

Graph RAG has exploded in popularity, but most implementations still behave like toy demos — fast and impressive on tiny graphs, yet painfully slow or inaccurate the moment you scale to millions of nodes, documents, or relationships. The reason isn't your model, your GPU, or your prompt engineering. It's your indexing.
Knowledge graphs require fundamentally different retrieval strategies than vector-only RAG (a.k.a. Naive RAG, Vanilla RAG), especially when queries involve multi-hop reasoning, entity grounding, or structural constraints.
In this article, we take a deep dive into the indexing strategies that turn Graph RAG from a research prototype into a production-ready, low-latency system capable of supporting complex enterprise workloads. From full-text and semantic indexing to structural methods like pivots, k-core, and path caching — and finally to modern hybrid reranking pipelines — we break down how each layer works, when to use it, and why indexing is the true engine behind scalable Graph RAG.
1. Introduction
The recent rise of Graph RAG promises more factual, interpretable, multi-hop question answering by grounding LLMs in structured knowledge graphs (KGs). Yet most implementations still struggle with:
- Slow multi-hop retrieval
- Noisy or irrelevant node expansion
- Missing connections across graph components
- Poor coverage of long-tail entities
- Weak alignment between structure and semantics
These issues often get misdiagnosed as an "LLM accuracy problem," but in practice they are overwhelmingly indexing problems.
Unlike naive RAG — which simply embeds text chunks and performs top-k similarity search — Graph RAG operates over heterogeneous graph data:
- entities
- relations / triples
- passage nodes
- metadata nodes
- multi-hop adjacency
- communities and subgraphs
- provenance links
Retrieving high-quality evidence from such structures requires more than embeddings. It requires indexes that capture structure.
Graph RAG therefore represents a data engineering discipline, not just a model wrapper. Indexing determines:
- Retrieval latency
- Structural coverage
- Multi-hop reasoning ability
- Explainability (paths, provenance, communities)
- Scalability to millions of nodes
Let's take a closer look at existing index types and how they can be leveraged.
2. Full-Text Indexing
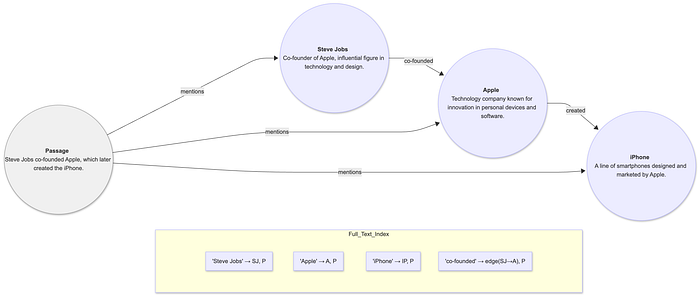
What It Is?
Full-text indexing (inverted index, BM25, keyword search) is the oldest and most mature search technology.
Origins:
- 1960s: Early IR systems
- 1990s–2000s: Google's early web indexing
- Modern implementations: Lucene, Elasticsearch, Solr, PostgreSQL full-text, Vespa
In Graph RAG, full-text search ensures:
- fast keyword lookup
- entity name matching
- relation label matching
- alignment between graph nodes and actual documents
Why It Matters
Full-text search (BM25, inverted index) remains the fastest way to retrieve entities, relation labels, metadata, and passages through exact or fuzzy lexical matches. Without it, even basic lookups explode into expensive graph scans.
When to Use
- Queries with clear keywords e.g.
"When was the iPhone released?"
"Who is the CEO of Apple?"
