

Five years ago, I wrote about NVIDIA Jarvis, back when it was still called Jarvis and not RIVA.
At the time, the big question was dialog management — how do you handle multi-turn conversations, track state, manage context?
NVIDIA did not build their own. They integrated with Rasa and Google Dialogflow for that component.
That felt like a gap at the time. A conversational AI platform without native dialog management seemed incomplete.
Looking at it now, that gap turned out to be a feature.
From Jarvis To Riva
NVIDIA announced Jarvis at GTC 2020.
Jensen Huang demonstrated it with Misty, a conversational weather chatbot — an end-to-end pipeline for speech recognition, language understanding, and text-to-speech.
It was impressive as a technology demo. It shipped into beta in early 2021.
Then in July 2021, NVIDIA renamed Jarvis to Riva.
Same technology, same team, new name.
The rename was clean — all documentation, scripts, and CLI commands were updated.
Jarvis Speech Skills became Riva Speech Skills.
But the architecture question remained, Riva handled ASR (speech-to-text) and TTS (text-to-speech) brilliantly.
For dialog management — the logic that decides what to say next — you still needed an external framework.
The original Riva sample applications demonstrated two configurations:
Riva did speech.
Rasa or Dialogflow did conversation logic.
That was the architecture.
The Great Rewrite, LLMs Replace Dialog Management
Then everything changed.
The traditional conversational AI pipeline looked like this:
ASR → NLU (intent + entities) → Dialog Manager (state machine) → Fulfillment → NLG → TTSEvery platform — Rasa, Dialogflow, Amazon Lex, IBM Watson — required developers to…
- Predefine every intent (book_flight, check_balance, reset_password)
- Annotate entities (dates, locations, amounts)
- Write stories and flows defining conversation paths
- Maintain thousands of training utterances
The fundamental problem…conversations that went off-script broke.
If someone was updating their shipping address and asked about a refund mid-conversation, the system could not handle both.
The state machine was rigid.
Large Language Models replaced all of this.
Not gradually, but fundamentally.
No intent schemas required.
LLMs understand user messages without predefined categories.
No rigid state machines.
LLMs maintain context and handle digressions naturally.
No training utterances.
A system prompt replaces thousands of labeled examples.
Dynamic adaptation.
The model weaves new topics into the conversation and returns to the original task.
The entire NLU + Dialog Manager pipeline collapsed into a single LLM call.
This is why NVIDIA's original decision to not build native dialog management looks prescient in hindsight.
They bet on speech — the part that LLMs would not replace.
ASR and TTS are signal processing problems.
You need specialised models for those.
But dialog management?
That is exactly what LLMs are best at.
Voice Is The Interface That Matters Now
Here is where it gets interesting.
Peter Steinberger — the developer who bootstrapped PSPDFKit into a major company, then created OpenClaw, one of the fastest-growing open-source AI agent frameworks — told Lex Fridman something striking:
"I don't write, I talk. These hands are too precious for writing now."
He uses voice input almost exclusively to interact with AI agents.
Not typing.
Speaking.
And he did it so intensely during the development of OpenClaw that he lost his voice.
The voice coding ecosystem is growing…
Caterpillar, Voice On The Edge
The most compelling example of all this coming together is Caterpillar.
At CES 2026, Caterpillar debuted the Cat AI Assistant — a voice-activated system running inside heavy equipment cabs.
The technical stack:
NVIDIA Riva for speech, Parakeet ASR (speech-to-text) and Magpie TTS (text-to-speech)
Qwen3 4B, a compact LLM for intent parsing and response generation, served locally via vLLM
NVIDIA Jetson Thor, edge AI hardware running everything on-device
Caterpillar Helios, their unified data platform providing equipment context
And it runs entirely on the edge.
No cloud.
No internet required.
On a construction site. In a mine. In places where connectivity is a luxury and latency is unacceptable.
This is what the Jarvis architecture was always pointing toward…speech on the edge, intelligence in the model, no dialog management middleware in between.
Three things stand out for me
One
The speech layer is the durable layer.
Dialog management frameworks came and went.
Intent schemas came and went.
NLU training data came and went.
But ASR and TTS? Those are physics problems — converting sound waves to text and back. LLMs did not replace them. They cannot. Riva bet on the right layer.
Two
Voice is the agentic interface.
When you interact with an AI agent, typing is friction.
Speaking is natural.
Steinberger's experience is not an edge case — it is a leading indicator.
As AI agents become the primary way developers (and equipment operators, and customers) interact with software, voice becomes the default input.
Riva provides the infrastructure for this.
Three
Edge deployment changes everything.
The Caterpillar example is not a demo.
It is production infrastructure running in excavator cabs with no internet.
Riva's ability to run ASR and TTS on Jetson hardware, combined with a local LLM, creates fully autonomous voice agents that work anywhere.
This is the pattern for industrial AI, automotive AI, and any environment where cloud is not an option.
