
I would be overjoyed if you could support me as a referred member. However, the income I've received from my contributions on this platform has not proven sufficient to sustain the frequency of updates I'd hoped for. Facing this reality, I've made a difficult decision — to explore new income avenues. However, this isn't the end; rather, it's an exciting new beginning. I am thrilled to announce my upcoming Substack newsletter, where I'll delve into my investing system, harnessing the immense potential of IT technology and embracing a system-thinking approach to investment strategies. Rest assured, I will still be posting when inspiration strikes.
Performance Optimization: Enhancing System Efficiency
(A) Accelerating Queries with Indexes
Different data structures offer various advantages for database query speeds. Here are some commonly used index data structures and their applications in different query scenarios:
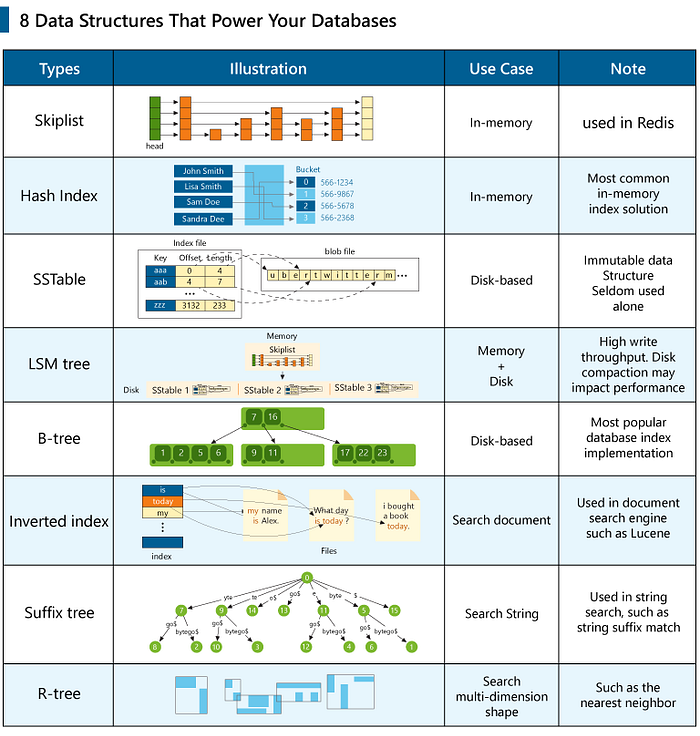
(1) B+ Tree
A B+ tree is a balanced multi-way search tree widely used in relational databases.
Characteristics:
- Balanced structure: All leaf nodes are at the same level, ensuring efficient query performance.
- Multi-way search: Each node can have multiple children, supporting efficient range queries and sequential access.
- Linked leaf nodes: All leaf nodes are linked by pointers, facilitating sequential scanning.
Use Cases:
- Range queries: The linked leaf structure makes B+ trees ideal for range queries, as movement between leaves is efficient.
- Ordered queries: B+ trees are also suitable for queries requiring sorted results due to their ordered leaf nodes.
Selection Strategy:
- Frequent range queries: If your application frequently performs range queries, a B+ tree is an ideal choice due to its efficiency in handling such queries.
(2) LSM Tree
An LSM (Log-Structured Merge) tree is a disk-oriented, log-structured data structure optimized for batch write operations.
Characteristics:
- Log-structured writes: Data is appended in a log format, reducing disk I/O.
- Tiered storage: Data is divided into levels, each with increasing data volume, maintained by merge operations.
- Write optimization: LSM trees excel in write-heavy environments as write operations only involve appending logs, while read operations use multi-level indexing.
Use Cases:
- Write-heavy environments: Suitable for applications with frequent writes, such as log databases and time-series databases.
- Large data storage: LSM trees' tiered storage and merge mechanism effectively manage large data volumes.
Selection Strategy:
- Systems with frequent writes: If writes greatly outnumber reads, LSM trees are a better choice, reducing write operation costs significantly.
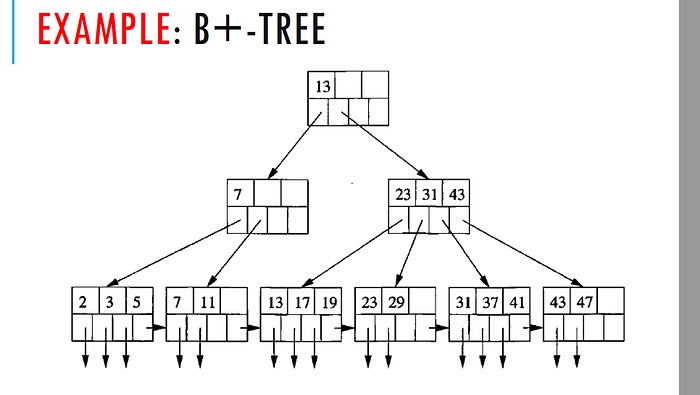
(3) Hash Table
A hash table is a data structure that maps keys to array indices using a hash function.