- Entity/alias lookups
- When retrieving textual evidence or passages
- As the first-stage candidate generator before semantic and structural filters
Best Practices
- Index entity names, aliases, descriptions, relation labels, document text
- Use stemming, lemmatization, and stop-word handling
- Enable prefix search for incremental typing
- Maintain separate full-text indexes for node labels, relation descriptions and source text chunks
- Combine with metadata filters (types, timestamps)
3. Semantic Indexing (Vector Embeddings)
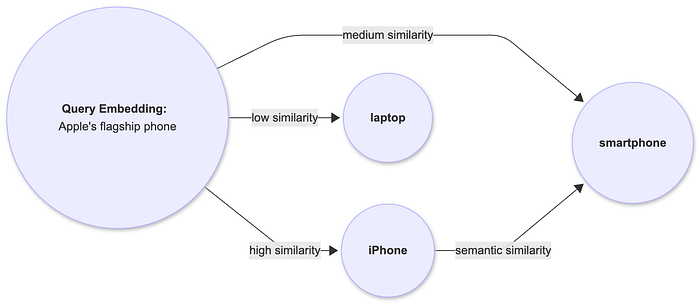
What It Is?
Semantic indexing converts text, nodes, triples, or documents into numerical embedding vectors to capture meaning beyond exact keywords.
There are many widely used embedding models today:
- Word2Vec (2013)
- BERT / SentenceBERT (2018–2019)
- Modern embedding models (2022–2024): BGE, E5, GTE, OpenAI text-embedding-3
In Graph RAG, embeddings can be done over:
- nodes: usually text embedding of name, label and corpus.
- relations: usually text embedding of relationship type, property, head node + relation type + tail node.
- passages
- multi-modal documents
Why It Matters
Purely lexical matches can be brittle. Semantic indexing surfaces relevant data even when the query uses different wording.
One of my earlier blog posts has detailed explaination of text embeddings and how they were used in RAG:
4. Structural Indexing: Connectivity-Based
What It Is?
Connectivity-based structural indexing refers to a family of indexing techniques that leverage the topology of a knowledge graph — how nodes and edges connect — to support low-latency, structure-aware retrieval. Instead of relying on keywords or semantic embeddings, these indexes use graph connectivity patterns to identify important nodes, dense regions, shortest paths, and multi-hop relationships. The goal is to drastically reduce the graph search space by prioritizing nodes that are structurally central, well connected, or topologically relevant to a query.
Connectivity-based indexes typically include techniques such as k-core decomposition, k-core-connected components (KCC). These indexes are essential in large-scale Graph RAG because graph traversal is expensive — often touching millions of edges. Connectivity-based indexing enables systems to locate relevant regions of the graph in milliseconds, identify multi-hop evidence chains, and avoid costly full-graph scans. They also support interpretability by revealing how entities are connected, not just whether they are semantically similar.
Origins
- Seidman (1983), social network analysis
- Internet graph backbone detection (2000s)
- Enterprise KG relevance scoring (2020s)
Why It Matters
Graphs derived from documents or enterprise systems often contain:
- noisy leaf nodes
- low-value entities
- sparse connections
k-core can:
- filters noise
- highlights central hubs
- ensures multi-hop reasoning stays in meaningful subgraphs
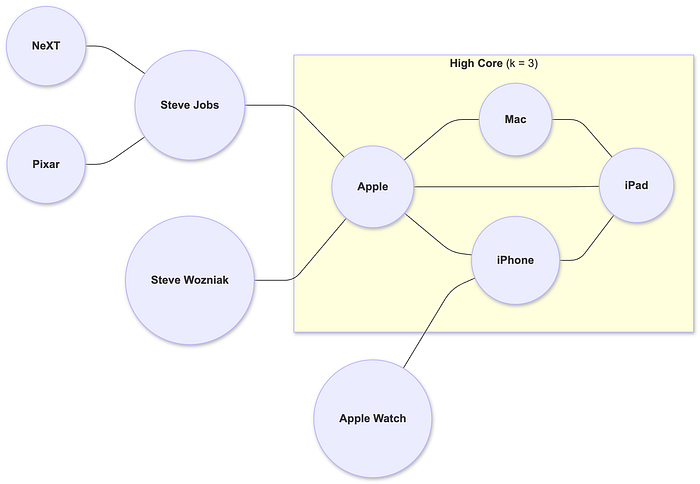
Using figure 3 as an example, we have:
- Apple connected to many products (iPhone, iPad, Mac)
- Steve Jobs connected to Apple, NeXT, Pixar
- iPhone connected to iOS and App Store
Simply based on number of connections, it's easy to realize:
- High-core entities: Apple, iPhone, iPad
- Low-core entities: App Store, Pixar, NeXT
This ensures that retrieval prioritizes core entities critical for reasoning.
