


Reasoning language models often appear to think deeply, but in reality, they are sampling a greater variety of patterns from their training data rather than applying genuine logical abstraction. This simulation of reflection excels in medium-complexity tasks by matching familiar data structures.
Some months ago, I wrote about The Illusion of Thinking and how to evaluate the reasoning capabilities of language models from different perspectives, as outlined by OMEGA. The results of those works indicated that reasoning language models contemplate more patterns before answering, but are not capable of reasoning.
This might explain why those models excel on middle-complexity tasks and are less effective on simple tasks (due to overthinking and adding the probability of falling back to wrong patterns). Another noticeable insight is that these models fail dramatically whenever the task complexity is sufficiently high (suggesting there is no data pattern detected in the training set for that specific configuration).
According to that thesis, reasoning language models don't really reason but rather consider more patterns from the training data before giving an answer, which reinforces the idea of a Stochastic Parrot rather than real intelligence.
However, these Stochastic Parrots are not entirely deterministic even with deterministic settings. This variability may introduce random errors, which are retained within the context length of the language model in multiturn tasks, such as chatbots or agents with a specific inner state.
The Diminishing Returns Behind Language Models
The main objective of The Illusion of Diminishing Returns is to explore alternative culprits for why these models fail in the long run, with a focus on the effect of errors within the context of the language model. The main contributions could be summarised in the following points:
- Making reasoning experiments easier to track and modify by decoupling the planning step from the execution step. Whereas usual reasoning models perform both steps directly.
- Track the long-term context effect on the future tasks executed by the reasoning language model. To effectively track this effect, it is necessary to consider new metrics for the long run.
- Modify the error rate of the language model context for several up-to-date language models, and determine the effect of this change on subsequent iterations.
The main question researchers ask themselves in the paper: How the errors preserved in the input context affect subsequent tasks?
We will discuss these topics in the following subsections.
Decoupling Planning from execution
From what we know about open-source reasoning models, such as Qwen and DeepSeek-R1, these models perform planning and execution in the same environment. This is achieved by the same model, which first creates a plan for the entire execution and then executes every task, step by step.
This poses some difficulties when evaluating the reasoning processes of these language models, which reinforces the idea of black-box systems and makes research on them more tedious.
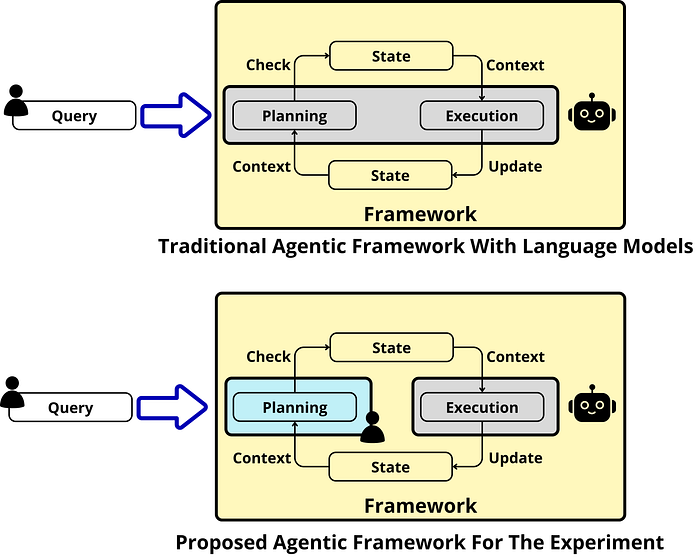
To effectively decouple planning from execution in controlled experiments, researchers designed the entire task planning process. In fact, the plan is completely hardcoded in the official dataset for the experiment, making it programmatically verifiable for experimental convenience. The plan is provided step by step for the reasoning language model, allowing the model to execute only the tasks and avoid any planning process.
The new Horizon Length Metric
To perform the experiments proposed in The Illusion of Diminishing Returns, researchers define the Horizon Length metric, which is determined for a specific accuracy level. This metric measures the number of steps the model takes until its accuracy on the given task drops below a fixed accuracy.
For instance, if we want to create a front-end webpage for our blog, we should select an accuracy threshold of 75%. We will determine the Horizon length by running the task several times and stopping whenever the accuracy falls below 75%, annotating the corresponding step number. Then, we shall calculate the mean of the steps among several runs.
The interesting aspect of this metric is that it is easy to understand and allows us to evaluate different agentic frameworks with several language models running on them. Now, we can use this metric to measure the agentic capabilities of frontier language models in the long run.
