
The gradient descent is a method that is popular in many areas. It is used in various deep-learning models and optimization problems. The technique is a fundamental approach to minimizing some functions that we don't know exactly what approach to minimize, such as deep learning layers.
Deep learning layers are linear map functions. They try to map the input data X to the target vector y. Layers are a powerful method in deep learning models. However, we need to find the weight of layers that minimizes the error between the prediction vector and the target vector. Finding the optimal weight is a very hard task.
This article is going to explain the basic concept of gradient descent. Also, we will dive deep into PyTorch code that implements gradient descent.
Basic Concept of Gradient Descent
A good way to understand this concept is to visualize, visualize, and visualize the problem that we need to minimize.
The example problem used in this article is:
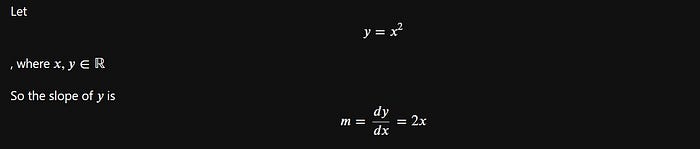
Although that is a very simple function, it can be a good example to visualize. We need to plot the function and its slopes:
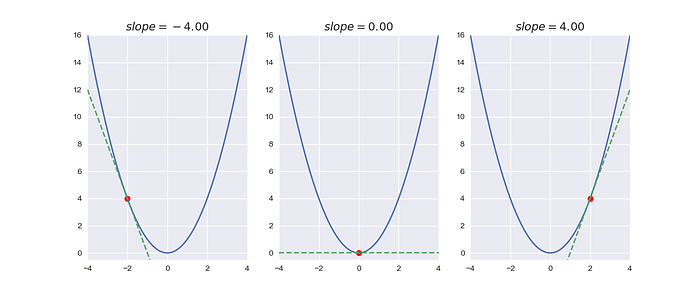
Each point on the function has a different slope. Also, the lowest value of the function has a slope of 0. We notice the directions of the slopes forward into the optimal solution, right?
What if we move the point by direction of the slope line?
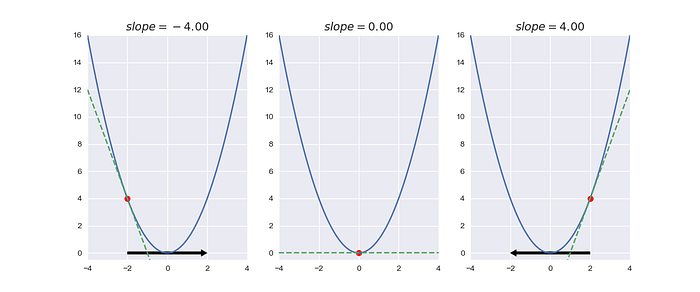
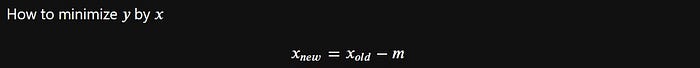
Let's do it.
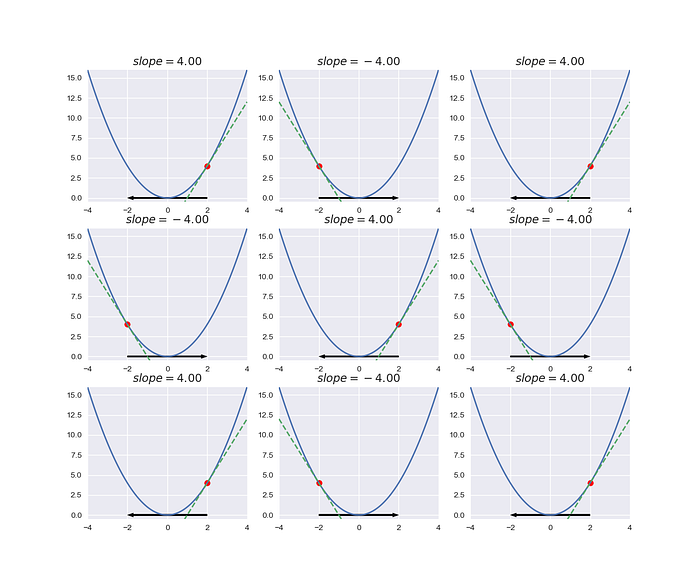
The above image shows our experiment. We think it will work well but the point is to swing between two points. Hmmm, how do we fix it?
Ahaaaa, why do we reduce the value of slopes? The way to reduce the slope is to multiply it by the learning rate.
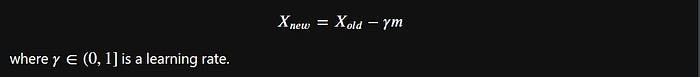
Let's try it.