Running The Demo
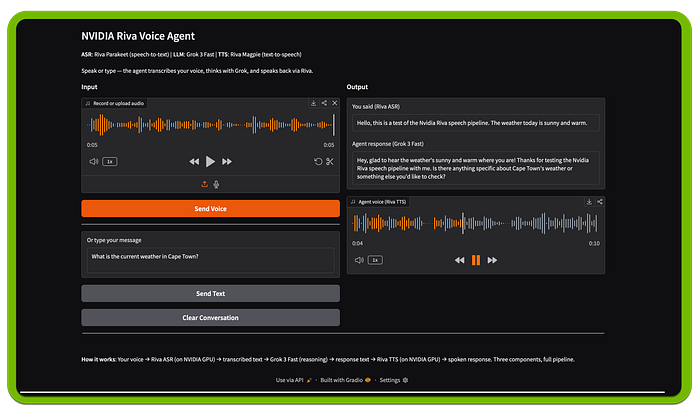
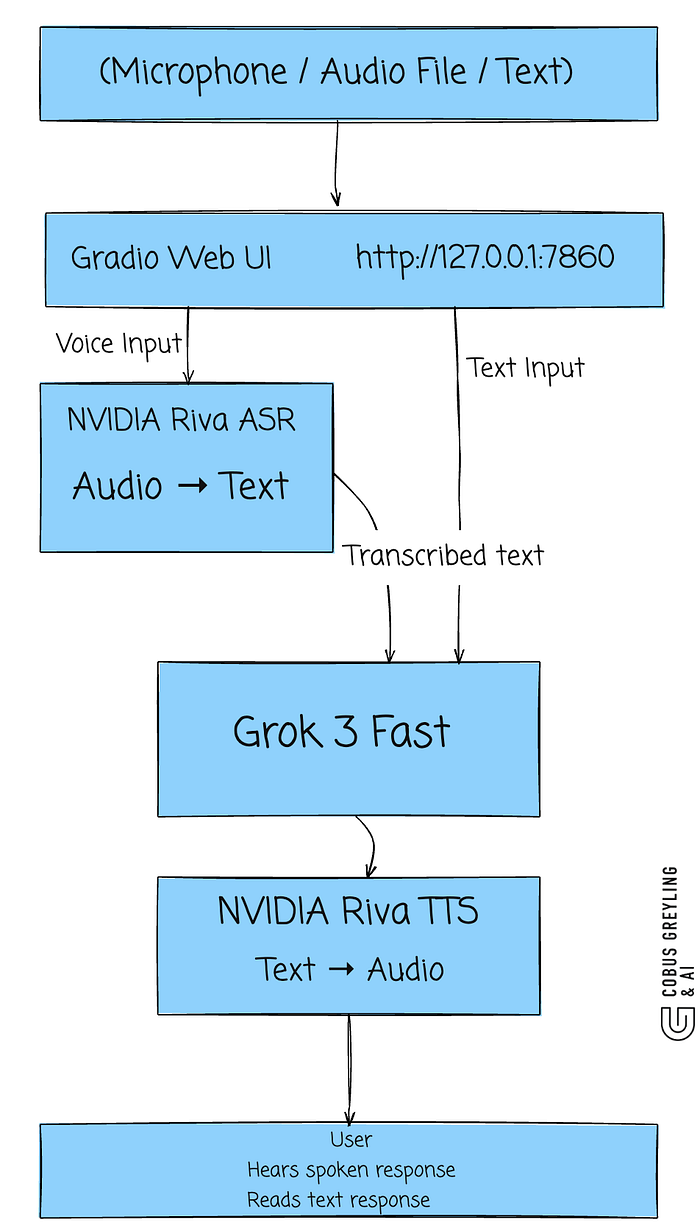
I built a prototype that demonstrates the Riva pipeline — ASR and TTS via NVIDIA's cloud API. You can record audio, transcribe it with Riva, process it through an LLM, and hear the response spoken back.
pip install nvidia-riva-client gradio openai
export NVIDIA_API_KEY="your-key" # Free at build.nvidia.com
export GROK_API_KEY="your-key" # From x.ai
python3 riva_voice_agent_demo.pyThe demo opens a Gradio web UI at http://127.0.0.1:7860
The Gradio interface — record audio, upload a file, or type text. Input on the left, output on the right.
You can type a question and the agent responds with text (via Grok) and spoken audio (via Riva TTS)…
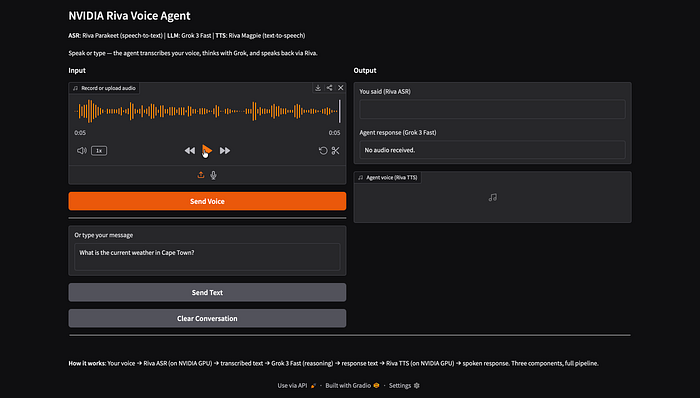
Text mode: "What is the current weather in Cape Town?" — Grok responds, Riva speaks it back.
Or upload an audio file for the full ASR pipeline:
An audio file uploaded and ready to send to Riva ASR.
The full pipeline in action — audio transcribed by Riva ASR, processed by Grok 3 Fast, and spoken back via Riva TTS.
Chief Evangelist @ Kore.ai | I'm passionate about exploring the intersection of AI and language. Language Models, AI Agents, Agentic Apps, Dev Frameworks & Data-Driven Tools shaping tomorrow.