Characteristics:
- Fast lookup: Provides an average lookup time of O(1), ideal for point queries.
- Key-value storage: Stores data as key-value pairs, suitable for quick retrieval.
Use Cases:
- Point queries: Ideal for scenarios needing fast key-value lookups, such as caches and key-value databases.
- In-memory databases: Provides highly efficient query performance in memory.
Selection Strategy:
- Frequent point queries: If point queries are common, a hash table is optimal for quick lookups.
(4) Skip List
A skip list is a multi-level linked list structure that skips over some nodes to achieve faster lookups.
Characteristics:
- Dynamic structure: Supports efficient insertions and deletions, suitable for dynamic data sets.
- Random access: Offers near O(log n) lookup times due to its layered structure.
Use Cases:
- Dynamic data sets: Ideal for data sets requiring frequent insertions and deletions, such as in-memory databases and caches.
- Concurrent access: The linked list structure performs well in concurrent environments.
Selection Strategy:
- Dynamic data collections: If data changes frequently, a skip list is a good choice due to its efficient dynamic operations.
(5) Bitmap Index
A bitmap index uses bit arrays to represent data presence.

Characteristics:
- Memory efficiency: Occupies less memory, suitable for large data storage.
- Fast lookups: Supports efficient bitwise operations for rapid searches and filtering.
Use Cases:
- Large-scale filtering: Ideal for filtering operations in big data, such as Bloom Filters.
- OLAP systems: Significantly improves query performance in online analytical processing (OLAP) systems.
Selection Strategy:
- Big data filtering: For quick filtering of large data sets, a bitmap index is an excellent choice.
(6) Trie Tree
A trie tree is a prefix tree designed for efficient string storage and retrieval.
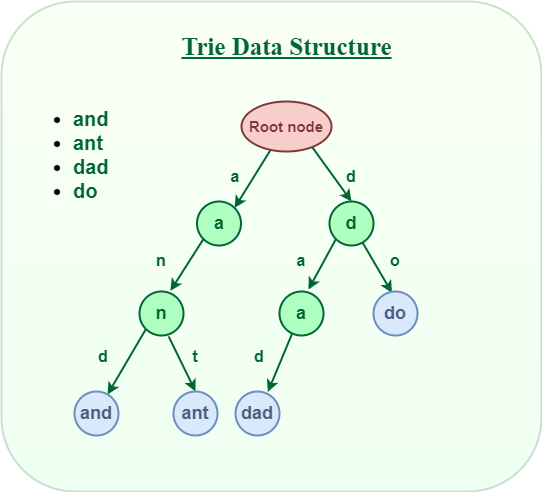
Characteristics:
- Prefix matching: Supports efficient prefix searches, ideal for string queries.
- Space efficiency: Common prefixes are stored once, saving space in large string data sets.
Use Cases:
- Full-text search: Suitable for full-text search and prefix match scenarios.
- Dictionaries and lexicons: Provides efficient lookup and insertion for dictionary data.
Selection Strategy:
- Prefix matching queries: If your application requires frequent prefix searches, a trie tree is an excellent choice for efficient handling.
(7) R Tree
An R tree is a multi-dimensional spatial index used for efficient storage and retrieval of spatial data.
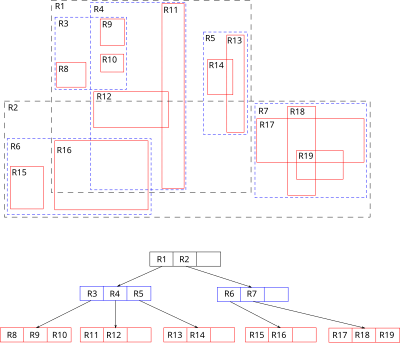
Characteristics:
- Multi-dimensional indexing: Supports indexing in multi-dimensional spaces, suitable for geographic and image data.
- Range queries: Allows efficient range queries for data within specific multi-dimensional areas.
Use Cases:
- Geographic Information Systems (GIS): Widely used for storing and retrieving location data efficiently.
- Image processing: Manages multi-dimensional image features effectively.
Selection Strategy:
- Multi-dimensional range queries: If your application requires multi-dimensional range searches, an R tree is ideal for handling spatial data efficiently.
By selecting and using these data structures appropriately, database query speed and efficiency can be significantly improved. Each structure has unique strengths and applicable scenarios, so database system design should align with specific requirements and data characteristics.
Space Saving with Compression Algorithms
Compression algorithms are powerful tools for reducing data size, improving storage efficiency, and lowering costs. However, they often trade space savings for increased CPU usage, particularly during decompression.
Choosing the Right Algorithm
High Compression Ratio Algorithms
- Advantages: Maximize disk space savings; ideal for infrequent access or archival data.
- Disadvantages: Slower decompression speeds and higher CPU usage.
- Examples: Backup files, log files, and historical records.
- Examples: LZMA, DEFLATE.
Fast Decompression Algorithms
- Advantages: Quick decompression; ideal for real-time or high-frequency access scenarios.
