

This article is a review of the paper by Google titled, Class-Balanced Loss Based on Effective Number of Samples that was accepted at CVPRཏ.
TL;DR — It proposes a class-wise re-weighting scheme for most frequently used losses (softmax-cross-entropy, focal loss, etc.) giving a quick boost of accuracy, especially when working with data that is highly class imbalanced.
Link to implementation of this paper(using PyTorch) — GitHub
Effective number of samples
While handling a long-tailed dataset (one that has most of the samples belonging to very few of the classes and many other classes have very less support), deciding how to weight the loss for different classes can be tricky. Often, the weighting is set to the inverse of class support or inverse of the square root of class support.
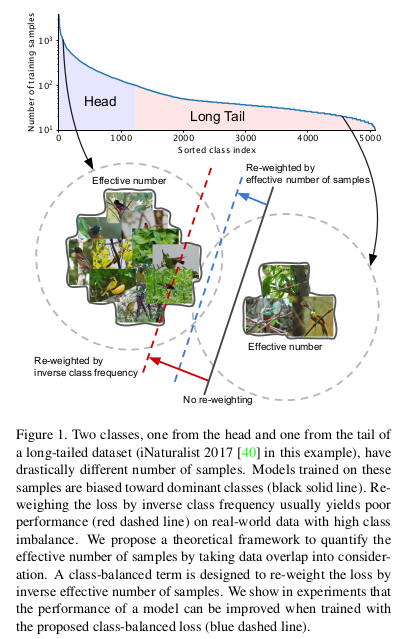
However, as the above figure shows, this overshoots because as the number of samples increases, the additional benefit of a new data point diminishes. There is a high chance that a newly added sample is a near-duplicate of existing samples, primarily when heavy data-augmentation(such as re-scaling, random cropping, flipping, etc.) is used while training neural networks. Re-weighting by Effective number of samples gives a better result.
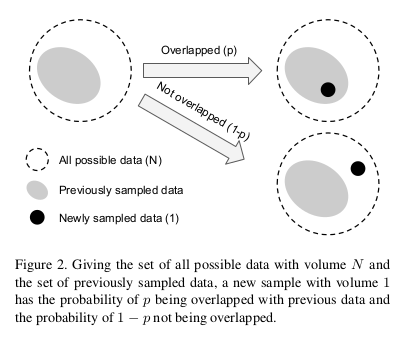
Effective number of samples can be imagined as the actual volume that will be covered by n samples where the total volume N is represented by total samples.
Formally, we write it as:
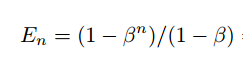
Here, we make an assumption that a new sample will interact with the volume of previously sampled data in two ways only: either wholly covered or wholly outside(shown in the figure above). With this assumption, the above expression can be easily proved using induction(refer to the paper for proof).
We can also write it as below:
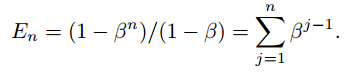
This means jth sample contributes Beta^(j-1) to the Effective number of samples.
Another implication from the above equation is En = 1 if Beta = 0. Also, En → n as Beta → 1. The latter can be easily proved using L'Hopital's rule. This means when N is huge, the effective number of samples is the same as the number of samples n. In such a case, the number of unique prototypes N is large, and every sample is unique. Whereas, if N=1, this means all data can be represented by one prototype.
Class Balanced Loss
Without extra information, we cannot set separate values of Beta for every class, therefore, using whole data, we will set it to a particular value (customarily set as one of 0.9, 0.99, 0.999, 0.9999).
Thus, the class balanced loss can be written as:
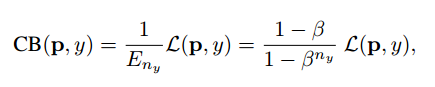
Here, L(p,y) can be any loss function.
Class Balanced Focal Loss
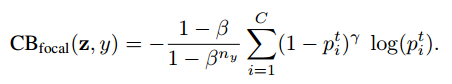
The original version of focal loss has an alpha-balanced variant. Instead of that, we will re-weight it using the effective number of samples for every class.
Similarly, such a re-weighting term can be applied to other famous losses as well (sigmoid-cross-entropy, softmax-cross-entropy etc.)
Implementation
Before coming to implementation, a point to note while training with sigmoid-based losses — initialise the bias of the last layer with b = -log(C-1) where C is the number of classes instead of 0. This is because setting b=0 induces a huge loss at the beginning of the training as the output probability for each class is close to 0.5. So, instead, we can assume the class prior is 1/C and set value of b accordingly.
Weights calculation for the classes

Above lines of code is a simple implementation of getting weights and normalising them.

Here, we get the one hot values for the weights so that they can be multiplied with the Loss value separately for every class.
Experiments
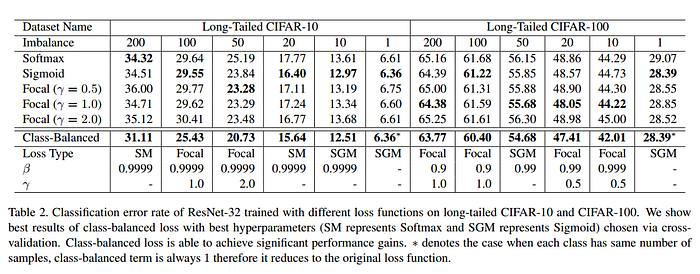
Class balancing provides significant gains, especially when the dataset is highly imbalanced (Imbalance = 200, 100).
Conclusion
Using the concept of Effective Number of Samples, we can tackle the problem of data overlap. Since we don't make any assumptions about the dataset itself, therefore the re-weighting terms are generally applicable across several datasets and several loss functions. Thus, the problem of class imbalance can be tackled with a more proper structure, and this is important since most of the real-world datasets suffer from a tremendous amount of data imbalance.
References
[1] Class-Balanced Loss Based on Effective Number of Samples: https://arxiv.org/abs/1901.05555