A Simple Yet Necessary Experiment
To answer this question, researchers in The Illusion of Diminishing Returns make a toy (but brilliant) experiment:
Consider you have a Python dictionary, whose keys are fruits and real numbers as values. In each step, you can ask the model to perform a mathematical operation according to the respective values of the fruits, i.e., mapping the keys to their respective values and providing the answer to that operation. This is a traceable experiment to check whether the model makes mistakes and let us conveniently change those mistakes to the real answer (programmatically).
This way, we can modify the wrong outputs given by the model that are added as context, and see what happens when we reduce the "error rate" in the subsequent answers. Suppose we have a context of 100 different steps, from which 40 are incorrect and 60 are correct, indicating a 40% error rate. This experiment modifies the number of wrong steps in the context with right ones, manipulating the error rate and checking the number of errors generated after that for a given horizon.
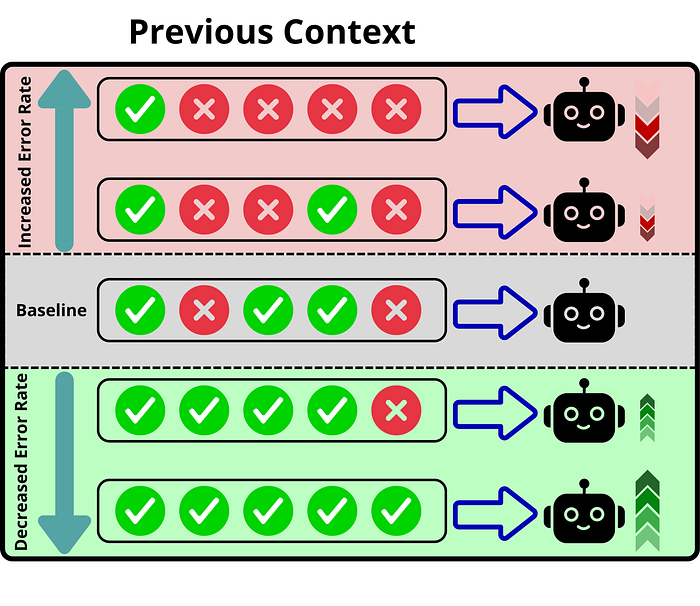
The results indicate that the error rate has a significant impact on the accuracy of subsequent steps. Thus, the model exhibits a self-conditioning effect, being prone to make more mistakes whenever it has made a mistake previously. However, it improves over the baseline accuracy whenever the error rate is reduced below the reference value.
The Special Case of Reasoning Language Models
One key finding is that modern reasoning models, which tend to use reinforcement learning during the supervised fine-tuning step, are less prone to self-conditioning. These models exhibit less degradation when exposed to errors in their prior context.
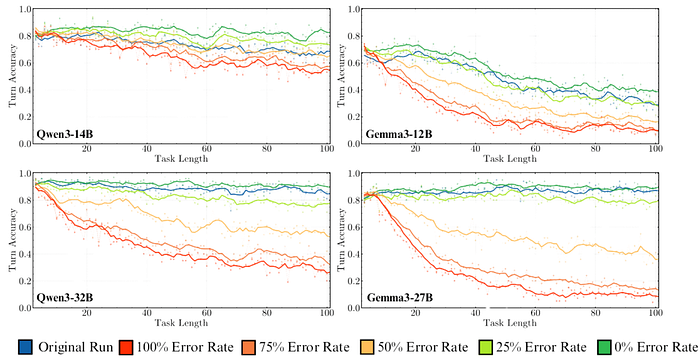
As seen in the image above, when modifying the error rate in Qwen3–14B and Gemma3–12B, even though they start at similar turn accuracy, the long-term outcome is much more catastrophic for the Gemma3 model.
Likely, mistakes and error correction are handled in the data used during Supervised Fine Tuning, as the human alignment step typically involves correcting the language model.
Another possibility is that the reinforcement learning step reduces the next token prediction behaviour that is inherited from the initial pre-training step, thus biasing the model into solving the real problem rather than continuing the context.
One important consideration is that modern reasoning models do not refer back to prior turns in their chain of thought process. Their thinking traces are a fresh way of reasoning that is not constrained by prior context. This suggests that the companies behind those models are already aware of the significant impact of the error rate on the next steps.
This would explain why those models are less prone to self-conditioning; however, further research is needed on these specific models before making a solid assumption. From the results obtained so far with reasoning language models, decoupling execution from planning might be a beneficial improvement for these models, allowing for fine-grained control over the reasoning model and enhancing the debugging capabilities for these Stochastic Parrots.
What happens with larger language Models?
