
The Democratization of AI Interpretability
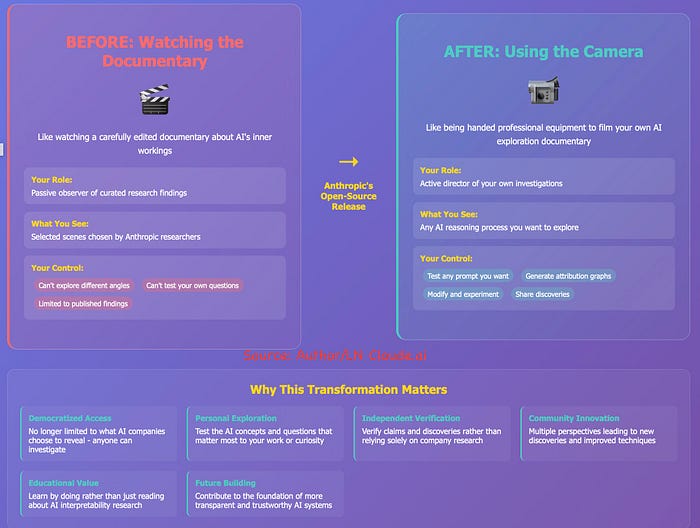
In my previous article, "Understanding Anthropic's AI Interpretability Through Movie Making," I explored how Anthropic's researchers were examining AI internal mechanisms using circuit tracing — comparing it to the behind-the-scenes process of filmmaking. We discussed how language models plan ahead when writing poetry, process multiple languages through a conceptual space, and sometimes generate explanations that don't match their actual computational process. Like film critics watching a documentary about movie production, we could observe AI researchers revealing glimpses of the model's internal processing, but couldn't venture onto the set ourselves.
Now, Anthropic has taken an important step forward by extending its open-source tools, and making them available to researchers, developers, and curious minds. This is like moving from watching a documentary about filmmaking to being handed a professional camera and granted access to the set. Now anyone can direct their own explorations into AI's internal workings.
Why does this matter? Because until now, we've often had to rely on AI companies' explanations of how their models function internally. These new tools help open up the "black box" of AI, with significant implications for transparency, trust, and safety research.
The Open-Source Release of AI Interpretability Tools
Anthropic just announced the release of their circuit tracing tools, as a addition to their existing set of open source tools.
The open-source release includes two main components:
- The circuit-tracer library: A Python package that allows researchers and developers to generate attribution graphs, perform interventions, and analyze model behavior at a mechanistic level.
- Neuronpedia integration: A web-based interface that makes circuit tracing more accessible, allowing users to generate and explore attribution graphs without writing code.
According to Anthropic's announcement, these tools work with certain open-source models (currently Gemma-2 2B and Llama-3.2 1B), which means both the models and interpretability tools are available for public use and scrutiny. (one can request more models here for neuronpedia.org, though)
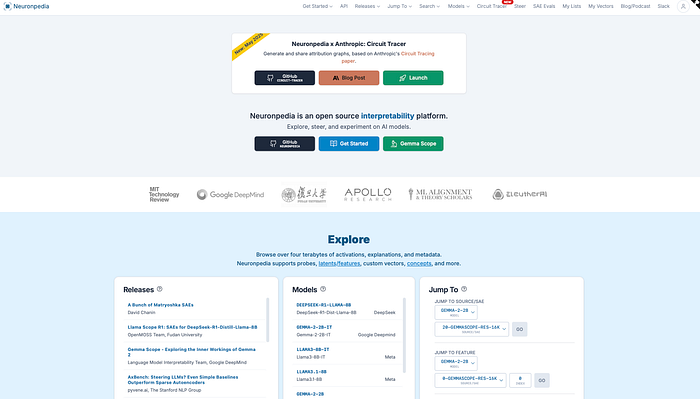
Neuronpedia: A Gateway to AI's Internal Workings
For those with a intermediate technical background in machine learning, Neuronpedia offers an approachable entry point into AI interpretability. Think of it as a visualization tool for AI's internal processes — a way to explore the patterns and connections that form when a language model processes information.
Getting Started with Neuronpedia
Getting started is relatively straightforward:
- Visit Neuronpedia: Navigate to neuronpedia.org in your web browser (Chrome, preferably).
