
In the previous article, we explored Recurrent Neural Networks (RNNs) and how they process sequential data by maintaining a hidden state across time steps. RNNs were a major breakthrough because they allowed neural networks to capture relationships within sequences such as sentences, time series, and speech signals.
However, RNNs suffer from a major limitation known as the long-term dependency problem. To solve this issue, researchers introduced a more advanced architecture called Long Short-Term Memory (LSTM).
In this article, we will explore:
- Why RNN fails for long sequences
- What LSTM is
- How LSTM stores long-term information
- The role of gates in LSTM
The Long-Term Dependency Problem
Although RNNs maintain a hidden state that carries information forward through time, they struggle to remember information from earlier parts of long sequences.
Consider the following sentence:
"I grew up in France, moved to several countries, and after many years I finally became fluent in French."
To understand this sentence properly, the model must connect "France" with "French", even though many words appear between them.
A simple RNN often fails in this scenario because information from earlier time steps gradually fades away as new inputs arrive. This happens due to a training issue known as the vanishing gradient problem, where gradients become extremely small during backpropagation through time.
As a result, RNN tends to focus more on recent inputs, while forgetting information that appeared earlier in the sequence.
This limitation motivated researchers to design a model that could store important information for much longer periods of time.
Introducing LSTM
Long Short-Term Memory (LSTM) is a special type of recurrent neural network designed specifically to overcome the limitations of standard RNNs.
The key idea behind LSTM is to introduce a memory cell that can preserve information over long sequences.
Unlike a basic RNN, which maintains only a single hidden state, LSTM maintains two types of states:
- Hidden State (Short-Term Memory)
- Cell State (Long-Term Memory)
The cell state acts like a highway through which information can flow with minimal modification, allowing the network to retain important information over long periods.
The Core Idea Behind LSTM
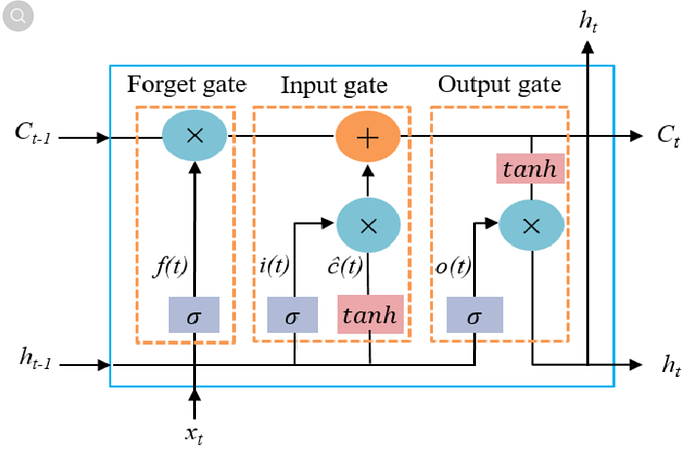
The main innovation of LSTM is the introduction of gates.
These gates control the flow of information and decide:
- What information should be forgotten
- What information should be stored
- What information should be passed to the next step
There are three primary gates in an LSTM cell:
- Forget Gate
- Input Gate
- Output Gate
These gates allow the network to selectively update the memory and retain relevant information over long time spans.
The Forget Gate
The forget gate determines which information from the previous memory should be discarded.
At each time step, the forget gate looks at:
- The current input
- The previous hidden state
Based on these inputs, the gate outputs values between 0 and 1.
- 0 → completely forget the information
- 1 → keep the information
This mechanism allows the network to remove information that is no longer relevant.
For example, if the model initially stores information about a subject in a sentence but later the context changes, the forget gate can remove outdated information.
The Input Gate
The input gate decides what new information should be added to the memory cell.
This process happens in two steps:
- The model identifies which information is important.
- The relevant information is added to the cell state.
This allows the LSTM to update its long-term memory whenever new important information appears in the sequence.
The Output Gate
The output gate determines what information should be passed to the next time step as the hidden state.
This hidden state serves two purposes:
- It is used for making predictions.
- It becomes input for the next time step.
Thus, the output gate controls what part of the internal memory becomes visible to the rest of the network.
How LSTM Maintains Long-Term Memory

The reason LSTM works better than standard RNN is because of its cell state.
Instead of repeatedly transforming the hidden state at every step, LSTM allows information to flow through the cell state with minimal modification.
The gates only add or remove small amounts of information, which prevents the gradients from shrinking too quickly during training.
Because of this design, LSTM can remember relationships that occur many time steps apart, making it effective for long sequences.
Applications of LSTM
LSTM networks have been widely used in many sequence modeling tasks, including:
- Language modeling
- Machine translation
- Speech recognition
- Text generation
- Time series forecasting
Before the rise of Transformer models, LSTMs were the dominant architecture for natural language processing tasks.
Limitations of LSTM
Although LSTM improves upon RNN, it still has some drawbacks:
- The architecture is relatively complex due to multiple gates.
- Training can be computationally expensive.
- The sequential nature of processing makes it difficult to parallelize.
These limitations eventually led to the development of attention mechanisms and Transformer architectures, which we will explore later in this series.
Next Article
In the next article, we will explore the Encoder–Decoder Architecture, which enabled powerful sequence-to-sequence tasks such as machine translation and laid the foundation for modern language models.