


Introduction
Retrieval-Augmented Generation (RAG) has quickly become a buzzword in the AI community, often used in so many different contexts that its meaning can seem unclear. Yet, at its heart, a RAG system is built on a simple recipe: documents, an embedding model, a vector database, and a large language model (LLM). Like any good recipe, swapping out or tweaking one of these ingredients can result in a distinctly different flavor, like introducing a graph database to get GRAGs, but the core concept remains the same.
Setting up a basic RAG system is simple, but creating a satisfactory solution requires the generation of complete and contextually rich responses. It demands careful refinement and, crucially, a way to measure how well the system performs in real-world scenarios.
In this article, we'll dive into an essential step in crafting an effective RAG-based solution: ranking models to elevate the quality of your solutions' outputs. Whether you're fine-tuning for accuracy, completeness, or user satisfaction, reranking models offer a way to ensure your RAG system performs according to expectations.
The limitation of embeddings
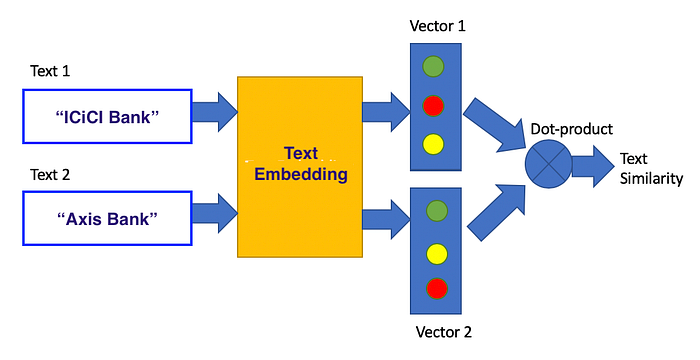
Embeddings are mathematical representations that map words, phrases, or even entire documents into continuous vector spaces, capturing their semantic meaning in a form that machines can easily process. Once generated, embeddings serve multiple purposes in AI and information retrieval.
They are used to improve search engine accuracy, enable question-answering systems, facilitate natural language understanding, and support tasks like text classification and sentiment analysis. Understanding their limitations is crucial for optimizing systems like Retrieval-Augmented Generation (RAG) and other search technologies.
- Fixed Representations: Traditional embeddings often assign a single vector representation to a word or document, regardless of the context in which it appears. This can lead to oversimplification, especially for words with multiple meanings (e.g., "bank" as a financial institution vs. the side of a river). While contextual embeddings like BERT have improved upon this, they still struggle to fully capture dynamic context shifts, especially when the context changes dramatically from training data scenarios.
- Generalization Issues: Embedding models can face significant challenges when encountering out-of-vocabulary terms — words or phrases that were not seen during training. This limits the model's ability to adapt to new or evolving language, often requiring costly retraining or fine-tuning on domain-specific data to maintain performance. Additionally, embeddings trained on one domain may perform poorly when applied to another, as they reflect the statistical patterns of the training data and may not generalize well to different contexts.
- Scalability Concerns: As data grows in size and complexity, the performance of embedding-based models can degrade. Managing and retrieving high-dimensional vectors from large-scale datasets can become computationally expensive and slow. This is particularly challenging in real-time applications, where latency is critical. Vector databases help mitigate some of these issues but come with their own set of challenges regarding efficient storage and retrieval at scale.
- Bias in Embeddings: Embedding models are often trained on vast, uncurated datasets, which means they can unintentionally absorb and perpetuate biases present in the data. This can lead to problematic outputs that reflect societal biases, making it essential to carefully evaluate and mitigate these biases, especially in sensitive applications like healthcare or law.
- Loss of Contextual Nuance: Even advanced models like BERT or GPT-based embeddings can struggle with maintaining nuanced understanding across longer texts or complex queries. The compression of text into vectors inevitably results in a loss of some information, which can lead to less accurate or less relevant retrieval, especially when fine-grained context is crucial.
These reasons are why rerankers are often employed to refine results further by evaluating the contextual fit more deeply than embeddings alone.
Breaking down rerankers: structure and functionality
To tackle the inherent limitations of embedding-based retrieval, rerankers bring a fresh approach to ranking that enhances the quality of search results. By going beyond vector-based retrieval, they are designed to capture nuanced relationships between queries and documents. Let's break down their structure and functionality to understand how they effectively bridge the gap left by traditional embeddings.
Rerankers are typically neural models structured to operate as cross-encoders or bi-encoders with an additional scoring mechanism, differing fundamentally from standard vector-based retrieval models like bi-encoders used in initial search stages.
Cross-encoders are the backbone of most rerankers. In a cross-encoder architecture, the query and each document are input together into the model, which processes them simultaneously rather than independently. This simultaneous processing allows the reranker to capture intricate semantic relationships between the query and the document that traditional embedding-based methods might miss. For example, models like BERT are often fine-tuned for reranking tasks by jointly encoding the query and document to directly produce a relevance score. This score quantifies how well the document satisfies the information need expressed by the query.