- Launch Circuit Tracer: Look for the "Neuronpedia x Anthropic: Circuit Tracer" section and click "Launch."
- Choose a Model: Select a supported model like "GEMMA-2–2B-IT" from the dropdown menu.
- Enter a Prompt: Type any question or request you're curious about. For your first exploration, try something simple like "What is the opposite of small?"
- Generate and Explore: After processing (which may take a few moments), you'll see a visualization of the model's internal computation — the attribution graph.
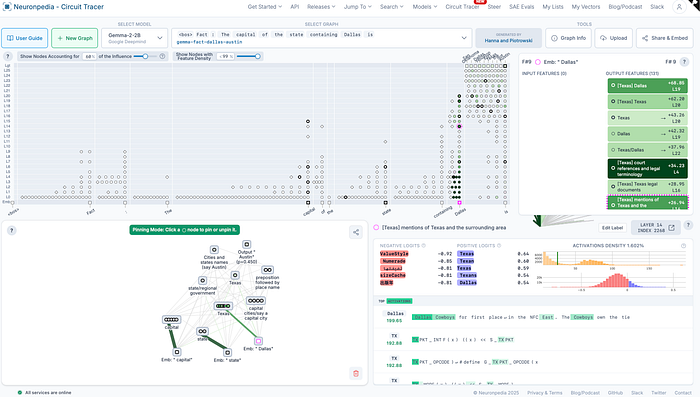
Reading Your First Attribution Graph
When you first see an attribution graph, it might appear a bit daunting— a web of nodes and connections that resembles a complex circuit diagram. Here's how to make sense of it:
- Input tokens (usually on the left): These represent the words in your prompt.
- Feature nodes (in the middle): These are the "concepts" or internal representations that activate in the model.
- Output tokens (usually on the right): These show the model's response or next predicted words. The graph typically displays the top candidate tokens that together account for 95% of the model's probability distribution. Each output node shows a percentage indicating how likely the model thinks that word should be next.
- Arrows: These show how information flows, with thicker or more colorful arrows indicating stronger influences.
The power of these graphs is in seeing which internal features lead to which output tokens. For example, if the output node "Austin" has strong connections from both a "Texas" feature and a "capital city" feature, you can infer that the model chose this word because it recognized both concepts and connected them appropriately.
You can hover over nodes to see details about them. Some feature nodes might have human-readable labels if they've been identified by researchers (like "concept: animal" or "grammar: plural form").
Interesting Prompts with Pre-Generated Graphs
Neuronpedia already has several fascinating attribution graphs you can explore without having to generate them yourself. Here are some particularly insightful examples:
- Multilingual processing: Compare the graphs for "What is the opposite of small?" in English, French ("Quel est le contraire de petit?"), and Chinese ("小的反义词是什么?") to see shared concept nodes across languages.
- Rhyme planning: Examine "Write a couplet where the second line rhymes with 'cat'" and observe evidence that the model plans the rhyme before generating the second line.
- Math computation: Study "What is 36 + 59?" to see the parallel pathways for approximation and exact digit calculation.
- Multi-step reasoning: Look at "What is the capital of the state where Dallas is located?" and trace how it connects Dallas→Texas→Austin, as shown in the screenshot above.
- Entity recognition: Compare "Who is Michael Jordan?" with "Who is Michael Batkin?" (a fictional person) to see how the model handles known vs. unknown entities.
What Can We Learn From Looking Inside?
Let's walk through tracing a prompt : "How can one apply Karma Yoga in their daily professional lives?"
When we trace this prompt through a language model's processing, we might observe several interesting patterns:
- First, features activating for "Karma Yoga" (a spiritual/philosophical concept) and "professional lives" (workplace context) separately.
- Then, internal connections to features representing core principles of Karma Yoga, such as "selfless service," "duty without attachment to rewards," and "ethical work."
- Finally, pathways leading to output tokens that form practical suggestions for workplace application.