5. Structural Indexing: Distance-Based
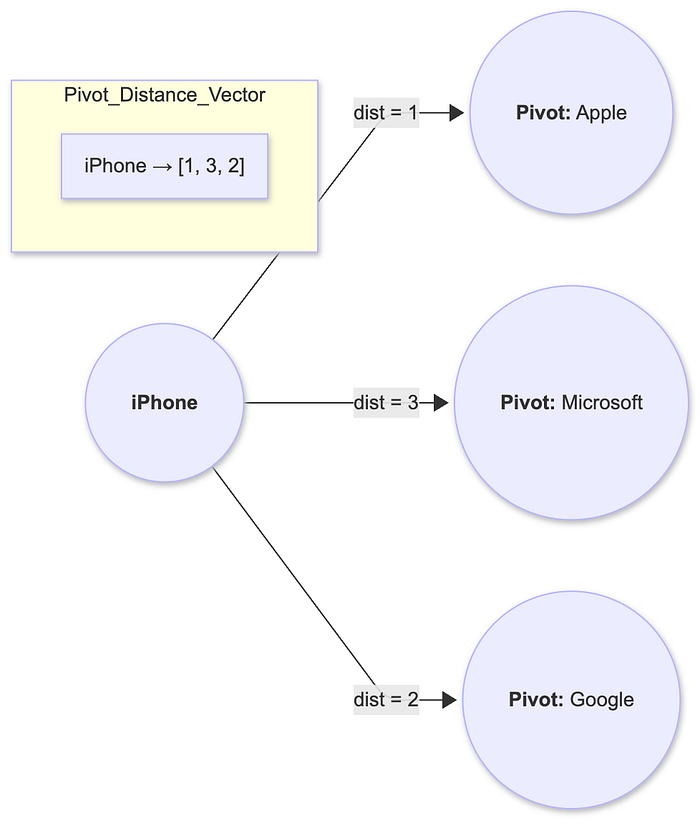
What It Is?
Distance-based structural indexing refers to indexing techniques that use graph distance metrics — such as shortest paths, hop counts, or approximate proximity — to accelerate retrieval in large knowledge graphs. Instead of scanning the entire graph, distance-based indexes precompute or approximate how far each node is from a set of reference points (often called landmarks or pivots).
A common approach is pivot-based indexing, where a small number of strategically chosen nodes act as anchors. Each node is represented by a vector of distances to these pivots. This allows fast estimation of structural similarity, neighborhood relevance, or likely multi-hop connectivity without performing expensive BFS/DFS traversals.
Origins
- Distance Oracles (Thorup-Zwick, early 2000s)
- Metric embedding & landmark-based routing (Source)
- Canonical use in large graph similarity searches (Source)
Why It Matters
Distance-based indexing has unique advantages:
- scales to large graphs
- provides efficient multi-hop approximation
- makes structural similarity calculable in constant time
6. Structural Indexing — Path Index (k-hop Cache)
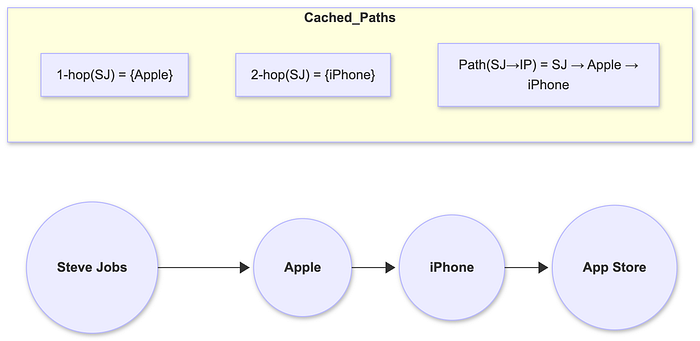
What It Is
A path index is a structural indexing method that precomputes and stores k-hop neighborhoods, shortest paths, or common traversal patterns within a knowledge graph to enable fast multi-hop retrieval. Instead of discovering paths dynamically — an expensive operation on large graphs — the system maintains cached paths such as:
- 1-hop neighbors
- 2-hop expansions
- frequently used multi-hop chains
- shortest or top-ranked paths between key nodes
This allows Graph RAG systems to answer queries requiring relationship reasoning (e.g., "Who founded the company that created the iPhone?") by instantly retrieving chains like:
Steve Jobs → Apple → iPhone
Path indexes drastically reduce traversal costs, support explainable retrieval, and provide structured evidence that LLMs can use for reasoning, reranking, or justification.
