Machine learning models often feel like black boxes. But once trained, many models — especially in supervised learning — can be expressed as nothing more than matrix multiplications and vector additions. This isn't just a theoretical convenience. It makes inference fast. Matrix operations are the backbone of modern computing hardware, optimized in GPUs, TPUs, and even low-power edge devices.
When we convert a trained model into a sequence of linear algebra steps, we can strip away unnecessary computation and reduce the entire prediction process to simple, fast operations. This is especially critical for serving models at scale, deploying to mobile or embedded environments, or optimizing inference pipelines.
Let's walk through some common models that can be rewritten as pure linear algebra. We also explain why this matters and how it helps us make predictions quickly in production environments.
Linear Models: From Equation to Matrix
Let's start with linear regression. Suppose we have a model:
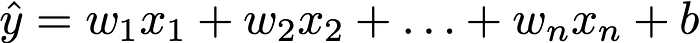
We can rewrite this more compactly using vector notation:

Or in matrix form for multiple predictions at once:
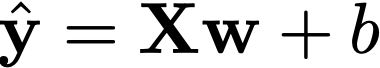
Where:
- X is an m×n matrix of input data (m examples, n features)
- w is an n×1 weight vector
- b is either a scalar or broadcasted vector
This form is extremely efficient: a single matrix multiplication and an addition.
Logistic Regression and Sigmoid Output
Logistic regression adds a non-linearity at the end:

Where this is the sigmoid function.
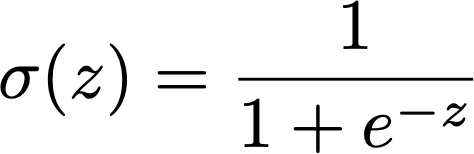
Inference still boils down to computing Xw+b, followed by applying σ elementwise. The heavy lifting is still matrix multiplication.
Multiclass Classification with Softmax
For k classes, we extend the idea with a weight matrix W of size n×k:

This is a single matrix multiply and a row-wise softmax. Again, vectorized and fast.
This same concept holds true for much fancier things like neural networks.
Speed, Portability, and Deployment
Rewriting models as linear algebra gives us major benefits. 1/Speed: Matrix operations are massively parallel. GPUs and TPUs run them natively. Inference is orders of magnitude faster than looping through equations. 2/Portability: Once converted, a model can be exported to ONNX or TensorRT, or embedded in a mobile app with CoreML or TFLite — all of which assume a linear algebra backbone. 3/Interpretability: For linear models, the weight matrix can be inspected to understand feature importance. 4/Simplicity: A model is just a sequence of tensors. We can cache, quantize, or prune them without changing the logic.
From Model to Matrix
Most modern frameworks already expose this capability:
- scikit-learn:
.coef_and.intercept_for linear/logistic models - PyTorch: Export layers as
.weightand.biastensors - TensorFlow/Keras: Use
.get_weights()to retrieve matrices - ONNX Runtime: Loads model graphs already compiled into matrix ops
You can also convert entire pipelines to optimized matrix graphs using libraries like ONNX, TorchScript, or TensorRT.
Batching for Fast and Scalable Inference
Matrix operations are efficient because they operate on whole batches of inputs at once. Batching is the process of stacking multiple input examples into a single matrix, allowing all predictions to be made in parallel with a single matrix multiplication. Instead of predicting one input at a time, we bundle many inputs into a matrix.
This approach scales naturally. Whether you're making 10 or 10,000 predictions, the same code applies. Let's walk through how batching works in practice for each type of model.
Linear and Logistic Regression Batching Example
import numpy as np
from sklearn.linear_model import LogisticRegression
from scipy.special import expit
# Simulate training
X_train = np.random.randn(100, 3)
y_train = (X_train @ np.array([0.5, -1.2, 2.0]) + 0.3 > 0).astype(int)
model = LogisticRegression().fit(X_train, y_train)
# Extract weights
w = model.coef_.flatten()
b = model.intercept_[0]
# Batch inference on multiple rows
X_batch = np.array([
[0.1, -0.2, 0.3],
[1.5, 2.3, -1.4],
[0.0, 0.0, 0.0]
])
# Vectorized inference
z = X_batch @ w + b
probs = expit(z)
print("Batch predictions (probabilities):", probs)This will output a vector of predicted probabilities, one for each row of X_batch. All predictions are computed at once.
Neural Network Batching Example
import torch
import numpy as np
# Reuse trained model from earlier
model.eval()
# Batch of new inputs
X_batch = np.array([
[2.0, 3.0],
[3.0, 4.0],
[4.0, 5.0]
])
# Inference using PyTorch (batch-aware)
with torch.no_grad():
X_tensor = torch.tensor(X_batch, dtype=torch.float32)
predictions = model(X_tensor)
print("Batch predictions (NN):", predictions.numpy().flatten())This example uses PyTorch to make predictions on a batch of 3 inputs. Internally, it performs all matrix multiplications and activations in a batched fashion. This is significantly faster than looping through inputs one by one — especially when running on GPU.
This brings benefits in:
- Performance: Batching reduces overhead. Instead of repeating weight access and matrix initialization for each input, you perform one large matrix operation.
- Parallelism: GPUs process thousands of operations in parallel. Batching maximizes throughput by aligning your operations with the architecture.
- Scalability: Modern serving frameworks like TensorFlow Serving, TorchServe, Triton, and ONNX Runtime automatically batch inputs before dispatching them to the inference engine.
Batching is the expected format for efficient model deployment. Whether you're running a REST API for predictions or serving a real-time recommender, always structure your inference pipeline to operate on batches.
So What?
At inference time, models are no longer learning. They are applying known weights. This makes it possible to reframe any model — from linear regression to deep neural nets — as a composition of matrix multiplications and activations. Understanding this unlocks faster inference, better deployment, and clearer thinking.
When you strip it down, all models become math. And all math becomes fast with linear algebra. (check out "and the rest is just algebra" by Sepideh Stewart)