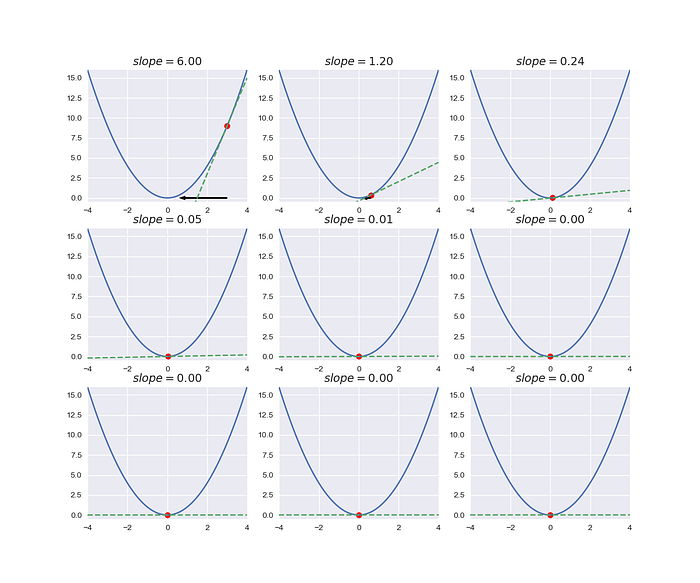
Amazing, we can implement the gradient descent in a simple function. In the next step, we are going to the code section. Let's go!
Auto-Grad in PyTorch
How to find the gradient and the slope at point 𝑥 with PyTorch? In the first step, we need to define the function defined by the PyTorch code.
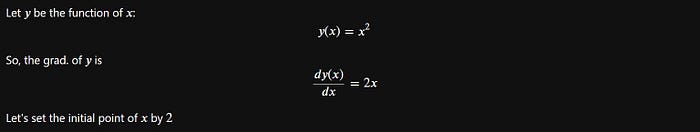
Let's code the above function:
import torch
# Set the initial point of x
x = torch.tensor(2.0, requires_grad = True) # requires_grad = Do we need to get the grad from x
# Set our function
y = x**2Ok, we have a function to experiment with the gradient descent method. We should explore each data first.
What about the x and y?
x
# tensor(2., requires_grad=True)
# grad's value before backward => None
x.gradHmm, the grad of x doesn't return some value. Let's try the backward method in y:
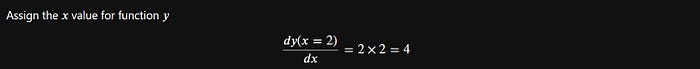
# backward the function to find the grad.
y.backward()And let's try to print out the grad of x again.
# grad's value after backward => 4
x.grad
# tensor(4.)Alright, we get the tensor(4.) value from x.grad.
In the PyTorch, It accumulates the value of the backward method. So, we need to set the grad value to zero again.
# set the grad to zero again
x.grad.data.zero_()
# tensor(0.)Experiment's gradient descent with PyTorch
We need to set the function optimized by our method. In this case, we need to find the lowest value of y.
# Set the number of steps
N = 9
# Set our learning rate
lr = 0.1
# set the initial point
x = torch.tensor(4., requires_grad = True)
# set our function that is optimized
y_fn = lambda x: x**2
y = y_fn(x)And, we find the optimal solution on the iteration that minimizes our function:
cost_value = []
for i in range(N):
y.backward(retain_graph=True)
grad = x.grad.data
x.data = x.data - lr * grad
x.grad.data.zero_()
cost_value.append(y_fn(x.data))
# print(f"iteration: {i}\ngrad: {grad}\nx: {x.data}\ny:{y_fn(x.data)}")
# print('='*25)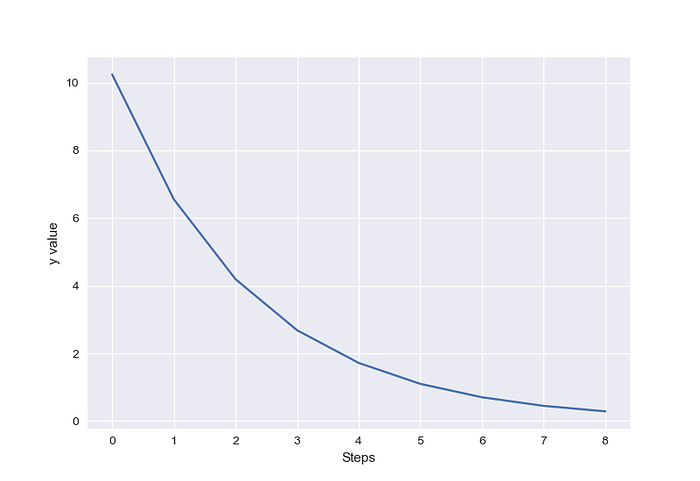
The values of y go down for each step. Wow, this is good work. We can implement the gradient descent with PyTorch.
If you enjoy reading code, you can find code from this link:
Enjoy it. If you like my content, you subscribe to my medium.