
The volume of unstructured data is exploding. While modern cloud databases can store it, they are not designed to effectively understand or search it. Traditional and NoSQL systems manage storage well but struggle to extract meaning from text, images, audio, and video. AI-native databases address this gap by using embeddings and vector search to make unstructured data searchable and useful at scale.
This is where AI-native databases come in. Built specifically for unstructured data, they integrate vector search to help systems understand context and meaning, not just store information. Instead of treating data as static records, these databases interpret semantic relationships, enabling more intelligent, context-aware applications. When I first explored them for our platform, I was impressed by how naturally they handled similarity search and contextual queries, capabilities that would have required significant custom logic in traditional systems.
In this blog, we'll explore the core principles behind vector search and the emerging class of AI-native databases. We'll examine how these systems are architected, the key technologies that power them, and the real-world challenges associated with their deployment. If you've ever tried to make unstructured data searchable beyond simple keywords, this guide will help you understand why vector databases change the game. The transition to AI-native data systems marks a turning point in how we store, retrieve, and interpret information. Grasping how unstructured data is transformed into numerical vector representations is the foundation for understanding this new era of intelligent data management.
Understanding unstructured data and the role of vectors
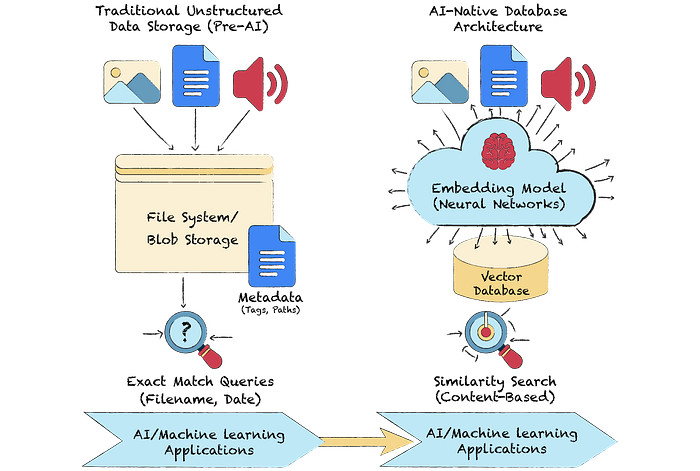
Unstructured data refers to information that lacks a predefined data model or structure. Think of text documents, images, audio files, or videos. In a cloud environment, managing this data with traditional tools is inefficient. The core problem is that relational databases rely on schemas and explicit relationships. Unstructured data has neither.
To solve this, we transform unstructured data into a universal, machine-readable format of vectors. An embedding model processes the raw data and outputs a high-dimensional vector, which is a list of numbers. This vector represents the semantic essence of the data. For example, vectors for "king" and "queen" will be closer in vector space than vectors for "king" and "apple."
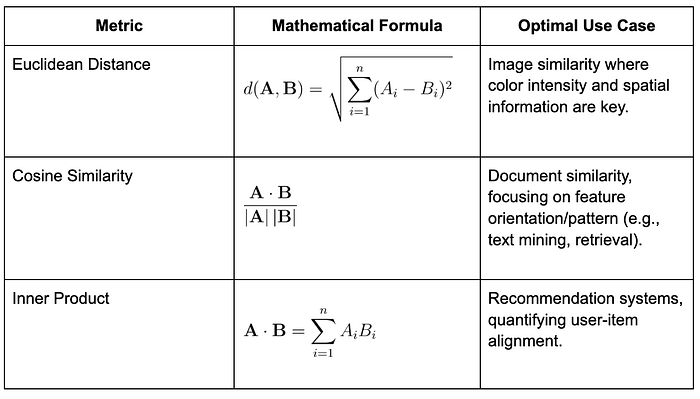
This transformation allows us to perform similarity searches. Instead of matching keywords, we calculate the mathematical distance between vectors. Common metrics include Euclidean distance or cosine similarity. This approach provides context-aware results, which is impossible with keyword-based search. In one of my early prototypes, this difference was striking; searching for "project delays" surfaced related records about "timeline risks" that the keyword search completely missed. It moves us from simple pattern matching to genuine semantic understanding.
Note: The dimensionality of a vector is a critical parameter. Higher dimensions can capture more nuance, but they also increase computational overhead. Choosing the right dimension is a key architectural trade-off. In practice, we found that 384–768 dimensions provide a good balance for most text-based applications.
The following pipeline is the foundation of modern search and recommendation systems.

With a clear understanding of the data transformation process, we can now examine the internal components that enable these databases to function effectively.
