

Among the plethora of models released recently, one has stood out: OpenAI's new frontier coding model, which responds at 1,000 tokens/second.
For reference, that's around 20 times faster than the frontier competition.
But how is this possible?
Interestingly, the answer has little to do with the model and much to do with a much lesser-known company that will very likely IPO this year.
Reaching Escape Velocity
GPT-5.3 Codex Spark is a new OpenAI model in preview mode that's only available to Pro users that is fast. Absurdly fast.
I apologize in advance for the quality, but the comparison below really gives you an idea of how fast this model is to build a snake game (I shortened it, but the other model took 30–40 seconds more):
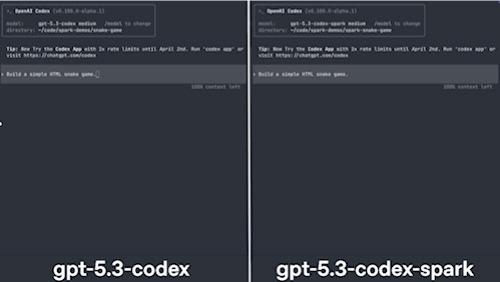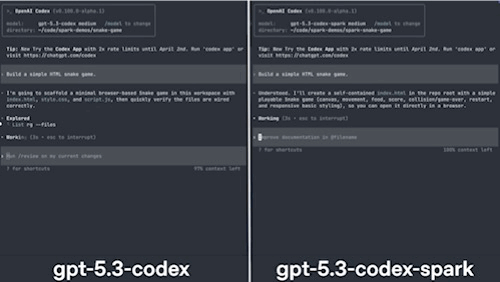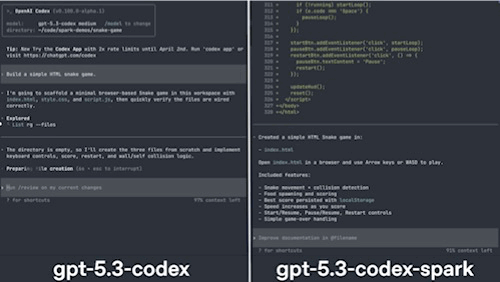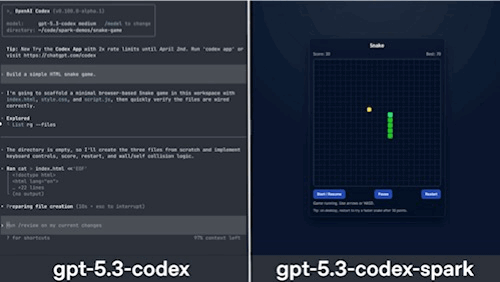
Prompt-to-playable game in five seconds, and it would have been faster if not for tool calling (more on why this matters a lot for investors later).
Luckily, I had the opportunity to test the model myself, and the results were quite impressive. Again, the video-to-gif compression leads to mediocre resolution, but you can still appreciate the model's burstiness:
And you may ask? Is this a new model?
It's certainly not a diffusion model (you can tell it's still predicting the next word in a sequence). In fact, if you see below how a diffusion Large Language Model (dLLM) actually works, it's not autoregressive (not one token after the previous, but all tokens are generated simultaneously).
The GIF below first shows the real-time output speed, then a slowed-down version that lets you appreciate that tokens in diffusion LLMs are not generated one after the other.
