomized Queues
- week 3: Sorting and Week 3 assignment Collinear Points
- week 4: Binary Tree, Binary Heaps, and Week 4 Assignment 8 puzzle
- week 5: Hash table and Week 5 Assignment KD-Tree
Agenda
It includes the following topics in this article.
- Analysis of algorithms
- Algorithm design approach
- Union-Find
- Improvement for quick union 1: weighting
- Improvement for quick union 2: path compression
- Related Leetcode questions
- Week 1 Programming Assignment: Percolation
1. Analysis of algorithms
Example — 2 sum
Approximately how many array accesses as a function of input size N?
Bottom line: use cost model and tilde notation to simplify counts
Simplification 1: cost model
Use some basic operation as a proxy for running time
Simplification 2: tilde notation
- Estimate running time (or memory) as a function of input size
N - Ignore lower order terms
- When
Nis large, terms are negligible - WhenNis small, we don't care
Common math formulas
1 + 2 + ... + N=1/2 * N * (1 + N)1^k + 2^k + ... + N^k=1/(k + 1) * N ^ (k + 1)1 + 1/2 + ... + 1/N=Log N- Triple loops =
1/6 * N ^ 3
2. Algorithm design approach
Steps to develop a usable algorithm
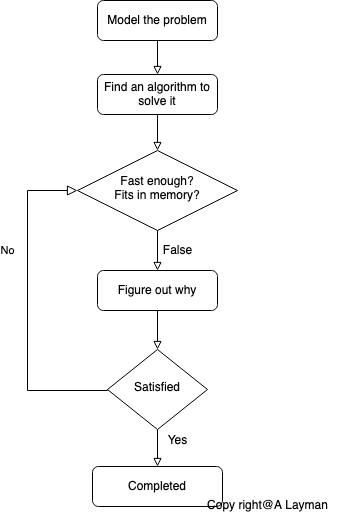
Optimal algorithm
Lower bound equals to upper bound (to within a constant factor)
- e.g 1.,
Brute-forcealgorithm for -sum is optimal: it's running time isN - e.g 2.,
Merge sortis an optimal algorithm - upper bound: ~N log N- lower bound: ~N log N
Approach
- Develop an algorithm
- Prove a lower bound
- If this a gap between lower bound and the upper bound, lower the upper bound (discover a new algorithm) or raise the lower bound (more difficult)
3. Union-Find
Goal
Design efficient data structure for union-find
- Number of objects
Ncan be huge - Number of operations
Mcan be huge - Find queries and union commands may be intermixed
Quick find (eager approach)
- Integer array id of
N - Interpretation
-
pandqare connected iff(if and only if) they have the same id
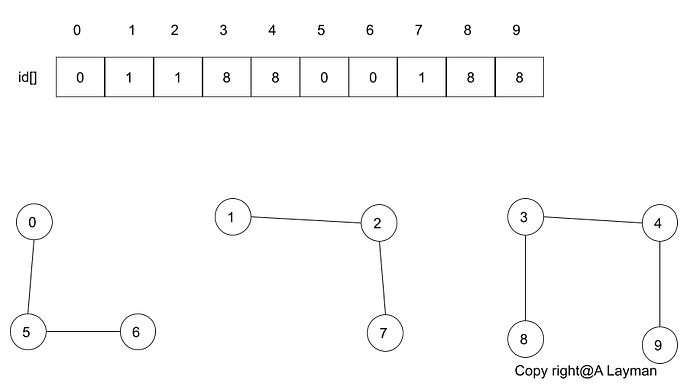
Java implementation
- union too expensive (N array accesses)
- trees are flat, but too expensive to keep them flat
Quick union (lazy approach)
- Integer array id of
N - Interpretation
-
id[i]is the parent ofi- Root ofiisid[id[id[...id[i]...]]]
