


My articles are free to read for everyone. If you don't have a Medium subscription, read this article by following this link.
Large Language Models (LLMs) (think GPT-4, DeepSeek, and the like) are pretty much revolutionizing the tech landscape right now! Not only are they capable of generating human-like text and solving complex problems, but at the point of this writing, can generate full-fledged applications with minimal human involvement. But why is it that only few of us are able to extract the most out of these models, and others aren't?
This is exactly where prompt engineering comes into play. In some sense, prompt engineering is both an art and science. It's about crafting inputs (prompts) that guide LLMs to generate the best possible outputs. In this article, we'll explore the art and science of prompt engineering, what makes it good or bad, various strategies, and best practices while also exploring solutions to address common pitfalls like hallucinations.
What is Prompt Engineering?
Per definition, prompt engineering is the process of designing and iteratively refining inputs (prompts) to guide LLMs in generating accurate, relevant, creative, and contextually appropriate outputs. Think of it as crafting instructions for a highly intelligent assistant.
For example, asking an LLM to — "Write a story about a cat" — is a very basic prompt lacking any context or specificity. This would definitely not lead to the model generating expected (and even useful) results. On the other hand, a more refined prompt giving the LLM specific guidance would be — "Write a 500-word story about a mischievous black cat who accidentally saves a village from a flood" . We can see how this prompt provides clear guidance as to what the story needs to be about, leading to a more focused and creative response.
In some sense, prompt engineering is about communicating effectively with the model in order to achieve the desired outcome. The ability to guide AI to do exactly what you want, using effective prompts is what makes prompt engineering a critical skill for anyone working with LLMs!
What Makes a Prompt Good or Bad?
We saw an example in the previous section about how being a little more specific with our prompt can dramatically change the output of the LLM. In essence, the quality of a prompt can significantly impact the quality of the output. Let's break down the key characteristics of good and bad prompts with examples for clarity.
What Makes a Good Prompt?
- Clarity and Specificity: It precisely defines the task and eliminates ambiguity.
- Contextualized: It provides the model with enough background information to understand the task.
- Concise: It avoids unnecessary details that could confuse the model.
- Structured Inputs and Outputs: It indicates the desired format, tone, or scope of the response.
- Task Decomposition for Complex Operations: Instead of presenting the LLM with a monolithic prompt with multiple tasks, it is better to break it down into simpler sub-tasks.
Examples of Good Prompts:
- Creative Writing (specific with defined subject and structure)— Write a 300-word short story about a young inventor who creates a flying bicycle. Include a conflict and a resolution.
- Coding Task (defined task and input-output requirements) — Write a Python function that takes a list of numbers as input and returns the sum of all even numbers.
- Summarization (specific focus as well as a defined word limit) — Summarize the following article in 100 words, focusing on its key arguments and conclusions.
What Makes a Bad Prompt?
- Vague: It doesn't define the task clearly.
- Overly Broad: It leaves too much room for interpretation.
- Lacking Context: It assumes the model understands unstated information.
Examples of Bad Prompts:
- Creative Writing (vague and lacking context) — Write a short story about a young inventor.
- Coding Task (lack of requirements and input) — Write a Python function to return the sum of all even numbers.
- Summarization (lacking context) — Summarize this: <the article>
Key Takeaway: The clearer, more specific, and contextualized your prompt is, the better the output.
Advanced Prompting Strategies
Different tasks require different prompting strategies, and choosing the right one can significantly improve the accuracy and quality of the output. Relentless research over the past couple of years has lead to a proliferation of strategies. An outline of the current State-of-the-Art used in industry and academia, can be seen in the image below.
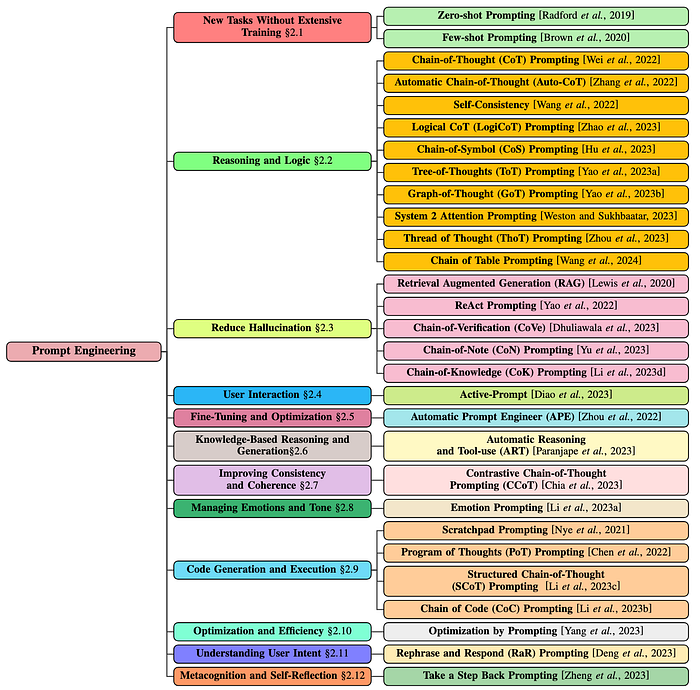
Each of these methods have their own advantages and disadvantages and some even lead to hallucinations when working on complex tasks. In this article, we'll be exploring a few of the more relevant and effective techniques, their nuances, pros and cons, and the types of tasks they are best suited for.
What are Hallucinations?
Hallucinations are a common problem with LLMs, and occur when they generate incorrect, nonsensical, or fabricated information. For example, an LLM might confidently produce a false historical fact or fabricate a source for a citation. This can be problematic, especially for tasks requiring high accuracy or factual integrity. Some of prompt engineering techniques promote maintaining factual integrity instead of being more creative.
1. Zero-Shot Prompting
- Description: This is the simplest form of prompting, where you ask your model to complete a task without providing any prior examples or context.
- Example: Translate the following sentence to Spanish — "I enjoy learning"
- Pros: Easy to implement and useful for well-defined tasks.
- Cons: Performance can be inconsistent for complex or nuanced tasks and the model generally can't tackle tasks outside its training domain.
- Use Cases: Simple tasks such as translation, factual Q&A, basic summarization and simple copy-writing tasks.
2. Few-Shot Prompting
- Description: In this technique, we provide the LLM a few examples of input-output pairs to steer the model and enable in-context learning.
- Example: A "whatpu" is a small, furry animal native to Tanzania. An example of a sentence that uses the word whatpu is: We were traveling in Africa and we saw these very cute whatpus. To do a "farduddle" means to jump up and down really fast. An example of a sentence that uses the word farduddle is:
- Pros: Improves understanding of task-specific nuances, reduces ambiguity and increases accuracy.
- Cons: Requires a little more effort to curate high-quality examples and may not always scale well for tasks needing multiple examples. For more difficult tasks, you might want to increase the demonstrations to few-shot (3-shot, 5-shot, 10-shot, etc)
- Use Cases: Creative writing, coding or tasks with specific formats such as content creation, structured data generation and programming.
3. Chain Of Thought (CoT)
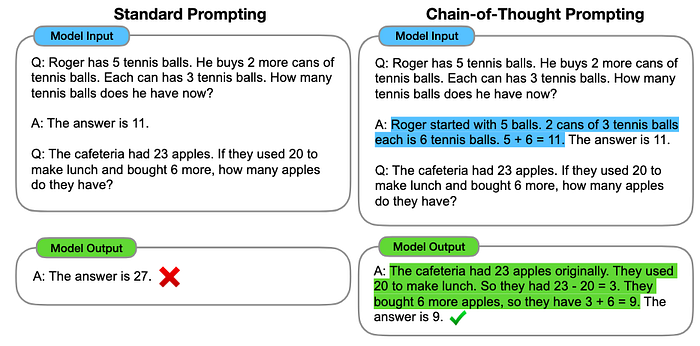
- Description: Here, the model is encouraged to reason through a problem step by step instead of jumping straight to the answer. It is generally combined with few-shot prompting to get better results on more complex tasks.
- Example: If apples cost $2 each and bananas cost $1 each, calculate the total cost of 3 apples and 2 bananas. To do this, follow: Step 1: Calculate the cost of 3 apples. Step 2: Calculate the cost of 2 bananas. Step 3: Add the two amounts together.
- Pros: Improves accuracy for multi-step problems and reduces errors in tasks requiring complex computations.
- Cons: Requires a little more effort to curate high-quality examples and may not always scale well for tasks needing multiple examples. The manual effort could also lead to sub-optimal solutions in most cases.
- Use Cases: Math problems, coding, and logical reasoning tasks
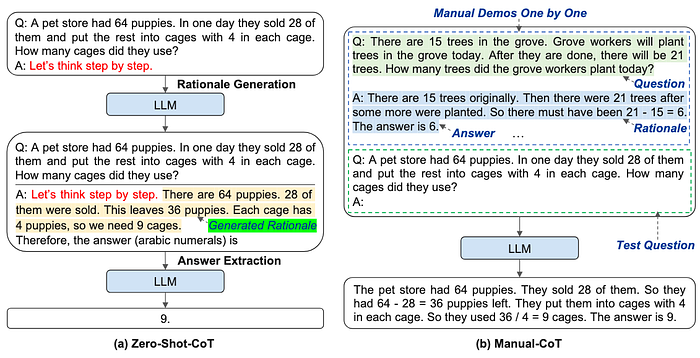
4. Automatic Chain of Thought (AutoCoT)
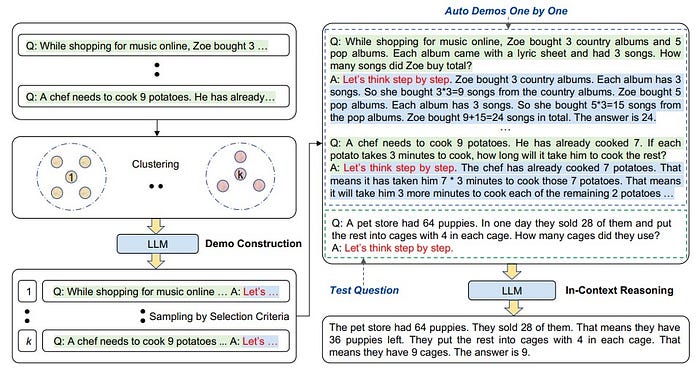
- Description: In this strategy, we eliminate the manual effort and allow the LLM to spontaneously generate its own reasoning chains by leveraging the "Let's think step by step" prompt.
- Example: What is the square root of 144?
- Pros: Generates better solutions for multi-step problems and reduces the need for manual task decomposition.
- Cons: Sometimes it may produce incorrect or irrelevant reasoning without fine-tuning.
- Use Cases: Open-ended and autonomous reasoning tasks such as brainstorming.
5. Chain Of Symbols (CoS)
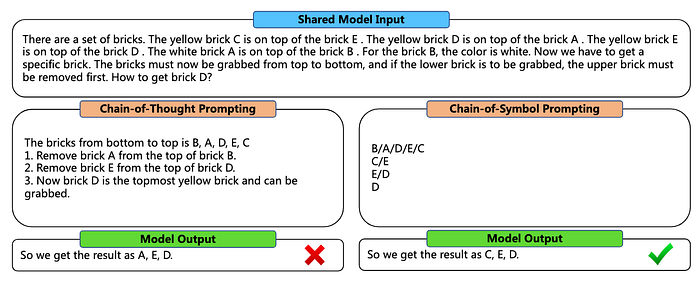
- Description: The main focus of this strategy is to convert natural language and text to symbolic representations using symbols, structured formats or predefined templates to guide the model to generate an output.
- Example: There is a set of bricks. For brick B, the color is yellow. The yellow brick C is on top of the brick B . The yellow brick A is on top of the brick C . Now we have to get a specific brick. The bricks must now be grabbed from top to bottom, and if the lower brick is to be grabbed, the upper brick must be removed first. How to get brick B?
- Pros: Ensures structured and consistent outputs for complex tasks and can do it in fewer reasoning steps than CoT.
- Cons: Limited to tasks fitting predefined formats. Error in earlier stages can also propagate worsening performance.
- Use Cases: Structured outputs like lists, tables, or decision matrices such as report generation and data extraction.
6. Meta Prompting
- Description: This is an advanced strategy focusing on the structural and syntactical aspects of tasks and problems rather than their specific content details. The goal is to construct a more abstract way of interacting with LLMs emphasizing form and pattern over content-centric methods like Few Shot Prompting.
- Example: Find the solution to x² = y² + 2xy + 15 and y² = 15x + 3y.
- Pros: Improves transparency, justifies logic and is token efficient since we focus on structure rather than detailed content.
- Cons: May produce verbose or redundant explanations.
- Use Cases: Tasks requiring accuracy or complex reasoning such as mathematical problem solving, coding challenges and theoretical queries.
7. Self Consistency
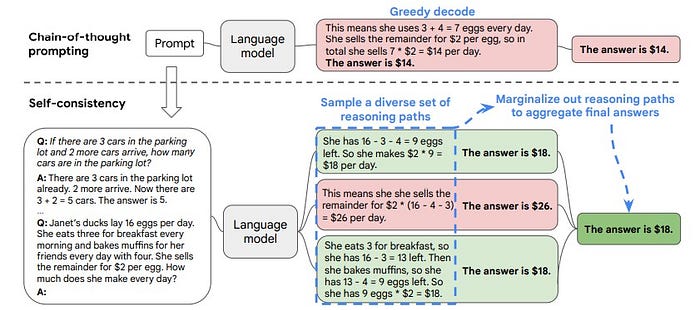
- Description: Encourages the model to evaluate its own outputs and ensure consistency. It does this by replacing the naive greedy decoding using in CoT by sampling multiple, diverse reasoning paths through few-shot CoT and use the generations to select the most consistent answer.
- Example: Explain why your solution to the problem is correct.
- Pros: Very useful in high-stakes tasks requiring accuracy. It increases output reliability and reduces errors for critical tasks.
- Cons: Response times can be huge since we explore multiple reasoning paths.
- Use Cases: Tasks involving commonsense or arithmetic reasoning.
8. Prompt Chaining
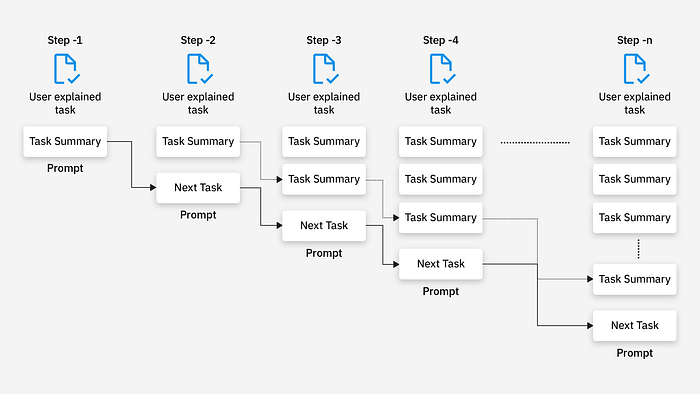
- Description: Here, we break down a complex task into smaller sub-tasks, with each output feeding into the next prompt.
- Example: Generate an outline for a report, then expand each section in subsequent prompts.
- Pros: Drastically simplifies complex workflows.
- Cons: Requires careful planning and sequencing.
- Use Cases: Multi-step processes like report writing or project planning.
9. Tree of Thoughts (ToT)
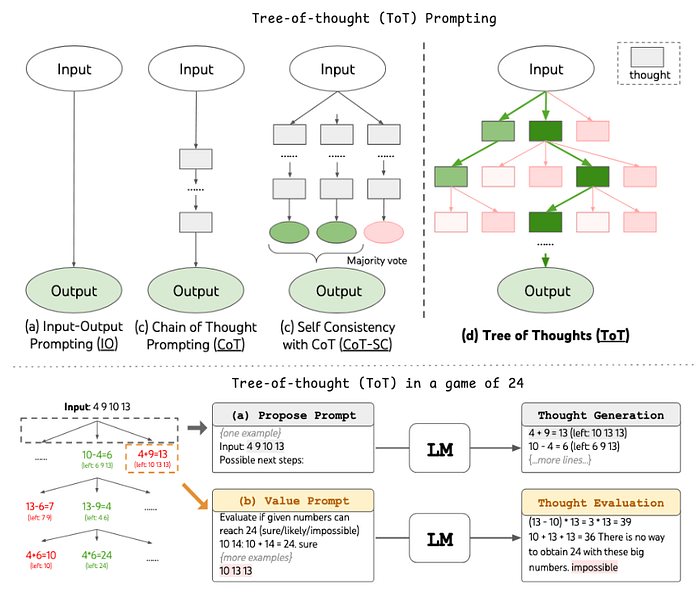
- Description: Explores multiple reasoning paths simultaneously, similar to brainstorming. Broadly speaking, it involves 2 components — thought generation and though evaluation
- Example: Suggest three different ways to reduce traffic congestion in urban areas with pros and cons of each.
- Pros: Encourages creativity and diverse perspectives.
- Cons: May not always be accurate
- Use Cases: Very good for tasks requiring exploration or strategic look ahead like decision making, brainstorming, report writing or project planning.
10. Multimodal Chain of Thought (Multimodal-CoT)
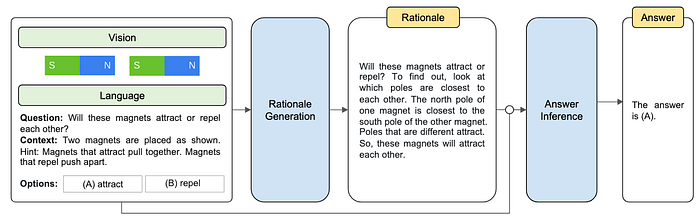
- Description: Here, we combine textual reasoning with other modalities like images, audio, or videos. It prompts the model to analyze and integrate information from various sources to provide a cohesive response.
- Example: Describe the provided image of a solar panel installation, then write a short paragraph explaining how solar energy is converted into electricity.
- Pros: Allows for richer and more contextually aware outputs while expanding the model's ability to handle tasks that involve multimedia.
- Cons: Requires compatibility with models capable of processing multiple types of input. They are also more computationally intensive.
- Use Cases: Tasks requiring visual / auditory reasoning alongside textual reasoning such as image captioning, video script generation, multimedia analysis and storytelling with visual ads.
11. Graph of Thoughts (GoT)
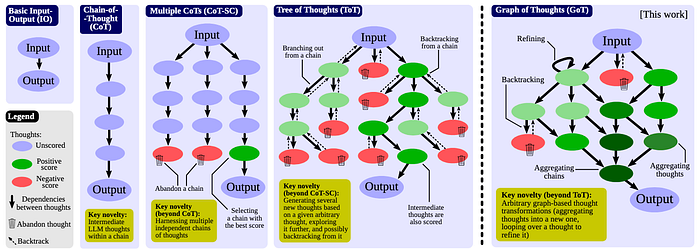
- Description: This strategy structures reasoning as a network of interconnected ideas instead of following a linear approach (for example, CoT). It maps out multiple relationships, paths, or conclusions, allowing for deeper and more flexible reasoning.
- Example: Analyze the factors influencing climate change. Create a network of interconnected causes, effects, and potential solutions.
- Pros: Encourages exploration of complex, multifaceted problems and reveals relationships between ideas that may not be obvious in a linear approach.
- Cons: Outputs can become overly complex to interpret without careful constraints, hence the user may require advanced prompts to ensure relevance and focus.
- Use Cases: Complex problem solving and brainstorming tasks such as systems analysis, mapping relationships in datasets and brainstorming interconnected ideas.
13. Automatic Multi-Step Reasoning and Tool Use (ART)
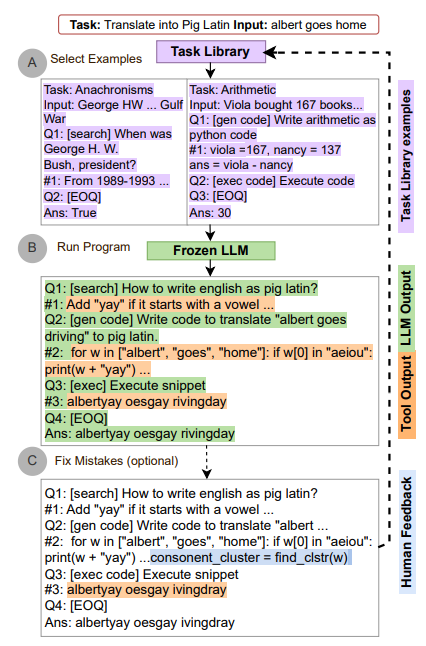
- Description: Here we integrate the LLM with external tools (e.g., APIs, databases, calculators, MCPs) to enhance its reasoning capabilities. It's particularly useful for fact-checking or performing tasks beyond the model's training data. The prompt directs the model to use external resources during computation or generation.
- Example: Use a calculator API to determine the compound interest for a principal of $10,000 at a 5% annual interest rate over 3 years. Explain the steps.
- Pros: Leverages external tools for accurate and up-to-date information.
- Cons: Requires integration with external APIs or tools which is generally complex to setup.
- Use Cases: Tasks requiring precision, real-time data or external tool usage such as financial calculations, retrieving live data, and integrating with APIs for automation.
13. Chain of Draft

- Description: CoTs verbose approach often results in high computational costs and latency, which this strategy addresses by generating multiple drafts or iterations of a response. Each draft builds on or refines the previous one, ensuring a polished and high-quality output.
- Example: Draft a 200-word blog introduction about the importance of cybersecurity. Then refine it to make it more engaging and concise.
- Pros: Produces high-quality and polished outputs by allowing iterative improvement and refinement, reduces response times and is generally more cost-effective.
- Cons: It requires larger models (>3B parameters) for optimal performance, is less effective in zero-shot scenarios, and sometimes requires manual intervention between iterations to guide refinement
- Use Cases: Structured reasoning and content heavy tasks such as copy-writing, content creation, and editing workflows.
14. Retrieval Augmented Generation (RAG)
- Description: For more complex and knowledge intensive tasks, LLMs require access to external knowledge sources in order to enable factual consistency and improve reliability. In this approach, the LLM retrieves relevant, up-to-date information to enhance the response combining an information retrieval component with a text generator model.
- Example: What was the score of Athletico Madrid vs FC Barcelona today?
- Pros: Ensures factual accuracy by referencing trusted sources.
- Cons: It does not scale well for complex tasks and outputs are sometimes skewed towards the retrieved knowledge instead.
15. ReAct (Reasoning + Acting)
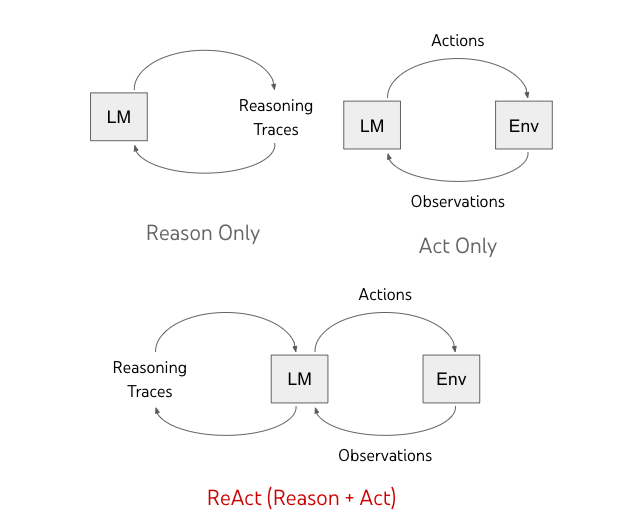
- Description: CoT prompting, although good at reasoning tasks, encounters a lot of fact hallucinations due to lack of access to external world or inability to update its knowledge. To conquer this, ReAct prompts the model to generate verbal reasoning traces and actions for a task allowing it to perform dynamic reasoning to create and adjust plans for acting while using external tools or APIs for verification.
- Example: Check the current stock price of Tesla using an API and explain its recent trends.
- Pros: Reduces reliance on the model's internal knowledge and increases reliability.
- Cons: Complex tasks require more demonstrations to learn well, and can easily go beyond the input length limit of in-context learning.

16. Chain of Verification (CoVe)

- Description: This strategy involves prompting the model to verify its own output by double-checking facts or reasoning.
- Example: Recheck your answer to ensure it aligns with the facts provided in the source material.
- Pros: Encourages accurate self-assessment.
- Cons: It does not completely remove hallucinations and can generate incorrect results.
17. Chain of Notes (CoN)

- Description: The core idea of this strategy is that the model keeps an ongoing record of its reasoning and decision-making process, ensuring systematic assessment of their relevance to the input question before formulating a final response.
- Example: As you solve this, list all assumptions and steps you are taking to reach the conclusion.
- Pros: Helps trace errors and ensures logical consistency.
- Cons: Increased inference costs and longer response times due to the sequential generation of notes.
Tools To Implement These Techniques
Interacting with LLMs and applying our own prompting strategies have become significantly easier thanks to a variety of frameworks being developed to support this ecosystem. Here we'll give brief introductions to some of the more commonly used tools and how they empower developers to maximize their capabilities.
LangChain
LangChain is a flexible framework for building applications that integrate LLMs with external tools and data. It supports features like memory, chaining, agents, and APIs for tasks like summarization, web scraping, and code generation. The best part is that they provide seamlessly integrations to cloud platforms, databases, and search engines, making it ideal for creating intelligent, data-aware applications.
Semantic Kernel
Semantic Kernel is an SDK enabling you to easily describe your LLM application's capabilities using plugins that can be run by the kernel. It supports AI plugins, embedding-base memory, and intelligent task planning, enabling apps to interact with external knowledge and proprietary data. It is lightweight and mostly ideal for integrating LLMs into C# or Python applications for tasks like retrieval-augmented generation and reasoning.
Guidance

Guidance is another templating framework for controlling LLMs like GPT-4. It uses a simple syntax to create structured outputs, supports advanced prompt engineering techniques, and integrates seamlessly with tools like Jupyter Notebooks. Features like token healing, regex matching, and caching make it ideal for optimizing LLM performance in tasks like content generation and multi-step reasoning.
AutoGPT
Finally, AutoGPT is another open-source AI agent that autonomously breaks down user-defined goals into sub-tasks and executes them using GPT-4. It supports internet searches, memory management, and self-prompting, making it ideal for automating workflows and achieving complex objectives. While very powerful, it is to be noted that it has its limitations like occasional inaccuracies, and dependency on external tools.
Conclusion
In summary, effective prompt design is very crucial to harness the full potential of LLMs, especially for complex tasks. If we stick to the aforementioned best practices, ensure that our prompts are clear, specific, and concise, we can significantly improve the quality and accuracy of the outputs generated by these models. Using advanced techniques such as few-shot, chain-of-thought, RAG or ART make the responses even better! In the end, all you need to remember is:
The better the instructions, the better the results!
Enjoyed this post? Help me share this knowledge with others by clapping, and sharing your thoughts. You can follow me on Medium / LinkedIn for more insights on C++, Python, Robotics and Trading algorithms.
Check out my Productivity Bundle 🧑🏻💻 — featuring easy-to-use tools like budget planners, habit trackers, and trading journals to help you stay organized while coding your way to success!