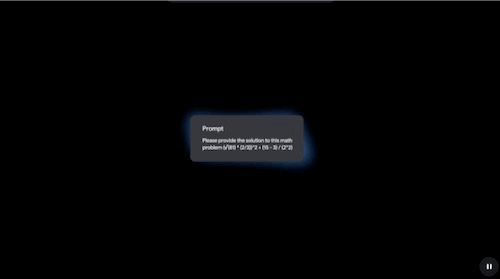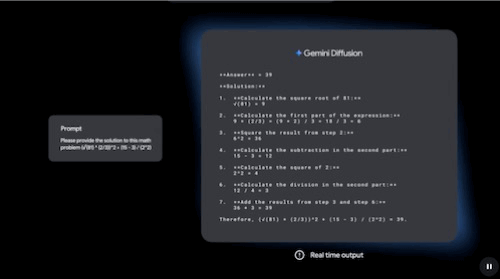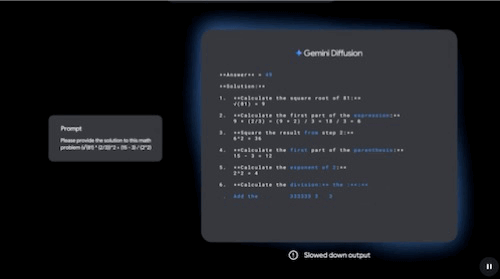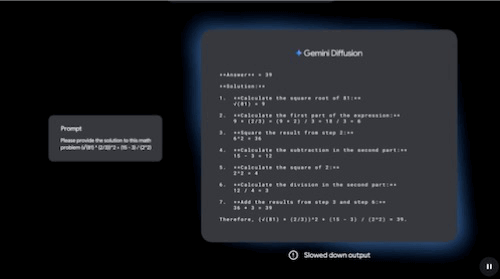
Additionally, the model's codename suggests it's just a new version of their GPT-5.3 frontier base model. And while the model is confirmed to be smaller (most likely a distillation), it's not small enough to justify the absurd speed increase.
Additionally, the model can't be super small because it's actually very capable, as you can see below, making it the absolute frontier model when it comes to performance-per-speed:
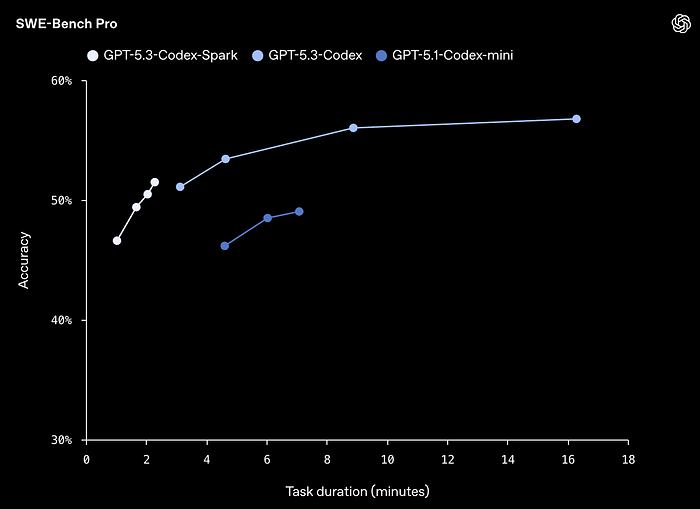
So, then, how did they pull this off?
And the answer has nothing to do with OpenAI's model effort and a lot to do with a company that might IPO in 2026: Cerebras.
Cerebras, A Contrarian Bet that Finally Paid Off
The biggest change here is that the hardware being used to serve this model is not Graphic Processing Units (GPUs) coming from NVIDIA or AMD. They are WSEs, or Wafer Scale Engines.
But what on Earth is that?
Several years ago, a group of expert computer scientists looked into the future and did not like what they saw. They foresaw that GPUs would soon reach their limits. There are two big problems with GPUs that are becoming more apparent every day:
- An inference performance issue: AI inference is massively memory-bottlenecked and will remain that way.
- A physical issue: packaging complexity could drive progress to a halt.
Let's tackle both.
The GPU data dance
GPUs are computers, meaning they are machines that perform computations.
GPUs excel at a particular type of computation that is simple but parallelizable, meaning you can do many of them in parallel, which is precisely what AIs need.
But the problem is that, for GPUs to perform such computations, they need memory to supply the data to the compute cores in time, since the AI model does not reside where the computation is performed.
Thus, there's always continuous communication between the compute chips (where the magic happens) and the memory chips (where the model and data are stored).
More specifically, the AI model is broken down into pieces, sent with the data to the compute cores, processed, and returned so the next part of the model can be used. This back-and-forth is extensive and exhaustive, especially in AI inference (the part where models are actually served to users), like when you use ChatGPT.
