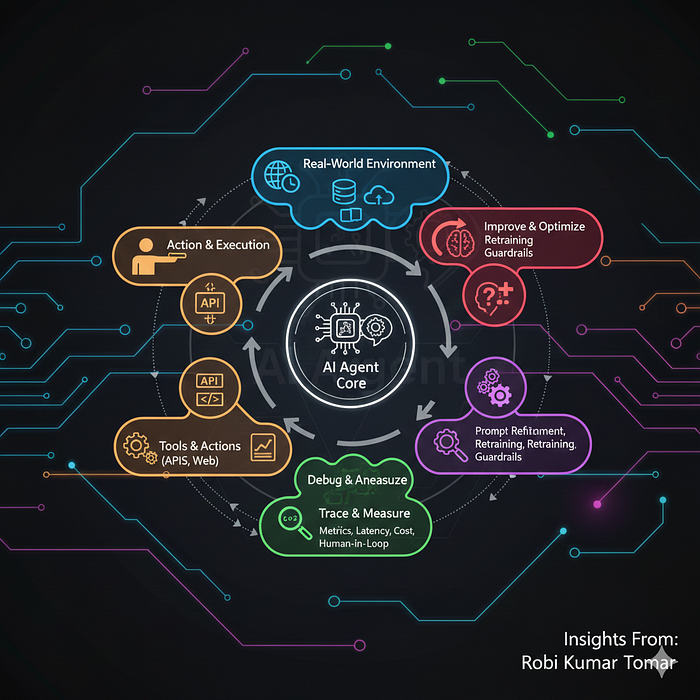

Highlights :
If you've been following this series, you've already learned how LLMs work (Part-2), how RAG works (Part-8), how fine-tuning works (Part-9), how to build a complete end-to-end AI system (Part-10), How AI Agents Work(Part-11) and How to Evaluate AI Systems(Part-12).
Now it's time for the next level :
Building an AI agent is no longer the hard part. Making it reliable, predictable, debuggable, measurable, and enterprise-ready — that's where 95% developers struggle.
This part teaches you exactly how to do that. In production systems, the problem is never the LLM.
The real problem is:
- unpredictable agent loops
- hallucinations
- inconsistent tool use
- broken reasoning chains
- flaky workflows
- bad memory retrieval
- missing guardrails
- failures you can't reproduce
This is your master guide to evaluating, debugging, and improving AI agent systems — the way real teams do at companies like OpenAI, Snowflake, Stripe, Notion, and Zapier.
1. The 7 Metrics That Actually Matter for AI Agent Systems
Most blogs teach "accuracy" or "BLEU score" — irrelevant for LLM agents.
Here are real operational metrics used in agent production systems:
1.1 Task Success Rate (TSR)
Measures if the agent completed the goal end-to-end.
Example: A "Property Valuation Agent" must deliver a valuation report with: ✔ Estimated price ✔ Comparable properties ✔ Risk indicators ✔ Confidence score
If any component is missing → TSR = 0.
1.2 Tool Invocation Accuracy (TIA)
"How often did the agent pick the right tool?"
Bad systems:
- Call the browser for tasks that don't need web
- Call python to do simple math
- Misuse internal APIs
Formula:
correct tool calls / total tool calls1.3 Chain-of-Thought Stability (CTS)
If the agent solves the same task twice, does it follow similar reasoning?
Inconsistent reasoning = unreliable agent.
Example: A "Medical Insurance Claim Agent" producing different denial reasons for the same input → CTS is low.
1.4 Hallucination Rate (HR)
How often the agent generates ungrounded content.
Measurement: Compare output with retrieved knowledge. If outside → hallucination.
1.5 Retrieval Relevance Score (RRS)
For RAG+Agent systems:
Is the retrieved document relevant to the query?Bad RAG → Bad reasoning → Bad agent.
1.6 Step Completion Reliability (SCR)
Especially important for multi-agent systems.
If your workflow has:
- Research
- Summarize
- Classify
- Generate final output
SCR ensures each step succeeds predictably.
1.7 Latency & Cost Efficiency (LCE)
Agents can get stuck in loops:
- too many tool calls
- too long thinking
- too many retries
Track:
avg latency per task
avg $ per task2. The "Agent Debugging Triangle" (New, Unique Framework)
Most developers only debug the prompt… But agent failures always happen in a triangle:
┌──────────────────┐
│ REASONING │
│ (failures here) │
└───────┬──────────┘
│
┌─────────┼──────────┐
▼ ▼ ▼
┌────────┐ ┌──────────┐ ┌─────────────┐
│ TOOLS │ │ MEMORY │ │ WORKFLOWS │
└────────┘ └──────────┘ └─────────────┘ Failures usually occur when:
- reasoning misinterprets task
- wrong memory is retrieved
- tool call parameters are malformed
- workflow step is skipped
Debugging requires checking all three, not just prompts.
