

Missing data is frequently encountered in data sets obtained from real life. Since missing data causes problems in many data analysis methods, preliminary processing of these data is necessary. The thing that affects the performance of the models the most is that the data set is usable and free of erroneous values. If missing data is not analyzed, it may cause models to make biased and inaccurate predictions. Before performing analyzes on missing data, the reasons for missing data in the data set should be investigated.
Missing data may be randomly distributed and occur randomly within the data set. In other words, we call missing data that occurs independently of a reason as random missing data. It can be decided whether the missing data occurs randomly or not with tests such as t-Test. We want the missing data to occur randomly in our analyzes for missing data. In this way, there will be no loss of information. If missing data occurred for a reason, this reason should be investigated. In this case, random formation cannot be mentioned. For example, a rain gauge device in a meteorological observation station continuously records rainfall values. Random missing data may occur in cases where the device malfunctions or its sensor cannot make accurate readings. However, if the device records the days without rain as blank values, there is nothing random here. Therefore, the reasons for missing data should be investigated first.
If our missing data occurred randomly, we can perform the following analyses. Before applying these analyses, the number of missing data in the data set should also be checked. If the number of missing data is large, it may be more beneficial to not use the relevant variable at all.
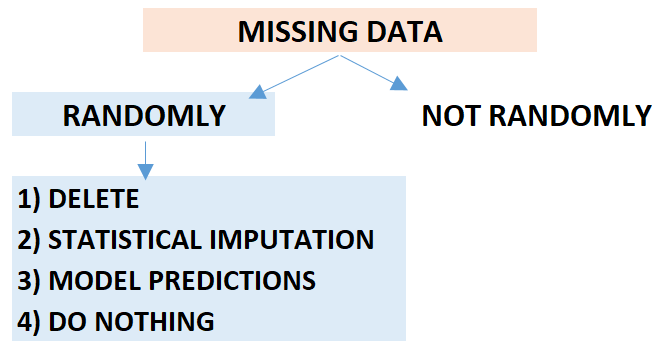
Analyzes can be made regarding the missing data in our data set using several different methods.
1) Missing values can be completely deleted from the data set.
Different operations can be performed depending on the size of the data set. Only the missing data itself can be deleted from the data set. Additionally, any row with missing data can be deleted from the data set. If there are values associated with missing data, all these values together with the missing data can be deleted from the data set on a list basis. Deletion procedures vary depending on the structure of the data set. Data deletions should only be applied if they do not result in loss of information.
# Drop rows with missing data
df_dropped_rows = df.dropna()
# Drop columns with missing data
df_dropped_columns = df.dropna(axis=1)2) Instead of missing values, values such as average, mode, median, nearest value, average of neighbors calculated from the data set can be assigned.
Missing data can be filled in the data set using various statistical methods. Applying these methods instead of deleting missing data will prevent information loss and increase model performance in some cases. We can substitute the mean, mode or median value of the column with missing data in the data set. In this way, bias situations resulting from missing data will be eliminated. Instead of these statistics that generalize the data set, in some cases the nearest upper or lower neighbor of the missing data or the average of its neighbors can be used. In this way, the trend lines of the data set are preserved.
# Fill missing data with mean
df_filled_mean = df.fillna(df.mean())
# Fill missing data with median
df_filled_median = df.fillna(df.median())
# Fill missing data with mode (first mode value)
df_filled_mode = df.fillna(df.mode().iloc[0])3) Predictive models are established by removing missing data from the data set. Missing data is calculated with these models.
Models can be built to predict missing data. Missing data can be estimated with models built using machine learning or deep learning methods. For example, in a data set containing dependent and independent values, we first remove the rows with missing data from the data set. Then, we build our model using multiple linear regression or a different method of your choice. We train our model with a data set that does not contain missing values. Finally, we estimate the missing value of the dependent variable for the independent variable with the missing value.
# Use KNN imputer to predict missing data
imputer = KNNImputer(n_neighbors=2)
df_imputed = pd.DataFrame(imputer.fit_transform(df), columns=df.columns)4) Missing data can be left as is in the data set.
In some cases, removing missing values from the data set may result in loss of information. Missing values may be meaningful on the data set. In these cases, we can use models that can work with missing values without taking any action on the missing values. XGBoost, LightGBM, and CatBoost algorithms can handle missing data. You can use these algorithms by leaving missing data in your data set as is. It will be useful for you to read the article in the link about this subject.
End
You can reach me through my LinkedIn address for your questions and suggestions.