The problem is that the distance to be travelled is not small (ideally, you would want memory to reside inside the compute chips), because AI models are so massive that, as mentioned earlier, they have to reside in external memory chips rather than on the actual GPU dies.
Sadly, data doesn't teleport, so there's a time component here; data can take a long time to reach the compute dies. Being more specific, there are periods (very small in human terms but very meaningful at scale) when the compute chips are "idle".
For instance, if the compute chips were to require, say, 20 Terabytes of data immediately, and the memory bus can only provide around 8 Terabytes/second, the compute dies would stay idle for a whole 2.5 seconds, which is, and I can't understate this, tragic.
In practice, this never happens beyond the initial model-loading phase, and GPUs are always working to some extent.
However, the real issue is not whether they are working or not, but how much.
To measure the quantity of work, we use a metric called arithmetic intensity. This is measured as the number of operations per transferred byte. In layman's terms, how much work (computations) are GPU compute chips doing for every new piece of data they receive from memory.
The number is actually very intuitive. If your GPU can perform 100 operations per piece of information it receives, but is effectively only doing 10, that means it is working at 10% of its peak compute capacity.
When that happens, in AI parlance, we say that your workload is 'memory-bottlenecked' because your memory bandwidth, how much new work can be provided to your GPUs, is the limiting factor.
This is, by the way, the default state in AI inference on GPUs, which is what drives most of compute today.
Although a little technical, the Cerebras guys themselves explain this by clarifying the main design principle in their hardware we'll discuss later: sparsity awareness.
They claim that sparser (meaning less parallelization) computations like matrix-vector (which are the overwhelming math operation in AI inference) require much higher levels of memory bandwidth GPUs simply cannot provide well, and basically argue in a principled way that GPUs were not designed for such operations (which is true), while Cerebras's chips, as we'll see later, are.
For the nitpickers in my reader base, we have to clarify that in AI inference, matrix-vector computations are still matrix-matrix in practice because of the batch dimension, but the point still stands: they are much sparser than what GPUs were designed to excel at.
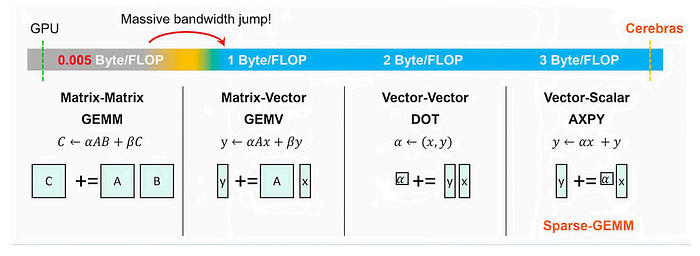
Which is to say that, in plain English, Cerebras was conceived as an AI inference engine while GPUs weren't.
But before we cover Cerebras' technology, we need to clarify the other main problem GPUs face: packaging complexity, because, besides proving Cerebras' point, it's an opportunity to teach us a lot about how the industry and markets are behaving.
The limits of packaging
GPUs these days are not just compute chips, as many people think; they are complete packages with other components. Mainly, it's the presence of memory chips sitting close by, forming an 'advanced package' that is what a 'GPU' actually is in practice.
As stated, the reason for the presence of external memory chips inside a GPU package is that modern AI workloads require a lot of memory and a lot of bandwidth.
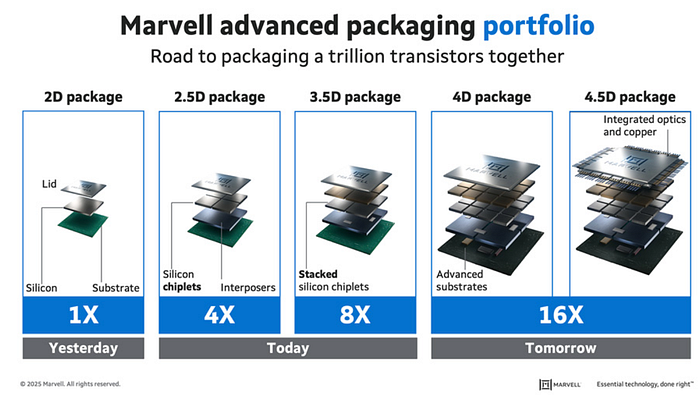
In fact, a modern GPU package looks much more like this "thing" shown below. Please don't get discouraged by your initial reaction to the diagram; it's actually not that hard to interpret.