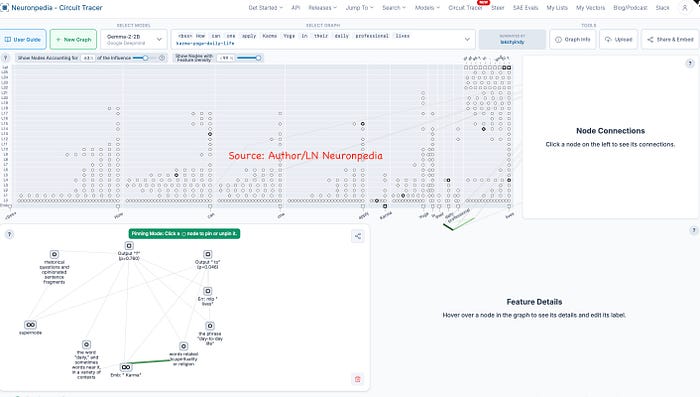
What's particularly valuable in the above work-in-progress graph is that we can see whether the model's answer is grounded in actual conceptual understanding or merely statistical associations. For instance, we might find a connection between "Karma Yoga" and "detachment from results" features, suggesting the model has incorporated the authentic philosophical principle rather than just surface-level associations.
By examining the attribution graph for this prompt, we could identify if the model:
- Correctly recognizes Karma Yoga as a spiritual practice derived from Hindu philosophy
- Activates features related to core principles like selfless service and duty
- Connects these principles to workplace scenarios appropriately
- Balances the spiritual aspect with practical application
If we noticed the model was missing important aspects of Karma Yoga (perhaps not activating any features related to "non-attachment" or "inner peace" or "Bhagavad Gita"), this could indicate gaps in its understanding that might lead to incomplete or misleading responses.
When Explanations Don't Match Reality
One of the most eye-opening findings from circuit tracing is discovering when a model's step-by-step explanations don't match its internal computation. In Anthropic's research, they found that when asked to calculate something difficult like cos(23423), the model would provide a detailed explanation that bore no resemblance to its actual internal process — it was essentially generating a plausible-sounding explanation.
With open-source circuit tracing, you can now verify for yourself whether a model's reasoning is faithful or fabricated. This capability is particularly important for high-stakes domains like healthcare, finance, or legal advice, where understanding the true basis of an AI's recommendation is crucial.
Catching Hallucinations Before They Happen
Circuit tracing can also reveal the mechanism behind hallucinations — those confidently stated but factually incorrect responses that can occur in AI systems.
Anthropic's research revealed that models like Claude have a default "I don't know" circuit that's overridden when the model recognizes a topic it thinks it knows about. Hallucinations often occur when this override happens incorrectly — when the model thinks it knows something but actually doesn't.
By examining attribution graphs, researchers and now the broader community can identify patterns that precede hallucinations and potentially develop better methods to prevent them.
For the Technical Readers: Going Deeper with the Python Library
While Neuronpedia offers an accessible interface, the Python library provides more flexibility and power for those comfortable with code. Here's how to get started:
# Installation
git clone https://github.com/safety-research/circuit-tracer.git
cd circuit-tracer
pip install .
# Basic usage
from circuit_tracer import trace, visualize
# Generate attribution graph
graph = trace(prompt="How does gratitude affect wellbeing?",
transcoder_set="gemma")
# Visualize the graph
visualize.launch_server(graph.to_json(), port=5000)The library allows for more advanced operations than the web interface, including:
Running Interventions
Interventions are where circuit tracing becomes particularly useful. You can modify specific features to test causal relationships in the model:
# Get the replacement model
model = tracer.get_replacement_model()
# Identify a feature (e.g., one representing "positivity")
positivity_feature_id = 1234 # Example ID, you'd identify this from the graph
positivity_layer = 8
# Run with the feature suppressed
model.set_feature(layer=positivity_layer,
feature_id=positivity_feature_id,
value=0.0)
# Generate output and see if mentions of positive effects disappear
modified_output = model.generate(prompt_tokens)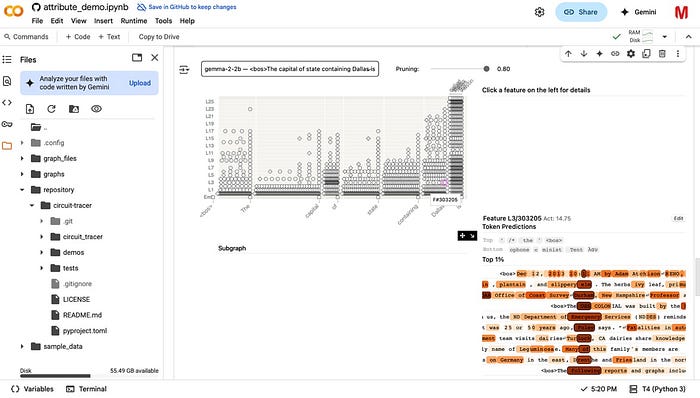
Advanced Experiments to Try
If you're comfortable with the Python library, consider these experiments:
- Concept swapping: Identify features representing opposing concepts (e.g., "selfless" vs. "self-interested") and swap them to see how responses change in the Karma Yoga example.
