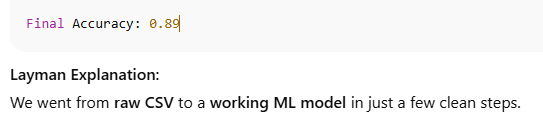
Learn essential functions for ML algorithms, model building & evaluation with Python examples, real datasets, and easy-to-understand outputs. Perfect for students & data scientists.
Why Scikit-learn Matters for Data Scientists
- Loading & preparing data
- Building ML models (classification, regression, clustering, etc.)
- Evaluating models with clear metrics
- Tuning hyperparameters for best performance
1. Data Loading & Preparation

Example:

Output (sample):
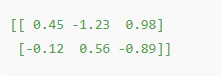
Layman Explanation: We're making sure all features are on the same scale — like converting different currencies to the same unit before comparing them.
2️. Building Machine Learning Models
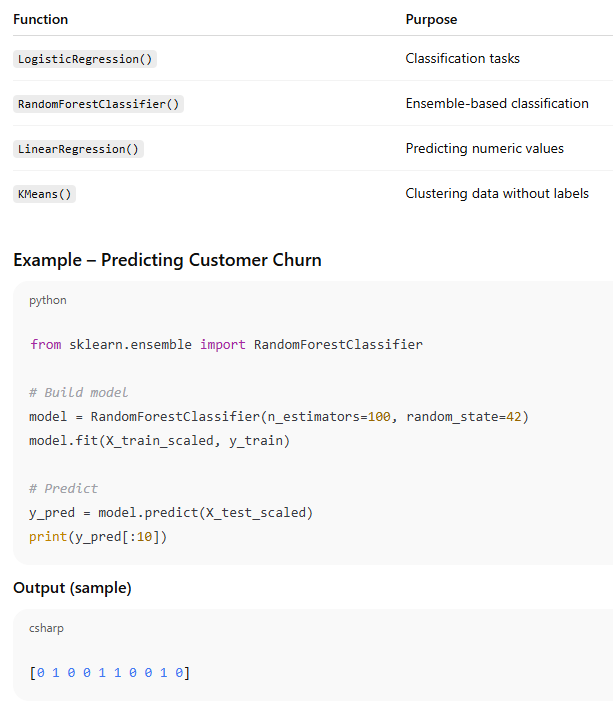
Layman Explanation: The model is labeling customers as "likely to stay" (0) or "likely to leave" (1) based on their past behavior.
3️. Model Evaluation
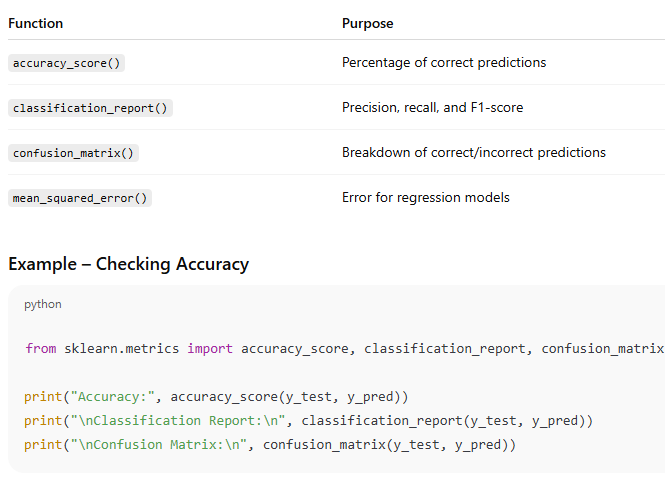
Output (sample)

4️. Hyperparameter Tuning
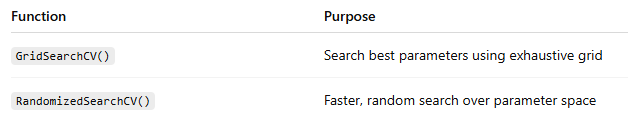
Example — Finding Best Model Settings

Output (sample)

5️. Feature Importance & Interpretation
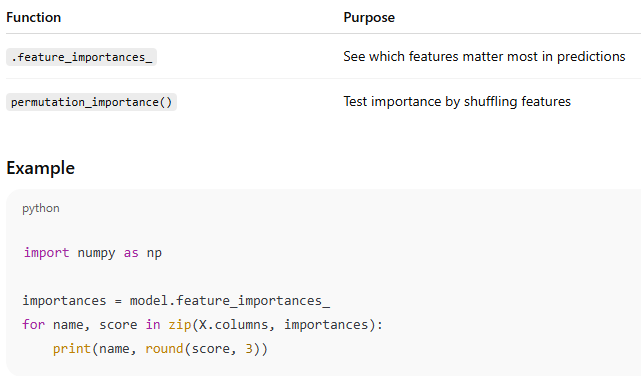
Output (sample)

Advanced & expert-level Scikit-learn functions so it's valuable for both beginners and experienced data scientists. I'll cover Pipelines, ColumnTransformer, Cross-Validation, and Model Persistence.
6️. Pipelines — Chaining Steps Together
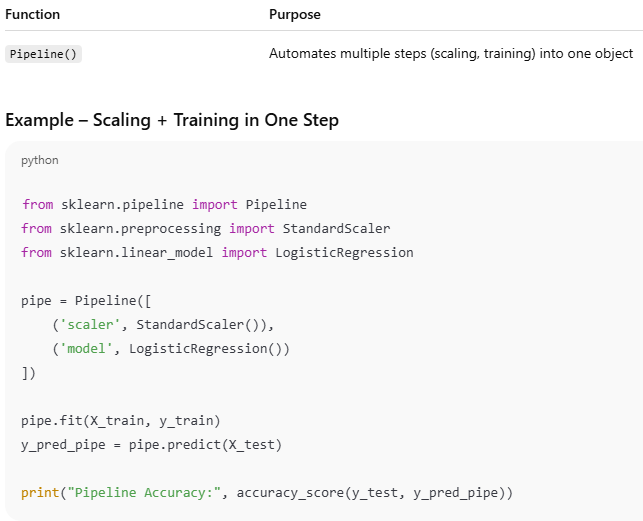
Output (sample)

7️. ColumnTransformer — Handling Mixed Data Types


Output (sample)

8️. Cross-Validation — Reliable Model Testing
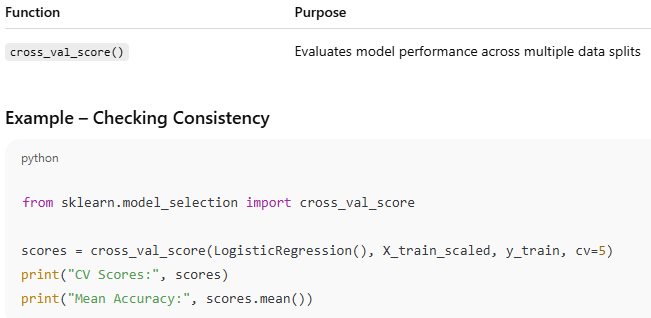
Output (sample)

9️. Model Persistence — Saving & Loading Models

Output (sample)

10. Putting It All Together — End-to-End Workflow
Here's what a real business-ready Scikit-learn workflow looks like:

Output (sample)