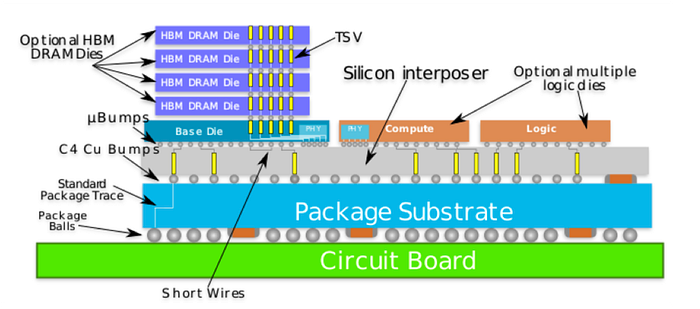
The orange rectangles are the actual GPU chiplets (we have more than one of these these days, carefully stitched together).
Here is where the compute magic happens. They have some SRAM memory inside the chip, which is very fast and in the hundreds of MBs, but not enough for what AI requires (we're off by six orders of magnitude, as we need Terabyte-level sizes).
Instead, models — and the cache — reside in the purple rectangles, which are High Bandwidth Memory (HBM) stacks, several DRAM chips stacked one on top of the other (between 8 and 12 these days, soon enough 16).
The reason for stacking is to maximize the amount of memory we can store close to the GPU chiplets. At the bottom of the stack, in gray, is the interposer that connects everything with thin wires that transport data between the two worlds.
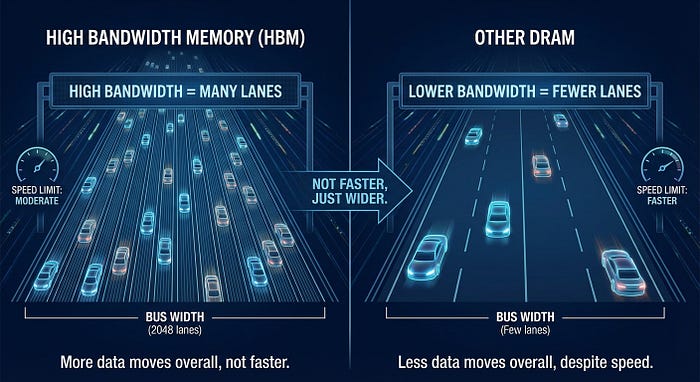
People will sometimes refer to 'bandwidth' as 'speed', but that's, at best, misleading. High Bandwidth Memory (HBM), the type of memory chip used in AI, isn't necessarily faster than other DRAM technologies that aren't as useful for AI, or at least that's certainly not its forte. What makes HBM useful is not faster data rates, but larger bus widths.
Think of this memory-compute communication as a highway. The maximum speed limit is the speed at which each lane moves, which isn't particularly fast for HBM chips; the key is that there are a lot of lanes (2,048, to be exact, in HBM4, the newest generation to be used in the new GPU generations like NVIDIA Rubin).
But all this raises a big question: how do we scale? How do we make GPUs better from here?
The first option is to improve the chips. "Better" is usually defined by the number of transistors a chip has, which increases computing power.
However, these are already very small (a billion times "smaller" than humans), and are finally approaching the limits of how small they can get, as semiconductor materials at such sizes no longer behave in predictable ways. This is why Moore's law is stagnating.
Therefore, to pack more compute into the package, an alternative is to increase the chip size (recall that I'm talking about the orange rectangle in the image above). However, doing so without making the manufacturing process absurdly expensive is not possible (i.e., it destroys yield, which I won't get into).