Building an AI-native application: a technical blueprint
Now that we understand how unstructured data is transformed into vectors, we can examine how these elements fit together in a real-world system. Building an AI-native application typically follows five main stages:
- Data ingestion: Unstructured data, such as documents, images, or audio files, is collected from multiple sources and stored in an object store, like Amazon S3 or Google Cloud Storage. Along with the content, metadata is stored for tracking, versioning, and retrieval.
- Embedding generation: The raw data is processed by an embedding model, such as CLIP, which can generate embeddings for both text and images. This model converts the input into high-dimensional vectors that represent its semantic meaning. Each vector becomes a numerical fingerprint of the original data. We initially used a pretrained model, but some domain-specific terms weren't captured well, so we fine-tuned the embeddings on our dataset. That small adjustment drastically improved similarity precision.
- Vector indexing: To make similarity search efficient, these vectors are organized using an Approximate Nearest Neighbor (ANN) algorithm. A widely used method is Hierarchical Navigable Small World graphs (HNSW), which creates a layered graph structure that enables fast lookups even across millions of vectors.
- Query and retrieval: When a query is made, whether text, image, or audio, it is also converted into a vector. The system compares this query vector to those in the index using similarity metrics such as cosine similarity or Euclidean distance. The closest vectors represent semantically related content. The three most common metrics are:
5. Application integration: The retrieved results are passed to the application layer, which may display recommendations, provide search results, or feed downstream AI tasks. This is where semantic understanding is translated into user-facing intelligence.
This blueprint illustrates the data flow within an AI-native database, from ingestion to insight. Each stage introduces its own tuning challenges; batch size, index refresh intervals, and query latency thresholds can dramatically affect the user experience. Each layer can be independently optimized for performance, accuracy, or scalability, depending on the application's goals.
Indexing algorithms and vector search performance
Performance in vector search hinges on efficient indexing. A brute-force search, comparing a query vector to every other vector in a dataset, is not viable at scale. We need faster methods. This is where Hierarchical Navigable Small World (HNSW) algorithms become essential. Tuning HNSW parameters was challenging; having too many connections slowed ingestion, while having too few reduced recall. Running controlled tests on a few thousand vectors helped us find the balance before scaling to millions.
HNSW is a prominent and effective strategy. It constructs a multi-layered graph of vectors, allowing for rapid traversal to find approximate nearest neighbors with high accuracy and low latency. The process is systematic.
- Embedding generation: Unstructured data is converted into vector embeddings.
- Index construction: The embeddings are organized into an HNSW graph. This is the one-time cost to enable fast lookups.
- Query execution: An incoming query is converted to a vector. The HNSW graph is then traversed to find the most similar vectors in the index.
Real-world benchmarks demonstrate that HNSW-based indexing scales. It maintains low-latency query performance even as datasets grow to billions of vectors. In one of our tests, latency stayed under 15 ms for a million vectors, well within interactive thresholds. Scalability is crucial for real-time applications, such as recommendation engines and interactive search platforms, where users expect instant responses.
Note: The trade-off with HNSW and other approximate nearest neighbor (ANN) algorithms is between speed and accuracy. You can tune parameters to favor one over the other, but you rarely get both perfectly. Always measure your application's tolerance for approximation before deploying in production.
Here is a simplified comparison of common indexing strategies.

Comparative review of database solutions
Choosing a vector database solution requires a clear-eyed assessment of trade-offs. The right choice depends entirely on your specific requirements for scalability, integration, and operational overhead. The landscape is generally divided into open-source solutions and managed services.
Open-source databases offer flexibility and control but require self-management for scaling and maintenance.
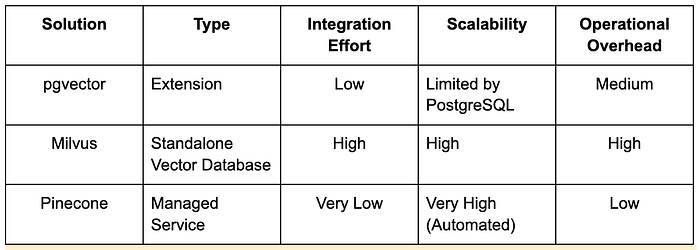
- pgvector: An extension for PostgreSQL that adds vector similarity search. It is a good choice for teams already running on a PostgreSQL stack who want to add vector capabilities without introducing a new system.
- Milvus: A purpose-built, open-source vector database designed for scalability. It can handle massive datasets and is architected for high performance from the ground up.
- CrateDB: A distributed SQL database that supports full-text search and vector search capabilities. It offers a balance between traditional database features and AI-native functionality.
Managed vector databases simplify scaling and operations, letting teams focus on application logic instead of infrastructure.
- Pinecone: A fully managed vector database service. It handles the operational complexity of scaling, updates, and maintenance, allowing teams to focus on application logic.