- Safety mechanism analysis: Trace prompts that approach safety boundaries to understand how a model's safety guardrails work internally.
- Cross-model comparison: Generate attribution graphs for the same prompt across different models to compare reasoning strategies.
- Fine-tuning impact: If you have the capability, trace the same prompt before and after fine-tuning to see how training affects internal representations.
- Validating knowledge: Test whether the model truly understands concepts like Karma Yoga by intervening on specific features and observing changes in the output. For example, suppressing the "detachment" feature might lead to advice that emphasizes results rather than the process.
Current Limitations
While useful, the open-source tools have some limitations to be aware of:
- They currently support only smaller models (2B and 1B parameter versions)
- The transcoders don't capture attention mechanisms completely
- Features sometimes have unclear or overlapping meanings
- Computation can be resource-intensive, especially for longer prompts
These limitations will likely improve as the community contributes to the tools and updates are released.
The Future of AI Transparency
The release of these circuit tracing tools represents an important step in AI interpretability research. Here are some potential developments we might see:
Community-Driven Interpretability
With these tools in public hands, we can expect more community research. Independent researchers might discover patterns that weren't initially identified, develop improved visualization techniques, or extend the tools to work with more models.
New Safety and Alignment Approaches
Understanding mechanistic behavior opens new possibilities for alignment. Rather than treating models as black boxes that we can only influence through training data and reinforcement learning, researchers might develop methods to directly shape internal representations and circuits.
Educational Benefits
These tools have significant potential for education. Computer science and AI courses could include labs where students explore attribution graphs to understand how language models work, beyond theoretical explanations in textbooks.
Regulatory Implications
As AI regulation develops, interpretability tools might become part of compliance frameworks. Regulators might require certain levels of transparency for high-risk applications, making these tools increasingly important.
Your Role in the Transparent AI Future
The open-sourcing of circuit tracing tools represents an invitation—to researchers, developers, students, and curious minds of all backgrounds. You now have the opportunity to participate in understanding and shaping how AI systems work.
Even if you're not a technical expert, exploring these tools can help you develop a more nuanced understanding of AI capabilities and limitations. This knowledge is increasingly valuable as AI systems become more integrated into our daily lives and decision-making processes.
For those with technical skills, the invitation is even more direct: contribute to the tools, share your findings, and help build a community around AI interpretability. The GitHub repository accepts contributions, and Neuronpedia allows for sharing and discussing attribution graphs.
Conclusion: From Black Box to Glass Box
In my previous article, I used the metaphor of movie-making to explain how researchers were examining the inner workings of AI models — we were essentially watching a documentary about AI's internal mechanisms, with Anthropic's researchers acting as directors and cinematographers showing us carefully selected scenes.
With the release of these open-source tools, that metaphor has evolved — we've moved from being passive viewers of a documentary to being handed professional cameras and editing equipment ourselves. Now anyone can direct their own exploration, filming the model's thought processes from different angles and focusing on the specific aspects they find most intriguing.
The black box of AI is gradually transforming into a glass box, one that allows us to observe, understand, and ultimately improve the systems inside. This transformation isn't just about satisfying technical curiosity — it's about building AI systems that align with human values and that we can genuinely trust to operate as intended.
As you explore these tools yourself, remember that you're not just observing artificial intelligence — you're participating in a new kind of relationship with technology, one based on transparency rather than opacity. You're becoming the documentarian of AI's internal world, capturing its reasoning in action. In a world increasingly shaped by AI systems, this relationship may prove to be one of our most important.
Would you like to see a follow-up article exploring specific findings from community research using these tools? Let me know in the comments below!
Author's note: The screenshots and some technical details in this article may change as the tools evolve. For the most up-to-date information, refer to the official documentation.