- Disadvantages: Lower compression ratios, saving less space.
- Examples: Real-time log analysis, online data processing, caching systems.
- Examples: LZ4, Snappy.
Balanced Algorithms
- Advantages: Strike a balance between compression efficiency and decompression speed; suitable for general use.
- Disadvantages: May not perform optimally in highly specialized scenarios.
- Examples: Web server caching, file transfers, general-purpose storage.
- Examples: Zstandard (zstd), DEFLATE.
Data Types
- Text Data: Typically compressed using LZ Encoding or Huffman Coding.
- Image and Audio Data: Use lossy algorithms like JPEG and MP3 for significant size reductions at the expense of data fidelity.
- Binary Data: Specialized algorithms such as BDI (Base-Delta-Immediate) or C-PACK (Cache Packer) are effective.
Evaluation Metrics for Compression Algorithms
- Compression Ratio: Measures how much space is saved compared to the original size.
- Decompression Speed: Time required to decompress data.
- Compression Speed: Time required to compress data.
- CPU Usage: CPU consumption during compression and decompression.
- Memory Usage: Memory resources consumed during the process.
Using Caching to Improve Performance
Caching is a widely used technique to improve system performance by storing frequently accessed data on faster storage media. This reduces data access times and enhances efficiency. Caches are generally categorized into memory cache and disk cache, each with distinct characteristics and use cases.
(A) Memory Cache
Memory caching stores data in a computer's RAM, enabling quick access.
- High-speed access: Memory cache access speeds are extremely fast, typically in the nanosecond range, making it ideal for applications requiring rapid responses.
- Limited capacity: RAM is costly, so memory cache has limited storage capacity and cannot hold large data sets.
- Volatility: Data stored in memory cache is lost after a system restart, making it unsuitable for persistent data storage.
Applications
- Frequently Accessed Data: Memory caching is perfect for data that is read or written frequently, reducing I/O time.
- Critical Business Data: Product information on an e-commerce site can be cached to speed up page loads.
- Real-Time Data Processing: Systems requiring quick responses, such as stock trading platforms or real-time analytics, benefit from memory caching.
- Hotspot Data: Frequently accessed ("hot") data can be stored in memory to offload database queries.
Examples
- Redis: A high-performance memory caching system widely used for session storage and hotspot data.
- Memcached: A popular in-memory key-value store for simple and fast caching.
(B) Disk Cache
Disk caching stores data on persistent storage media such as hard drives or SSDs for quick retrieval.
- Large capacity: Disk caches can store vast amounts of data, unlike memory caches.
- Slower access speed: Access times are slower than memory caches, typically in the millisecond range.
- Persistence: Disk caches retain data even after a system restart, making them suitable for durable data storage.
Applications
- Large Data Sets: Disk caching is ideal for storing extensive datasets like static resources, logs, or historical data.
- Data Persistence: Data that must persist after a system restart, such as configuration files or database snapshots, fits well in disk caches.
- Reducing Server Load: Static resources like images and videos can be cached on disk to lighten server workload.
- Backup and Recovery: Disk caches can be used for temporary storage during backups or data restoration processes.
Examples
- TempDB in SQL Server: Temporarily stores query results and improves database performance.
- Filesystem Caches: Operating systems use disk caching to speed up file access.
Cache Strategy Selection
Selecting a caching strategy depends on system requirements and data characteristics.
(A) High Responsiveness and Frequent Data Access
- Choice: Memory Cache
- Reason: Fast access speeds make memory caching suitable for scenarios demanding low latency and high performance.
- Examples:
- E-commerce product pages
- Real-time data analytics
- Session management systems
(B) Large Data Storage and Persistence
- Choice: Disk Cache
- Reason: Disk caching's large capacity and durability are ideal for storing extensive datasets and ensuring data persists.
- Examples:
- Static resource storage (e.g., images, videos)
- Log files and historical records
- Data backup systems
(C ) Multi-Tier Caching Strategy
- Combines memory and disk caches, leveraging their respective strengths in a layered hierarchy.
Features
- Tiered Storage: Data is first stored in memory cache, and excess or less-frequently accessed data is moved to disk cache.
- Flexible Performance: Provides high-speed access through memory cache and high-capacity storage via disk cache.
- Data Consistency: Properly designed multi-tier strategies ensure consistent data across layers.
Applications
- Systems with mixed requirements, such as low-latency access and large storage needs.
- Distributed systems where multi-tier caching manages distributed data efficiently.
Examples
- Redis + Disk-Based Cache: Store frequently accessed data in Redis, and move overflow data to disk storage when memory is insufficient.
- In-Memory Database + Persistent Backup: Store frequently accessed data in an in-memory database while periodically backing up to persistent storage.
If you've found any of my articles helpful or useful then please consider throwing a coffee my way to help support my work or give me patronage😊, by using
Last but not least, if you are not a Medium Member yet and plan to become one, I kindly ask you to do so using the following link. I will receive a portion of your membership fee at no additional cost to you.