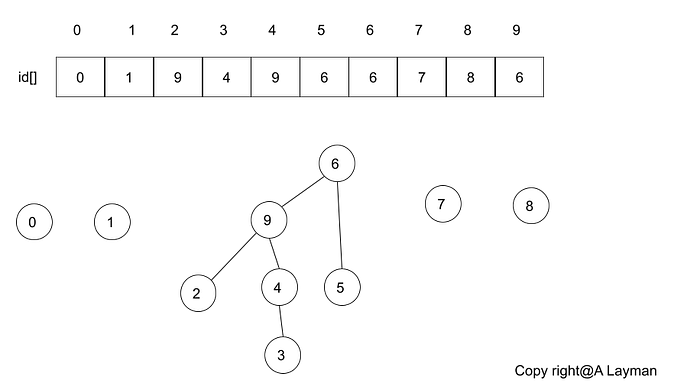
Java implementation
- tree can get tall
- find too expensive (could be
Narray accesses)
Quick find vs Quick union
4. Improvement for quick union 1: weighting
Purpose
- Avoid tall trees
- Keep track of size of each tree (number of objects)
- Balance by linking root of smaller tree to root of larger tree
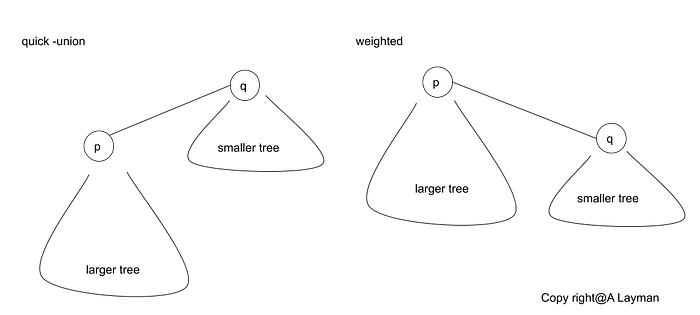
Proposition
Depth of any node x is at most log N
Why?
- The depth of x increase
1/the size of the treeat least doubles when tree T1 containing x is merged into another tree T2 - The size of tree containing x can double at most
log Ntimes
Java implementation
- link root of smaller tree to root of larger tree
- update the
sz[]array
Proposition of Quick find, Quick union, and weighted quick-union
5. Improvement for quick union 2: path compression
Purpose
- Flatten the tree
- Just after computing the root of
p, set the id of each examined node to point to that root

Java implementation
Proposition: Bottom line
WQUPC reduces from 30 years to 6 seconds.
Related Leetcode questions
- 2 sum (easy)
- 3 sum
- binary search (easy)
- Least common ancestor (medium)
- Redundant Connection (medium)
- Number of Operations to Make Network Connected (medium)
Week 1 Programming Assignment: Percolation
It's called percolation if the opened sited were connected from the top to the bottom. So what's the probability? (The numbers of opened sites/The numbers of total sites)
Requirements in detail
Solutions
- Percolation.java
- PercolationStats.java
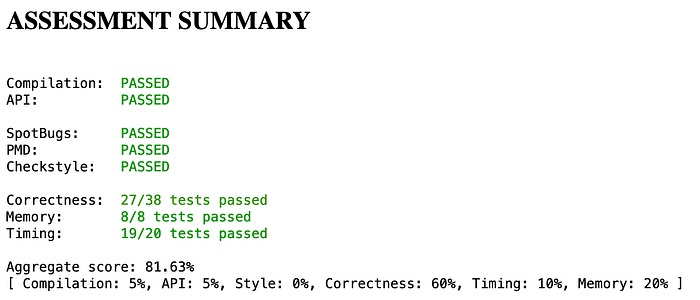
Grades
References
- Java Algorithms and Clients
- 普林斯顿算法 — — week1 作业一 percolation
- CheckStyle报错的常见问题及解决方式
- allegoricalJest/coursera-percolation
- What is O(log* N)?
- ybruce61414 / LeetCode
Summary
Thanks for your patient. I am Sean. I work as a software engineer.
This article is my note. Please feel free to give me advice if any mistakes. I am looking forward to your feedback.
- Subscribe me
- The Facebook page for articles
- The latest side project: Daily Learning
Related topics
How to use the two-way binding in Knout.js and ReactJS?
Learn how to use SignalR to build a chatroom application
My reflection of <Effective SQL>:
IT & Network:
Database: