

I spent many years building machine learning systems the "traditional way": SQL notebooks for exploring features, half‑maintained Python scripts for dataset creation, cron jobs or Airflow to keep things running, and last‑minute real‑time feature store wiring when a model finally went live. Everything "worked well enough", until something changed. At that point, every piece became technical debt.
FeatureByte was the first platform I used that actually replaced most of this disconnected glue with a coherent, automated system, not just another feature store. It felt like a real ML engineering platform rather than a bunch of tools duct‑taped together.
Not Just a Feature Store : A Smart Data Science Agent
FeatureByte isn't positioned as "another feature store."
It behaves more like a full ML orchestration and automation platform built around feature definitions, but with something extra: semantic understanding and automated feature ideation.
Once you model your data correctly and define logical features declaratively, FeatureByte automates training dataset builds, scheduling, real‑time serving, versioning, governance, and more, all without the usual scripting and pipeline glue.
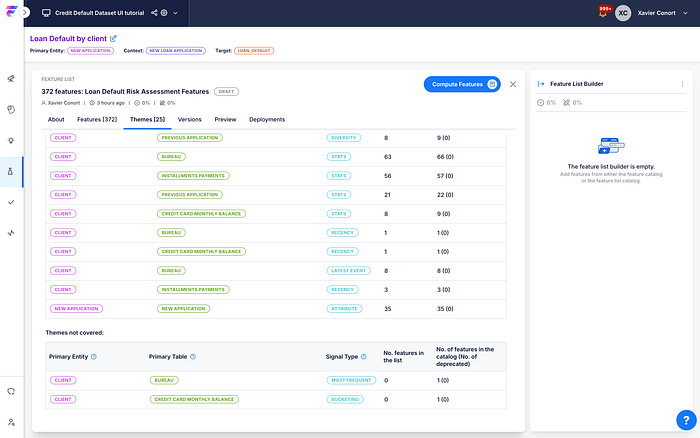
Importantly, everything runs directly in your data warehouse (Snowflake, BigQuery, Databricks, Spark). FeatureByte compiles logic into SQL and orchestrates jobs on your existing systems, no proprietary compute layer, no moving data off‑platform.
Most platforms handle only one slice of the ML lifecycle. FeatureByte covers the full data → training → serving loop consistently.

What Finally Felt Different
Most platforms only handle one slice of the ML lifecycle.
What stood out about FeatureByte was that it consistently covers the full loop: data → features → models → serving → governance.
But even more than that, the automation layer, especially around understanding data semantics and generating feature ideas, is what really changes the game.
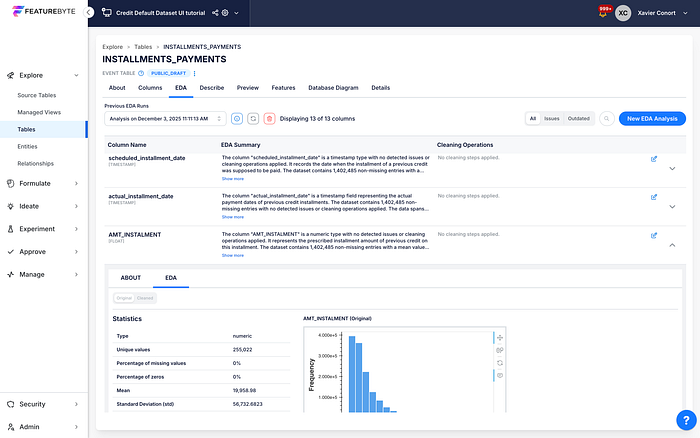
Smart Feature Ideation and Semantic Understanding
Instead of just storing features, FeatureByte understands your data's meaning. It uses semantic tagging and data ontology to interpret table structures and column types. On top of that, AI‑driven feature ideation automates the discovery and suggestion of high‑value features for your use case, all tailored to your data's context.
This means:
- You get relevant feature ideas automatically
- Semantic context guides transformations
- You don't spend weeks hand‑crafting feature logic
This automation layer reduces manual work and speeds up model development drastically.
One Definition, Many Uses
In FeatureByte, a feature isn't just a column, it's a versioned computation graph that expresses:
- Joins and lookups
- Temporal aggregations
- Filters and math operations
- Ratios and time offsets
Once defined, the same logic automatically powers:
- Training dataset creation
- Batch scoring jobs
- Real‑time serving
No more rewriting logic three times for train, batch, and online.
The Catalog: Where Everything Lives
The Catalog becomes your control center:
- Registered warehouse tables and logical sources
- Entities such as customers or items
- Semantic feature definitions
- Feature lists tied to models
- Active deployments and pipelines
This unified workspace lets you:
- Search and reuse features
- See what feeds which models
- Track which pipelines are live
It turns tribal knowledge and scattered scripts into a navigable, governed system.
Data Modeling Actually Matters Here
FeatureByte encourages upfront table classification:
- Event tables
- Item / transaction tables
- Time series tables
- Slowly changing dimension tables
- Static dimensions
This semantic layer prevents many common mistakes, like accidental joins or time leakage. The platform's understanding of data structure is like an early warning system for pipeline bugs that plain SQL never catches.
Entities Enable Correct Pipelines
Entities define what a "unit" is (e.g., customer ID). With entities:
- Aggregations resolve automatically
- Train and serve logic align
- The system knows how to route batched and real‑time requests
This makes both offline dataset generation and online inference consistent.
Feature Lists: Durable Model Inputs
FeatureByte formalizes the inputs models consume through Feature Lists, collections of features that:
- Define training dataset structures
- Drive real‑time serving workflows
- Act as versioned dependencies for models
Any change to the list propagates deterministically to downstream pipelines.
Training Pipelines Without Custom SQL
Training data is created using observation tables that contain entity–timestamp pairs. FeatureByte guarantees:
- Point‑in‑time accuracy
- No leakage from future data
- Fully materialized warehouse tables ready to train on
No hacky SQL joins or manual time alignment code required.
Real Production Serving
FeatureByte supports both:
- Batch scoring pipelines (feature‑enriched tables)
- Online serving pipelines (low‑latency features)
Both modes use the same definitions and schedules, eliminating mismatches.
Scheduling Without Airflow Headaches
Each feature has:
- Frequency settings
- Delay "blind spots" for lateness
- Time zone alignment
FeatureByte handles ingestion, recompute, and serving updates, all automatically. No Airflow DAGs. No cron glue.
Governance Built In
Governance isn't an afterthought. FeatureByte provides:
- Versioning
- Lifecycle states (draft → production → deprecated)
- Full lineage tracking
- Semantic tagging
- RBAC and audit logs
Everything is traceable and reproducible.
Strengths I've Seen in Practice
What I appreciate most:
- One logical definition drives both training and serving
- Semantic and automated feature ideation
- Feature lists as a durable contract
- Minimal manual orchestration work
- Built‑in lineage and governance
- Rapid model iteration thanks to automation
If you've spent years maintaining brittle pipelines, FeatureByte feels like installing a proper engineering foundation rather than applying duct tape.
Limitations
FeatureByte isn't magic:
- It depends on warehouse performance
- Unsupported warehouses need custom care
- New automated features or pipelines still need human oversight.
These are typical of any platform of this scale, but the automation and semantic understanding help more than they hurt.
Final Thoughts
Using FeatureByte feels less like adopting a "feature store" and more like extending the ML team with an intelligent data science agent powered by automation, semantic understanding, and AI‑driven feature ideation. It doesn't replace modeling expertise, but it eliminates entire categories of engineering work that usually slow projects down the most.
Try the platform here: https://featurebyte.ai