Path indexing is most effective in large, highly connected KGs or scenarios involving repeated multi-hop queries. It is less beneficial for small graphs, extremely sparse networks, or environments where data changes too frequently for cached paths to remain valid.
Origins
- Graph databases (Neo4j)
- Web graph reachability studies (Source)
- Multi-hop QA datasets (HotpotQA, Musique)
Why It Matters
A good path index speeds up:
- reasoning
- fact chaining
- retrieval explainability
7. Structural Indexing — Community / Cluster Index
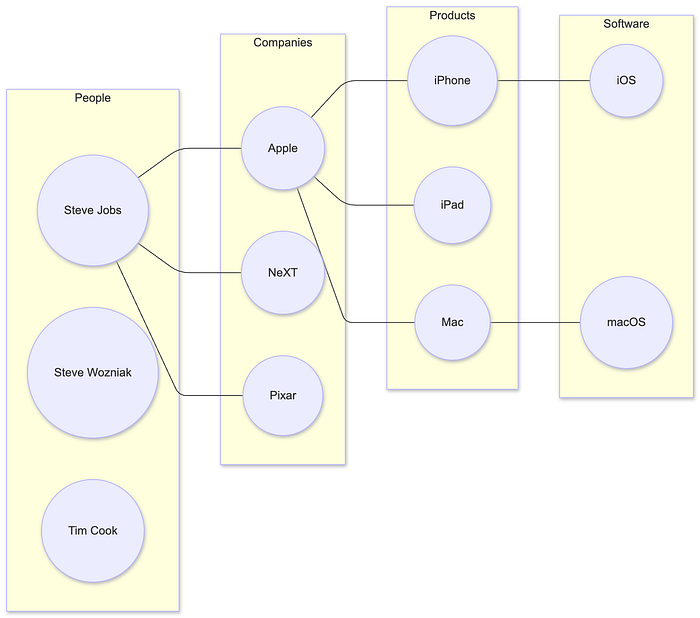
What It Is
A cluster index is a structural indexing technique that groups nodes in a knowledge graph into communities or clusters based on connectivity patterns, semantic similarity, or graph topology. Methods such as Louvain, Leiden, Chinese Whispers, or Spectral Clustering identify dense subgraphs where nodes are more strongly connected to each other than to the rest of the graph.
By organizing the graph into coherent regions — such as People, Companies, Products, or Technologies — a cluster index enables retrieval systems to restrict search to only the relevant portion of the graph. This dramatically reduces the search space, accelerates multi-hop traversal, and increases precision by keeping queries inside domain-consistent neighborhoods.
Cluster indexes are particularly valuable in large enterprise KGs, document-derived graphs, and domain-rich knowledge structures, where natural topic boundaries exist. They are also useful as a first-stage filter before applying semantic ranking or path reasoning.
Why It Matters
Large KGs often contain:
- product clusters
- people clusters
- software clusters
This allows the system to search only within relevant communities. For Fig. 6, there are clusters of:
- People: Steve Jobs, Steve Wozniak, Tim Cook
- Companies: Apple, NeXT, Pixar
- Products: iPhone, iPad, Mac
- Software: iOS, macOS
Query "Who created the iPhone?" stays within Products + Companies clusters.