A third alternative, the direction we are taking today in GPUs, is to assemble several of these maximum-sized chiplets into a single unit while off-loading much of the memory outside the chip.
NVIDIA's Blackwell GPUs already have two maximum-sized chips, and the new platform Rubin, besides reducing transistor size from 4 nanometers to 3, also aims to scale to four stitched chiplets with Rubin Ultra, slated for 2027.
Stacking compute chips side-by-side is called 2.5D stacking, while what we are doing with the HBM memory stacks is called 3D stacking.
Interestingly, we can observe everything with our own eyes. In the image below, you can appreciate the two full-sized GPU chiplets at the center, and 8 HBM stacks above and below:

But why am I explaining all this? Well, because the path we've chosen — that we have been forced to choose, actually — is very, very hard. The reason is the light-gray and light-blue rectangles in the diagram I showed earlier:
The silicon interposer (light-gray) and the substrate (light-blue) explain much of the incoming manufacturing issues GPUs will face throughout the decade.
But why?
Well, because assembling all this together, the process known as advanced packaging, is quite possibly the hardest thing in AI's supply chain today to do correctly at scale, to the point most top chip designers only trust one single company in the entire planet, TSMC (although that will soon change but that's a story for another day, *cough* Samsung, Intel *cough*).
Perhaps the biggest issue is the interposer, a silicon wafer sitting below all this that works as the connection between all these compute and memory chips.
The pain point is that interposers are extremely delicate, and that's an understatement. And to make matters worse, it forces us to think about thermodynamics.
The problem is that materials expand when heated, and GPUs can get hotter than a Love Island episode, sometimes reaching well over 100 ºC (212 ºF).
And if things weren't already very complicated, beneath the delicate interposer, we need to place an organic substrate (light blue in the diagram) that provides connections to the PCB (Printed Circuit Board, bright green in our previous diagram) and the necessary rigidity to keep the entire system from breaking easily, which is a different material than the interposer.
Depending on the material's CTE (Coefficient of Thermal Expansion), they expand more or less. And in our case, the interposer expands way more than the substrate.
Ok, so?
The problem is that having this difference in expansion dynamics can cause 'warpage', literal bending of the GPU that makes the delicate interposer connections break, and basically converts our $50k-a-pop GPU into a glorified, very-expensive heater but not usable as a GPU anymore.
Therefore, the complexity of advanced packaging can become a significant bottleneck not long from now, potentially driving hardware progress to a halt.
For instance, while we are already struggling to package two chips side by side, we are also thinking about stacking compute chips on top of each other, which puts into perspective how hard things are going to get at the packaging level.
And while I don't know, or can claim, whether that will really make GPU production impossible to be built in the future, it's safe to say the path won't become easier.
Cerebras foresaw all this and said 'hell no', and approached AI serving a totally different way using WSEs. So, finally, what are they?
WSEs, putting memory close
WSEs are an inference-focused alternative to GPUs that, in essence, eliminate HBM chips altogether and force all memory to be 'on-chip'. Acknowledging the limitations of compute chiplet size, they redesigned the accelerator in two ways:
- Cerebras' chips are both compute and memory, and at a similar surface-area scale (see image below). That is, they allocate much more chip surface to very fast (and close to the compute) SRAM memory.
- To combat the loss of performance per compute chiplet, they decided to treat the entire wafer as "one single chip".
The first point is straightforward. There's no such thing as off-chip memory here (besides storage, which is largely ignored during inference); everything resides entirely inside the chip.
In Cerebras' words, half of the silicon area in each individual chiplet is used by 48 kB of memory. The other half is logic, comprising 110,000 standard cells.