- Weaviate: The managed version of Weaviate offering built-in APIs, schema management, and hybrid search. It integrates easily with existing ML pipelines for semantic applications.
- AWS Kendra: A managed semantic search service that supports embeddings and natural language queries. It's suited for enterprise document search and knowledge management.
Making a decision requires analyzing the trade-offs. Managed services offer ease of use and seamless scaling, but at the cost of less control and potentially higher expense. Open-source solutions offer maximum control and flexibility, but they require more engineering effort to deploy, integrate, and maintain. In our own evaluation, pgvector was quick to set up, but Milvus delivered better throughput at higher data volumes. Pinecone simplified scaling the most, but at a premium cost. There is no single right answer, only the best fit for your use case.
CTO tip: When evaluating, measure performance on a representative sample of your own data. Generic benchmarks are a starting point, but they don't reflect your specific workload and data distribution.
Practical code example and implementation
A practical example helps solidify the concepts. This Python code demonstrates a basic semantic search workflow using faiss, a library for efficient similarity search.
import faiss
import numpy as np
# Generate 1000 random 128-dimensional vectors
data_vectors = np.random.random((1000, 128)).astype('float32')
# Initialize a flat (exact) L2 index for 128-dimensional vectors
faiss_index = faiss.IndexFlatL2(128)
# Add the random vectors to the FAISS index
faiss_index.add(data_vectors)
# Create a random 128-dimensional query vector
query_vector = np.random.random((1, 128)).astype('float32')
# Search the index for the 5 nearest neighbors of the query vector
distances, neighbor_indices = faiss_index.search(query_vector, 5)
# Output the indices of the top 5 nearest neighbors
print(neighbor_indices)This example illustrates the core steps: creating data, building an index, and executing a query. This example strips away the complexity of a full production system to show the essential logic. While the implementation can be simple, we must not overlook the security implications of managing this type of data.
Scalability, security, and compliance challenges in vector databases
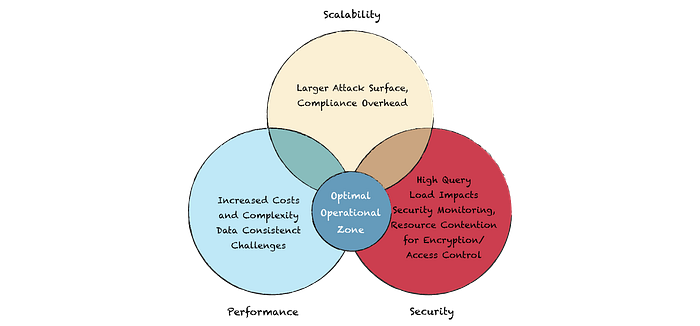
Deploying an AI-native database in production introduces unique challenges around scalability, security, and compliance. These systems must scale efficiently across both data volume and query load while maintaining low latency. Distributed architectures, sharding, and replication help achieve horizontal scalability, but they also increase operational complexity.
Security and compliance cannot be afterthoughts. Data should be encrypted at rest and in transit, access should be tightly controlled, and networks should be properly isolated. During a security audit, we discovered that even anonymized vectors could leak user behavior patterns; therefore, we now treat embeddings with the same sensitivity as the original data.
Recent innovations and the future of AI-native databases
AI-native databases continue to evolve, with hybrid search emerging as a key advancement that blends keyword precision with vector-based contextual understanding. We are also seeing continuous innovation in indexing algorithms. New ANN structures are being developed that offer better trade-offs between speed and accuracy, or are optimized for specific hardware. Another key area is automated data governance. Emerging tools now automatically flag drift in embedding distributions, ensuring model quality stays consistent without manual monitoring.
The future points toward a deeper integration of AI-native capabilities into the entire data stack. These databases will not be standalone systems but integral components of a unified cloud data platform, capable of handling any data type and supporting massive, real-time AI workloads.
Practical considerations for cloud adoption
AI-native databases are a fundamental shift in how we manage and query unstructured data in the cloud. They move us beyond simple storage and retrieval to a new paradigm of semantic understanding. By leveraging vector search, we can build more intelligent, context-aware applications.
For technical leaders planning to adopt this technology, the decision requires careful evaluation. Before you commit to a solution, assess the following:
- Performance: Does the database meet your latency and throughput requirements?
- Scalability: Can it grow with your data and query volume? What is the operational cost of scaling?
- Security: Does it provide the necessary features to protect your data?
- Cost: What is the total cost of ownership, including licensing, infrastructure, and operational overhead?
Start small by building a proof of concept on a subset of your data before scaling it up. Measure query latency, tune your embeddings, and track cost growth early.