

It started with an idea that seemed obvious at the time: Why don't we just let AI agents talk to each other in embeddings?
We know that LLMs process meaning using high-dimensional vectors — mathematical representations of semantics that are far more precise than human language. My initial hypothesis was that if Agent A sent raw embeddings to Agent B, they would understand each other perfectly and we'd save massive compute.
I was wrong.
Two hard realities hit me:
- The Interoperability Wall: Embeddings are maps to a model's specific interior architecture. You can't just hand a vector from GPT-4 to Llama 3; it's like handing a map of London to someone in Tokyo.
- The Token Bloat: Transmitting a vector of hundreds of dimensions of floating-point numbers actually costs more tokens than just speaking English.
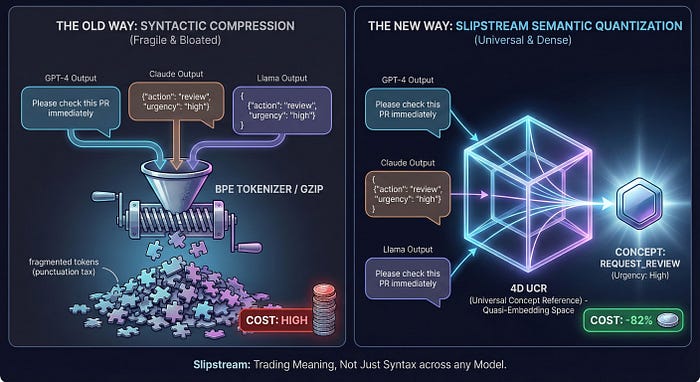
So we retreated to the status quo: forcing silicon intelligence to communicate via verbose English wrapped in JSON. We take clear intent, shatter it into "token confetti" (brackets, quotes, whitespace), and pay the "tokenizer tax" on every interaction.
Then the second idea hit me.
We already solve the problem of massive data size in model weights using Quantization. We chop off the precision we don't need (moving from float16 to int4) to run big models on consumer hardware.
Why not apply that same principle to Communication?
Instead of syntactic compression (zipping text), we need Semantic Quantization. We can "chop off" the noise of natural language and transmit only the dense, quantized "concept code."
This is the thesis behind Slipstream.
Slipstream creates a "Universal Concept Reference" (UCR) — a shared, quantized semantic manifold. The message itself becomes a tiny, token-efficient pointer to a complex meaning.
The results are startling: 82% reduction in coordination overhead.
To prove this isn't just theory, I spent the last few months building the entire ecosystem. This week, to support my application for the Anthropic research fellowship, I am open-sourcing everything:
- The Library:
pip install slipcore(A production-ready transport layer). - The Models: A GLM-4–9B model fine-tuned on the "Think-Quantize-Transmit" cognitive pattern.
- The Weights: Published to Hugging Face and Ollama (LoRA adapters, GGUF 4-bit, and full weights).
- The Data: A complete synthetic training dataset published to HF and Kaggle.
- The Spec: A formal ABNF grammar for the wire protocol and an integration draft for the Agent-to-Agent (A2A) protocol.
- The Demo: A live Hugging Face Space where you can watch the model quantize thoughts in real-time.
We are entering the era of multi-agent swarms. We cannot afford to have them wasting 60% of their compute just clearing their throats.
It's time to stop compressing syntax and start quantizing meaning.
Deliverables
Publication & Code
- Paper: https://doi.org/10.5281/zenodo.18063451
- GitHub: https://github.com/anthony-maio/slipcore
- PyPI:
pip install slipcore
Models (Hugging Face)
- LoRA: https://huggingface.co/anthonym21/slipstream-glm-z1-9b
- GGUF: https://huggingface.co/anthonym21/slipstream-glm-z1-9b-gguf
- Merged: https://huggingface.co/anthonym21/slipstream-glm-z1-9b-merged
Dataset
Extensions
- A2A Extension Spec: https://github.com/anthony-maio/slipcore/tree/master/extensions/a2a-slipstream/v1
- ABNF Grammar: https://github.com/anthony-maio/slipcore/blob/master/extensions/a2a-slipstream/v1/slipstream.abnf
Training Resources
- Colab Notebook: https://github.com/anthony-maio/slipcore/blob/master/notebooks/slipstream_finetune_colab.ipynb
- Modelfile (Ollama): https://github.com/anthony-maio/slipcore/blob/master/Modelfile
A note on the UCR: The most common question I get is "How is the Concept Reference maintained?" The protocol is designed to be extensible — agents can negotiate local extensions for domain-specific jargon, similar to how we handle API versioning. More on that in the repo.