
Introduction
Deploying Large Language Models (LLMs) isn't just about choosing the right model it's about ensuring you have the right hardware to run it efficiently. A crucial factor in this process is GPU memory, as it directly impacts the model's performance, speed, and feasibility in production.
Whether you're working with a model with billions of parameters or something even more complex, understanding how much GPU memory is required can prevent crashes, slowdowns, and unnecessary costs. The good news? There's a straightforward way to estimate memory needs, which we'll break down in this article.
Here's what you'll learn:
- How GPU memory is allocated when serving LLMs
- A simple formula to estimate memory requirements
- A practical example with a 7B parameter model
- The importance of overhead in calculations
- Techniques to optimize memory usage
- How to choose the right GPU for different model sizes
By the end, you'll have a solid understanding of GPU memory requirements and actionable strategies for efficient LLM deployment. Let's dive in!
Understanding GPU Memory Requirements for LLMs
Serving an LLM requires GPU memory to store the model weights, intermediate computations, and additional overhead for efficient processing.
Here's a simple formula that helps estimate the GPU memory required:
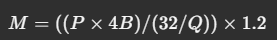
Where:
- M = Required GPU memory in gigabytes (GB)
- P = Number of parameters in the model
- 4B = 4 bytes per parameter (since most models use FP32 or FP16 precision)
- Q = Number of bits per parameter when loading the model (e.g., 16-bit for FP16, 8-bit for quantized models)
- 1.2 = A 20% overhead factor
Breaking It Down in Simple Terms
To serve a model efficiently, you need to store the following in memory:
- Model Parameters — These are the "learned weights" of the model.
- Intermediate Computations — Temporary memory used for inference calculations.
- Overhead — Additional memory for efficient data movement and parallel processing.
Now, let's put this formula into action.
Example Calculation: How Much Memory Does a 7B Parameter Model Need?
Let's assume:
- P = 7 billion (7B) parameters
- Q = 16-bit precision (FP16)
Plugging these into our formula:
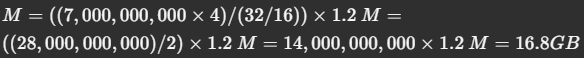
So, you would need at least 16.8GB of GPU memory to serve a 7B parameter model in FP16 precision.
However, if you were using a quantized 8-bit model (Q = 8), the required memory would be half, around 8.4GB.
Why the 20% Overhead?
The 1.2 multiplier (20% overhead) in our formula is not just an arbitrary number — it plays a crucial role in ensuring smooth model inference. But why exactly do we add 20%, and not 50% or some other number? Let's break it down.
1. Memory Fragmentation
When loading a model, GPU memory is allocated in chunks, but it is rarely packed perfectly. Some memory gets wasted due to fragmentation, meaning the actual usable memory is slightly less than the total available VRAM. The 20% buffer accounts for this inefficiency.
2. Activations & Intermediate Results
During inference, the model doesn't just store weights — it also generates intermediate calculations known as activations. These activations require additional memory, and the larger the model, the more memory they consume.
3. Efficient GPU Utilization
Modern GPUs reserve a portion of VRAM for system-level operations, kernel execution, and CUDA-related processes. If we allocated 100% of the memory to the model, it could lead to instability or crashes. The extra 20% ensures that the GPU has the flexibility to handle these operations without running out of memory.
Why Not 50%?
A 50% buffer would be excessive in most cases, leading to wasted GPU resources. The 20% rule strikes a balance between ensuring stability and maximizing available memory for the model. However, if you're running very large models with complex processing needs (e.g., multi-modal models with vision components), you might need a higher buffer.
Optimizing Memory Usage for LLM Deployment
If your GPU doesn't have enough memory, you have a few options:
1. Model Quantization
- Convert your model to 8-bit or 4-bit precision to reduce memory usage.
- Tools like bitsandbytes or GPTQ help achieve this.
2. Offloading to CPU/RAM
- If your GPU has limited memory, offload part of the model to CPU RAM.
- Frameworks like DeepSpeed and Hugging Face Accelerate help with this.
3. Multi-GPU Parallelism
- Use tensor parallelism to split the model across multiple GPUs.
- This allows larger models to run efficiently without a single GPU bottleneck.
4. Choose the Right GPU
- If serving models above 13B parameters, consider GPUs with 24GB+ VRAM, like the NVIDIA A100, H100, or RTX 4090.
- For small-scale LLMs (7B and below), a 16GB VRAM GPU (like an RTX 4080) may suffice.
Final Thoughts
Understanding GPU memory requirements for serving LLMs is not just an interview question — it's a real-world necessity. The next time you're deploying a model or answering this in an interview, you'll have the exact math to back up your answer.

- A 7B parameter model in FP16 needs ~16.8GB of VRAM.
- Optimize memory using quantization, CPU offloading, or multi-GPU setups.
- Choose GPUs based on model size: 16GB VRAM for small models, 24GB+ for large models.
The better you understand these numbers, the more confident you'll be in optimizing and deploying LLMs in production!