8. Hybrid Search & Reranking
Hybrid search & reranking is a multi-stage retrieval strategy that combines lexical, semantic, and structural indexes to produce high-quality, contextually relevant, and multi-hop–aware results for Graph RAG. Instead of relying on a single retrieval method, hybrid search pipelines orchestrate multiple complementary retrieval techniques — such as full-text search, vector embeddings, pivot or k-core pruning, community filtering, and path expansion — to progressively refine a candidate set before generating the final answer.
A typical hybrid pipeline begins with broad recall (full-text and embeddings), then narrows down results using structural indexes (k-core, pivot distances, cluster constraints). Next, path indexes retrieve multi-hop evidence chains. Finally, an LLM reranker integrates textual evidence, graph structure, and path relevance to select the most appropriate nodes or answers.
Why Hybrid Search?
Each index satisfies specific domain:
- precision (full-text)
- semantics (embeddings)
- structure awareness (graph indexes)
- multi-hop reasoning (path index)
Modern Graph RAG systems therefore use stacked multi-stage retrieval pipelines, where each stage refines a candidate set.
This layered approach has been proven in:
- Microsoft GraphRAG
- Google GENIE QA
- Tree-KG (ACL 2025)
Hybrid Retrieval Pipeline — A Step-by-Step Example
Assume we have a query:
"Who founded the company that created the iPhone?"
Step 1 — Full-Text Search
Extract initial candidates using BM25:
Top results:
- iPhone
This ensures lexical grounding.
Step 2 — Structural Pruning (k-Core / Pivot Index)
From retrieved nodes, we can get their neighbours and re-rank them by graph importance:
- Apple moves to the top (central role)
- Jobs and Wozniak stay high (founders)
- iPhone slightly lower (product, not a founder)
Step 3 — Semantic Embedding Ranking
Interpret intent by calculating similarity scores between embedding of the question and embeddings of retrieved records:
- "founded the company" → person + company
- "created the iPhone" → company + product
Re-rank by semantic fit to to have:
- Steve Jobs
- Steve Wozniak
- Apple
Step 4 — Path Expansion (Graph Reasoning)
Discover multi-hop structures among nodes:
- Steve Jobs → Apple → iPhone
- Steve Wozniak → Apple → iPhone
These paths directly provide the question's required logic chain.
Step 5 — Prompting & Answer Generation
The LLM evaluates prompts which now have:
- entity descriptions
- paths
- semantic relevance
- context from passages
and generate final Answer:
"Steve Jobs co-founded Apple, the company that created the iPhone."
Summary
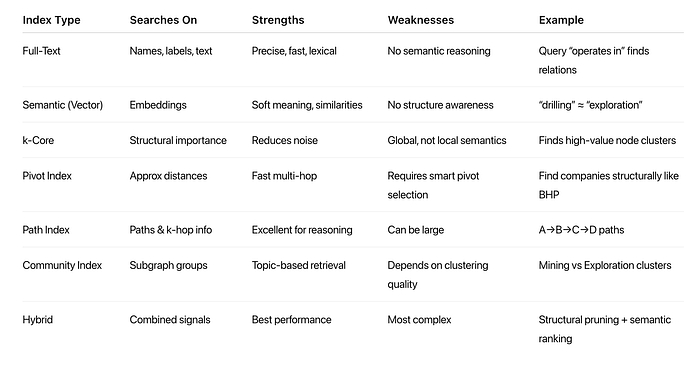
- Full-text indexing ensures lexical grounding
- Semantic indexing provides meaning-based retrieval
- Structural indexing (k-core, pivots, path caches) exposes graph topology
- Community detection narrows search regions
- Hybrid indexing unifies all approaches for the strongest retrieval
- LLM reranking integrates all evidence for final reasoning
This indexing foundation ensures your organization's AI system retrieves the right knowledge, connects the dots, and produces answers you can trust.
References
- Microsoft Research: GraphRAG: Improving RAG with Graph-Structured Knowledge (2024)
- Zhang et al.: Chain-of-Note: Enhancing LLM Reasoning with Graph-Based Retrieval (2024)
- Zhou et al.: Tree-KG: Iterative KG Construction for RAG (ACL 2025)
- Lin et al.: MINE: Multi-Hop Indexing for RAG Evaluation (2025)