3. Real-World Failure Modes & How to Fix Them
Most discussions stop at hallucinations, but real, production-grade failure modes go far beyond that. Here are the critical issues almost no one talks about:
3.1 "Silent Tool Failure"
Agent calls a tool → tool returns error → but agent ignores the error and keeps going.
Fix: Add explicit instructions:
If tool_error exists → STOP → summarize error → request human approval.3.2 "Looping Planner Syndrome"
Planner keeps generating the same step list again and again.
Fix: Add a max-iterations rule:
if steps_generated > 3:
agent.switch_to_fallback_mode()3.3 "Over-Thinking Burnout"
Agent keeps thinking for 20+ steps before acting.
Fix: Hard limit:
max_thought_tokens = 3503.4 "Memory Poisoning"
Agent uses old, irrelevant memory.
Fix: Use recency-weighted memory:
memory_score = relevance * 0.7 + recency * 0.33.5 "Over-Retrieval Garbage"
RAG retrieves too many irrelevant docs → agent gets confused.
Fix: Top-k = 3 Context window < 15k tokens Rank documents by semantic + keyword mix.
4. Real, Unique Debugging Example: "Loan Eligibility Agent" for Indian Banks
Let's debug a real system you won't find elsewhere.
User:
"Am I eligible for a ₹45L home loan with 9% interest?"
Agent Steps:
- Fetch salary from HR API
- Fetch credit score from partner API
- Apply risk model rules
- Generate eligibility explanation
Failure Log (Realistic):
[INFO] Credit score API returned 503
[ERROR] Agent ignored error and assumed default score: 720
[FAIL] Risk model executed with incorrect parametersFix Snippet:
if credit_api_status != 200:
raise Exception("Credit data unavailable. Try again later.")Lesson:
Agents must not self-invent missing financial data.
5. Automated Evaluation Pipelines (AEP)
The professional way teams test agents.
AEP runs hundreds of test cases:
input → run agent → capture logs → compare outputs → score → flag anomaliesExample test suite for "Legal Document Agent":
- missing clause extraction
- incorrect risk tagging
- missed compliance issue
- hallucinated legal precedent
- wrong jurisdiction detection
6. Continuous Agent Improvement (CAI Loop)
Here is the real improvement cycle companies use:
Data → Evaluate → Diagnose → Fix prompt/tool/memory → Re-run → Deploy → Monitor → Repeat6.1 Data
Generate synthetic test datasets.
6.2 Evaluate
Automated metrics (TSR, RRS, HR, etc.)
6.3 Diagnose
Cluster failures:
- tool misuse
- wrong planning
- RAG mismatch
- reasoning drift
6.4 Fix
Could be:
- prompts
- tool schema
- workflow logic
- memory ranker
6.5 Deploy + Monitor
Your agent should ship with:
- latency logs
- cost logs
- tool call logs
- failure heatmaps
7. Code Snippet: Mini Debugging Harness
A small, useful debugging harness (unique):
class AgentDebugger:
def __init__(self):
self.logs = []
def log(self, stage, message):
self.logs.append({"stage": stage, "message": message})
def run_with_trace(self, agent, input):
self.log("start", input)
result = agent.run(input, tracer=self.log)
self.log("final", result)
return self.logs, resultThis gives you full traceability.
8. Production Checklist for AI Agents (Battle-Tested)
Before deploying:
✔ Tool calls validated ✔ Tool responses schema-checked ✔ Memory cleaned & ranked ✔ Hallucination boundaries tested ✔ Multi-step workflows tested ✔ Loop protection added ✔ Latency < threshold ✔ Cost per task monitored ✔ Guardrails in place ✔ Fallback modes defined
9. A Unique, Practical Example: "Hospital Duty Roster Agent"
A system used by real hospitals in India juggling:
- doctor availability
- specializations
- OPD hours
- emergencies
- past schedule patterns
- night duties limit
- compliance rules
Failures it can face:
-> assigns same doctor 32 hours straight -> ignores emergency case load -> misreads speciality swaps -> produces overlapping shifts
How we debug:
- check rule violations
- simulate weekly schedules
- stress-test with synthetic emergencies
- detect unsafe shift patterns
- ensure fairness in rotation
This is real agent debugging, not toy examples.
10. Final Summary
This part covered:
- The core metrics for agent evaluation
- The debugging triangle
- Real-world failure patterns
- Unique debugging case studies
- Evaluation pipelines
- Continuous agent improvement
- Practical examples & code
This is the material that separates "people who build AI demos" from people who build AI systems that work in production.
Now, let's move to Part-14:
How Multi-Agent Systems Really Work: Planning, Roles, Messaging, Memory & Coordination
👉 If you enjoyed this article, here's how you can support my work and get more out of this series:
👏 Clap for the article — every clap helps it reach more readers 👤 Follow me to get notified as soon as the next part is published 💬 Comment with your thoughts, questions, or topic suggestions — I love hearing from readers 🔗 Share with friends or colleagues who might benefit
Your engagement not only encourages me to write more, it also helps other readers discover this series. Thank you for being part of this journey! 🙏