Unlike bi-encoders, where embeddings are precomputed for both the query and document, cross-encoders execute a full transformer pass for each query-document pair at inference time. This allows for deeper contextual analysis but introduces higher computational costs. The entire text of the query and the document is concatenated and passed through layers of self-attention, which enables the model to weigh every word of the query against every word of the document, making it adept at understanding context-sensitive and nuanced language.
Some rerankers, like ColBERT (Contextualized Late Interaction over BERT), introduce a unique mechanism called late interaction, where the query and document are processed independently up to the last stage. In this architecture, the query and document are first encoded separately using BERT, creating embeddings for each term. The reranker then performs a lightweight interaction step that compares these embeddings, allowing for fine-grained evaluation without the need for reprocessing the entire document set on every query. This late interaction balances efficiency and effectiveness, maintaining the expressiveness of deep learning models while reducing computation time by only performing heavy calculations on the final interaction step.
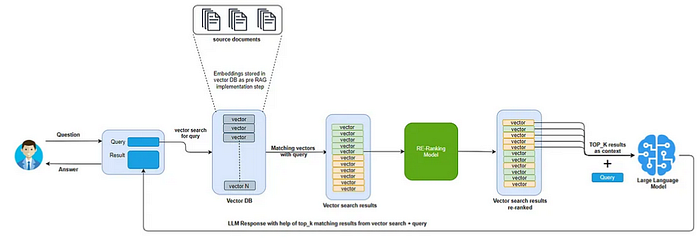
In two-stage retrieval systems, rerankers refine the initial retrieval results. The first stage, often based on approximate nearest neighbor (ANN) searches or keyword-based methods, quickly retrieves a broad set of candidate documents. The reranker then analyzes these candidates more deeply, reordering them based on complex contextual factors that are not captured during the initial retrieval phase. This process ensures that the reranker optimizes the order of results, bringing the most relevant documents to the forefront.
Current State: Models, performance, and trends
The reranking landscape in information retrieval has evolved significantly, with continuous advancements in model architecture and performance optimizations. With this section I want to provide an overview of the latest models, performance comparisons, and emerging trends, highlighting the strengths and challenges of current reranking approaches.
Models in Use: Key players and their capabilities
Several reranking models are at the forefront of current information retrieval systems, each tailored to enhance the quality of search results beyond initial retrieval:
- BERT-based Rerankers: These rerankers are widely used for their deep bidirectional context understanding, allowing them to capture nuanced relationships between queries and documents. BERT's strong performance has made it a standard benchmark for reranking tasks, balancing accuracy and computational cost.
- ColBERT (Contextualized Late Interaction over BERT): ColBERT utilizes a late interaction mechanism that separates query and document processing until the final scoring step, optimizing both accuracy and speed. It is particularly favored in scenarios requiring high throughput and minimal latency while retaining the depth of semantic understanding.
- T5 and GPT-based Rerankers: Transformer-based models like T5 and GPT are increasingly being adapted for reranking. These models excel at generating deep contextual embeddings and have been fine-tuned specifically to understand complex document-query relationships, making them highly effective in diverse retrieval tasks.
- Jina Rerankers: The latest Jina models, including the Turbo and Tiny variants, have streamlined architectures that significantly reduce parameter size and computational overhead. Turbo uses six layers with 37.8 million parameters, while Tiny goes even further with four layers and 33 million parameters. These models offer near-comparable accuracy to larger models but with drastically improved speed, making them suitable for applications needing quick responses.
- BAAI Rerankers: Models like
bge-reranker-largefrom the Beijing Academy of Artificial Intelligence are notable for their multilingual support and optimization for various retrieval tasks, showing strong adaptability in both standard and niche contexts.
Key evaluation metrics
How do we measure the effectiveness of these models? Evaluating rerankers involves specific metrics that capture how well they enhance the retrieval process. The evaluation process often relies on metrics like Mean Reciprocal Rank (MRR), Normalized Discounted Cumulative Gain (NDCG), and Hit Rate, each chosen for their specific strengths in capturing how well reranking models prioritize relevant results.
- NDCG: It evaluates the usefulness of documents based on their positions in the ranked list, giving higher scores when relevant documents appear earlier. It accounts for the graded relevance of documents rather than treating relevance as a binary measure (relevant or not relevant). It is favored for its ability to handle graded relevance, making it particularly suitable for complex retrieval tasks where not all relevant documents are equally valuable. It is robust in evaluating the quality of reranked lists, providing insight into how well a model captures the overall relevance distribution.
- Hit rate: It measures the frequency with which relevant documents appear within the top k results of a ranked list. It's a straightforward metric that shows the probability of encountering at least one relevant result within a specified number of retrieved documents. Hit Rate is simple to interpret and provides immediate insight into a model's ability to consistently include relevant documents within the most viewed results. It's particularly useful in fast-paced applications like real-time search and recommendation engines, where users engage primarily with the top results. This metric is often used in conjunction with others to highlight scenarios where getting a relevant result within the top few documents is crucial.