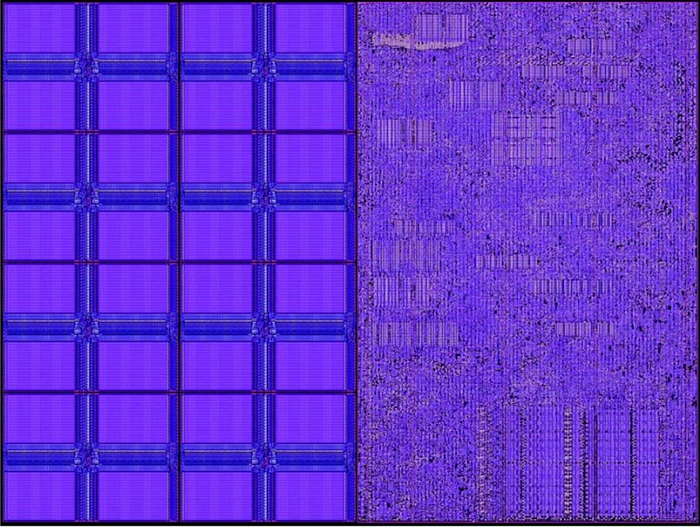
Careful, this is not 'in-memory computing', where the same place where computation is executed is also where it's stored (something I've only seen on analog computers, which I'm afraid are not scalable today). Here we are still separating compute from memory; they are just closer together!
Consequently, Cerebras is purposely increasing the amount of on-chip memory to avoid requiring external DRAM.
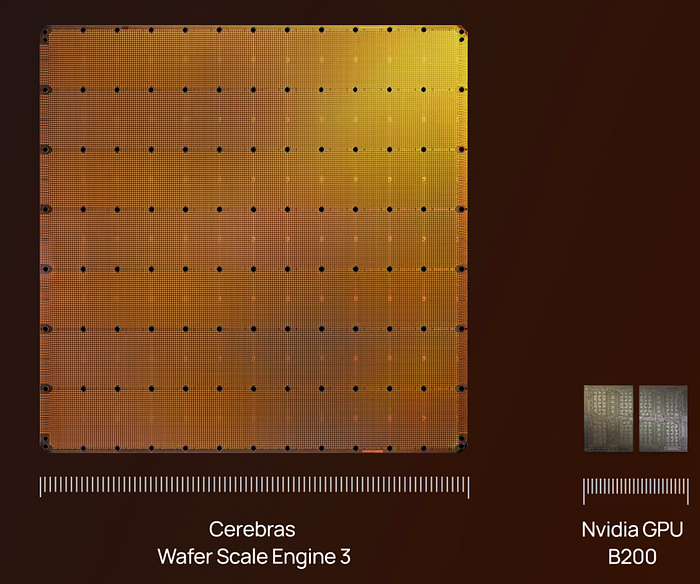
The second point is what explains the physical form factor WSEs have. In standard manufacturing, TSMC produces a wafer containing many chips.
Usually, these are sliced and diced (after checking they work) and packaged into GPUs as single units or pairs (e.g., Google's TPUv8 has a TPU with two compute dies, and another, cheaper version with just one chiplet).

Instead, Cerebras designs its product as the entire wafer, which is why it's called a "Wafer-Scale Engine".
Cerebras' overall system is also fault-aware, meaning that even if some chips on the wafer come out from production broken (this is inevitable), the system identifies them and routes around the issues. Pretty fascinating.
Crucially, while each chiplet is individually way worse, computationally speaking, than an NVIDIA chip, at scale, a WSE is way more powerful, packing trillions of transistors and petabytes/second of memory bandwidth… a scale of performance completely unattainable for a single GPU.
So, to answer the big question: how is this model so fast?
Well, it's all about the memory bandwidth that Cerebras' WSE systems provide; in a memory-bottlenecked world, the fact that memory resides in the "same place" means the models are processed way faster, as we can achieve much higher hardware utilization, and this explains the huge speed improvement from OpenAI's model.
Nonetheless, here are other very fast implementations of models using Cerebras that blow GPUs out of the water:
And what to take from all this? Well, a lot.
If you're enjoying this article, you are going to love my newsletter TheWhiteBox, where I explain AI in first principles for those allergic to hype but hungry for knowledge. For investors, executives, and enthusiasts alike.
Join today for free.
The yesses, the buts, and the CPUs
As with everything in engineering, this comes with trade-offs.
Complexity of deployment
The first is complexity. Because each chip has less computing power, the underlying logical circuits have to be simpler.