Every language model is affected by the error rate; however, specific trends are found depending on the size of the language model. Researchers found that larger language models are more vulnerable to the error rate, which means:
- Larger language models with a small error tend to suffer less degradation in subsequent steps, thereby maintaining good overall accuracy in the long run.
- Larger language models with a high error rate tend to perform worse in subsequent steps; this effect is particularly noticeable in the short term.
These effects are evident in the image above. When comparing Gemma3 in its 12B and 27B versions, the degradation of the 27B model is more pronounced as the error rate increases, as indicated by the steeper slope.
Considering this, smaller language models with a high error rate in their context will likely perform better than bigger language models with a higher error rate, so even if the size of the language models tends to decrease the amount of errors in their tasks, if somehow the context contains errors, the effect will be more devastating with larger models.

We Failed Back Again Into Moravec's Paradox.
Over the last few years, we have focused on creating a model that performs reasoning processes and breaks down complex tasks into simpler subtasks, as this is the way humans improve their accuracy on complex and long-term objectives.
Moravec's Paradox suggests that what might be easy and consume low resources in humans can be very costly for machines; conversely, tasks that machines perform effortlessly can be very difficult for humans.
However, we overlooked measuring the accuracy of long-term execution independently of task complexity; in other words, we neglected other factors that might impact model performance, as it doesn't make sense from a human perspective. In this sense, there are two key insights determined in the paper:
The longer the context length, the more likely it is that a new error will appear, even on simple tasks. This is one key difference between humans and language models. Suppose someone knows how to perform addition operations, even if I provide a lot of non-sense context before asking him to perform that operation, he will give the correct answer. However, this is not the case for language models. In multi-turn conversations and agentic AI, this will be more dramatic, as the error will be stored as context for subsequent tasks.
Prior errors condition the accuracy of the following steps, diminishing the returns of the language model. Whenever performing several steps in a given task, the language model exhibits self-conditioning; it is prone to provide better answers if its context is entirely correct, and the opposite also occurs: an increase in the number of errors will lead to more errors in the subsequent generation. In the case of humans, it looks like we don't really learn if failure is not present, which is another indication of Moravec's Paradox.
As humans learn how to perform a specific task, we assume that we will perform it correctly every time. This is not the same for language model, as the generation is not deterministic and might be noisy based on the growing context. Thus, execution is a key component when working with Generative Language Models.
Considering also that errors may appear randomly due to the nondeterministic nature of generation, even in deterministic settings, we have a perfect breeding ground for the model to fail dramatically in the long run.
Some Ideas on Future Approaches
This opens up several possibilities for the future, based on the knowledge gained about the horizon length in language models. The experiment carried out in "The Illusion of Diminishing Returns" is both insightful and naïve.
First, separating the planning from the execution is difficult to translate to a real scenario, even if it's convenient for the experiment. Likely, preparing a model only for planning and another one only for execution would be a plausible approach for a real-world use case. But in that situation, we are prone to hallucinations in both the planning and execution, as the model that handles the planning might be doing a long-horizon task too.
Second, if prior errors have a significant impact on subsequent steps, could we autodetect these errors using a judge and then perform an easy task to avoid erroneous context? For instance:
- Echoing the last prior context and repeating the task that was performed incorrectly. This could be an interesting approach, as the echo is just a copy/paste of the previous answer.
- Using a language model to paraphrase the previous correct context. This language model would be performing a simple task with a short context, making it less prone to errors than the actual "main model", which handles all the execution.
Theoretically, this could improve the language model's output in the long run, based on the self-conditioning effect. This could be an effective way to boost the Horizon Length without requiring the most expensive reasoning models, as those are the least prone to long-term errors, according to the research, or maybe we would be failing in the classical problem of dragging the error from one model to another, resulting in a greater diminishing return.
Closing Thoughts
The evidence from The Illusion of Diminishing Returns reminds us of something we often forget: language models are not consistent thinkers; they are probabilistic pattern machines navigating their own noise. The longer the horizon, the more this noise accumulates, until accuracy collapses under the weight of its own errors.
Decoupling planning from execution, measuring horizon length, and probing error self-conditioning are not just academic exercises — they point directly to the fragility of current "reasoning" systems. What appears to be progress in short bursts may quickly deteriorate when viewed across longer contexts.
This is, once again, Moravec's paradox playing out in real time. What is trivial for humans — carrying forward a clean line of reasoning without being derailed by irrelevant noise — is precisely where language models stumble. And what seems impossibly complex for humans — crunching vast statistical patterns — is where they shine.
Until we address this issue, every step forward will carry the hidden tax of diminishing returns.