- MRR: It measures how quickly the correct answer appears in the ranked list of results by calculating the reciprocal of the rank at which the first relevant document appears for a given query, averaging this value over multiple queries. MRR is especially valuable in information retrieval and reranking because it emphasizes the importance of placing relevant results at the top of the list. For rerankers, which aim to reorder initial search results, MRR directly reflects how well the model prioritizes the most relevant documents.
Benchmarks and real-world evaluations
While these metrics provide valuable insights into how rerankers prioritize results, their true effectiveness is best understood through real-world evaluations and benchmarks. Recent studies on popular datasets such as BEIR and CodeSearchNet offer a detailed look at how different reranking models perform across various tasks. Let's explore these benchmarks to see how the models stack up in practice.
- Efficiency vs. Accuracy Trade-offs: Larger rerankers, such as BERT-based models, consistently rank higher in metrics like MRR and NDCG compared to smaller, faster models like Jina Reranker Turbo. However, Turbo achieves approximately 95% of the base model's performance while being three times faster, highlighting the trade-offs between size, speed, and precision.
- Evaluation Metrics: Key metrics such as Hit Rate and NDCG demonstrate how rerankers like
CohereRerankandJina Reranker v2outperform traditional retrieval methods. These metrics reflect the models' ability to correctly reorder search results, making them particularly valuable in applications where query precision is critical. - Specialized Performance: Some rerankers are designed for specific tasks, such as multilingual retrieval or dense passage retrieval. Models like
ms-marco-MiniLM-L-6-v2andbge-reranker-largeshowcase specialized capabilities, performing exceptionally well on targeted benchmarks like BEIR, which includes tasks ranging from question-answering to document retrieval.
Challenges and optimization strategies
Despite the advances, rerankers face ongoing challenges, primarily related to their computational demands:
- Latency and Computational Overhead: One of the main challenges with neural rerankers, especially cross-encoder types, is the increased response time due to the need for real-time inference on each query-document pair. This latency can be a bottleneck in high-traffic systems. Models like
Jina Reranker Turboaddress this by reducing model complexity while maintaining high accuracy. - Scalability and Cost: Running rerankers at scale can be expensive due to their high computational requirements. Emerging models are focusing on optimizing this trade-off by incorporating techniques like knowledge distillation, which allows smaller models to mimic the performance of larger counterparts with much lower costs. For example, Jina's Turbo and Tiny models are trained using distillation from larger base models, maintaining performance quality with fewer resources.
- Flexibility and Adaptability: Modern rerankers are becoming increasingly modular, with frameworks like Hugging Face Transformers and APIs such as Jina Reranker allowing easy integration into existing pipelines. This flexibility helps teams adapt rerankers to specific use cases and continuously refine their performance based on real-world feedback.
Conclusions
Today's rerankers blend cutting-edge neural networks with smart design choices like late interaction and knowledge distillation, making them faster, leaner, and more adaptable than ever. Models like Jina Turbo and Tiny prove that you don't need a bulky architecture to achieve top-tier performance; you just need the right approach. As these models continue to evolve, they are redefining what's possible, striking a balance between speed, cost, and quality that keeps us moving forward.
Looking ahead, rerankers will be the unsung heroes behind the scenes of every great search experience, quietly ensuring that the right answers are always just a query away. They are not just enhancing how we interact with information: they're shaping the future of intelligent systems. As the demand for smarter, faster, and more reliable AI solutions grows, rerankers will remain at the heart of the conversation, powering the next wave of innovation in information retrieval.
Bibliography
- Beijing Academy of Artificial Intelligence (BAAI). (2024). Bge-reranker-base. Hugging Face. https://huggingface.co/BAAI/bge-reranker-large
- Gong, Y., Cosma, G., & Fang, H. (2021). On the limitations of visual-semantic embedding networks for image-to-text information retrieval. Journal of Imaging, 7(8), 125. https://doi.org/10.3390/jimaging7080125
- Jina AI. (2024). Smaller, faster, cheaper: Introducing Jina rerankers Turbo and Tiny. Jina AI. https://jina.ai/blog/jina-rerankers-turbo-tiny-performance
- LlamaIndex. (2024). Boosting RAG: Picking the best embedding & reranker models. LlamaIndex. https://www.llamaindex.ai/rag-best-embedding-reranker
- Zilliz. (n.d.). Harnessing embedding models for AI-powered search. Zilliz Blog. https://zilliz.com/blog/harnessing-embedding-models
- Galileo. (n.d.). Mastering RAG: How to select a reranking model. Galileo. https://www.rungalileo.io
- Association of Data Scientists. (n.d.). How to select the best re-ranking model in RAG? ADASCI. https://adasci.org