WSEs are still highly programmable (every tile runs code), but they trade away much of the general-purpose microarchitectural machinery and "run-anything" flexibility to maximize wafer-scale compute, on-chip SRAM, and deterministic communication, which in turn makes compilation/mapping a larger part of achieving performance than on a conventional GPU. In plain English, chips are simpler and abstract a lot of complexity up into the software running the show (the compiler).
In consequence, while on a GPU you're up and running with a new model almost immediately as the chip adapts to the new constraints, Cerebras implementations require significant software engineering effort.
Nevertheless, the fact that the model does not support images yet suggests the deployment complexity was not small and that they haven't yet quite figured out how to compile image encoders, the components required to process images.
Most often, alternatives to GPUs like Cerebras or Groq (now acquired by NVIDIA) imply much longer time-to-market. Instead, you can run a new model almost immediately on GPUs.
Another problem is cost.
It seems highly unlikely, or outright impossible, to choose WSEs over GPUs if you're optimizing for costs. The scale of investment needed to serve AI models on WSEs is even larger.
Each WSE "only" has 44 Gigabytes of SRAM, so you need more than 20 of these just to serve Kimi K2.5, 20 of these wafers to run a moderate-size model.
Therefore, although their approach works, it seems destined to be focused on use cases where speed makes all the difference, such as fast, iterative coding workflows (as in the one we are discussing today) or autonomous driving (if you one day manage to deploy WSEs on the actual car).
But the bigger problem here is the application to agents.
CPUs are the bottleneck
I don't know who needs to hear this, but let me make it crystal clear: in AI agents, the bottleneck is the CPU, not the GPU.
As shown in a study by Intel, tool calls are the main latency bottleneck in agents, and tools are mostly CPU workloads, making the CPU the actual performance bottleneck.
Recall that an 'AI agent' is just the fancy way of describing an LLM calling software tools (like other applications) in a loop.
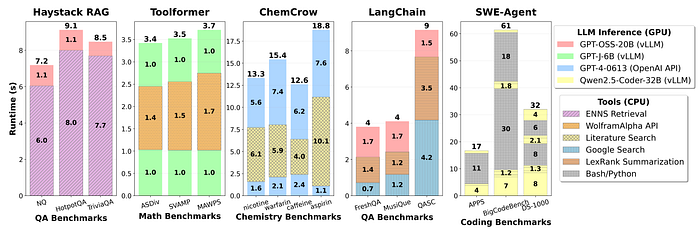
In fact, if you looked carefully at the examples I showed at the beginning, the latency bottlenecks caused by tool calls are super evident, especially in the first example (the snake game). If not for the tool calls, the model would have taken not five seconds, but actually closer to two, to answer.
This has a consequence: I have serious doubts that such hardware technologies make sense for agents that make extensive use of tool calls in every user response; you'll lose most of the speed advantage at the cost of higher inference serving costs.
Additionally, the huge attained speeds put way more into perspective how much of the latency bottleneck can be attributed to CPU workloads, which makes me believe that CPUs will drive significant narrative interest in AI soon, and the companies associated with them, which have not historically been closely linked to the AI trade for their CPU capabilities; companies like AMD, ARM, or Intel, stand to benefit from this agentic bottleneck as key CPU providers.
Exciting times
Who said AI wasn't dynamic? We always liken AI progress to models, but hardware is just as important (I'd say it's more important these days).
Cerebras' WSE is a wonderful technology that, while not representing a real threat to NVIDIA, especially now that they've acquired Groq (Groq's LPUs follow similar design principles to Cerebras, just executed differently), has earned its place in the AI industry for use cases where latency matters more.
Now, they have more proof than ever that the technology works, positioning them well for an IPO this year, something they've been after for a while and which could come as soon as next quarter.
The technology is awesome and legit, but as always, the question here is: Will the price be right?
If you enjoyed the article, I share similar thoughts in a more comprehensive and simplified manner on my LinkedIn (don't worry, no hyperbole there either). As a reminder, you can also subscribe to my newsletter.