


Before answering the above question let me tell you my experience when I was learning about the evaluation of learning algorithms in classification problems.
My Experience
Currently, I am learning ML from the Andrew ng Coursera course and I just finished my week 6 assignment which means its more than a month WOW.
I am enjoying it. So let's get back to the topic.
In week 6 when I first watched the video of different evaluation metrics for classification problems. I was literally not able to understand the concept of precision and recall. Then I started searching over the internet on different platforms and I found a very easy explanation of this topic. You can find useful links under the reference section. So when I understood the concept of precision and recall I thought let's publish tutorial blog :)
How did I understand precision vs recall?
We know that by accuracy metric we can evaluate our learning algorithm for classification problem So I asked myself the below question.
Why do we need to move from accuracy to precision/recall?
Because of the class-imbalanced dataset and we cannot really tell that our learning algorithm is doing well on a class-imbalanced dataset by just looking at accuracy. The surprising part is that you can get accuracy in 90's % on your test set but it won't be a good metric to decide about the wellness of your learning algorithm.
So let's learn more about the above paragraph to get a better understanding.
What is a Class-imbalanced dataset?
The class-imbalanced dataset is when the quantity of one class is very rare in the dataset means that the quantity of one class is greater than the other class.
Examples in imbalanced classification problem :
1) Disease detection task
The imbalanced classification problem occurs in disease detection when the rate of the disease in the public is very low.
2) Terrorist detection task
Another imbalanced classification problem occurs in terrorist detection tasks when we have two classes we need to identify terrorists and not terrorists with one category representing the overwhelming majority of the data points.
Now let's understand with the help of a real-world example
Why 90's % accuracy cannot decide the wellness of your learning algorithm?
Consider disease detection tasks where we want to detect cancerous tumors so doctors can treat it before a critical situation.
In total, we have 100 tumors examples in our dataset classified according to there type benign and malignant. Domain knowledge says that malignant tumors are cancerous so we will represent tumors as
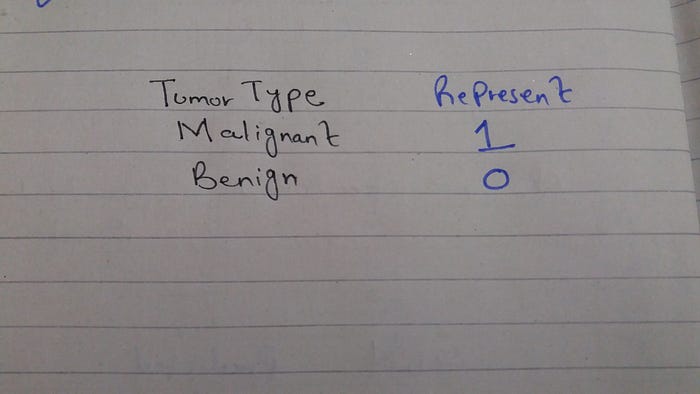
Note
Our main task is to detect malignant tumors that are cancerous.
Just to give some sense of dataset it will look like below. Here we have only two features but there can be many

Now in our dataset out of 100 examples 91% are benign and 9% are malignant tumors.
Assuming you have trained your classifier to let's say using logistic regression and you found the following correct results:

So our model correctly predicted 90% benign tumors and just 1% malignant which was our main objective. This means that our model is doing poorly in predicting malignant tumors.
Let's do some analysis by looking below the self-explanatory picture
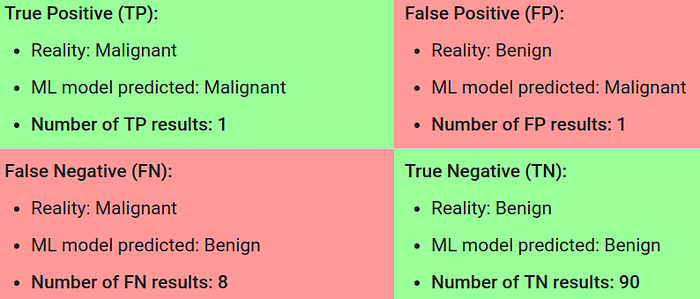
First, calculate accuracy on these results:

We got 91% accuracy even though our model is poorly predicting malignant tumors. So that's why accuracy is not a good metric for evaluating an imbalanced classification problem. So how can we solve this problem ? by simply choosing the correct metric.
Choosing correct metric precision and recall :
Here I want you to concentrate on the following words so that we can better understand the difference between these two metrics.
In our problem malignant is a positive class (1) and benign is a negative class(0).
What is Precision?
" Whenever your model predicts positive class, it is the correct percentage of the time "
If you understood the above statement you are good to go and if you are like me then let's calculate precision and understand what it means.

Precision focuses on positive class (malignant) and we got 50% of precision. So just replace the above statement with malignant and 50% then you will get a better sense of its meaning.
" Whenever your model predicts malignant tumors, it is correct 50% of the time "
let's verify 50% correctness.
How many malignant tumors did our model predicted?

And out of 2 our model just got 1 correct prediction Hence verified 50%
What is a Recall ?
Recall is about
" What percentage of positive class prediction from your model is correct from the actual positive class in the dataset ? "
Calculate recall:
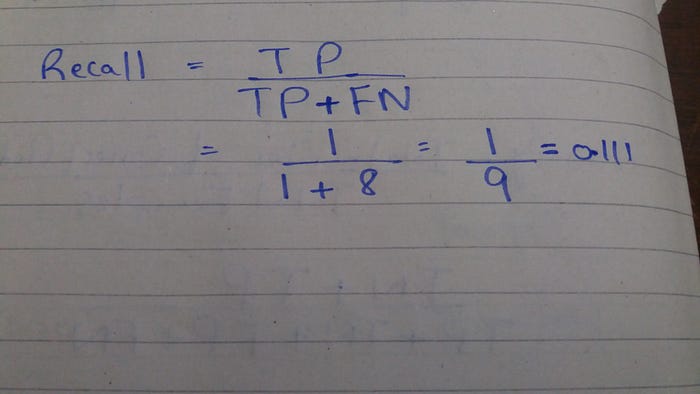
So recall is 11% which means
" 11% percentage of malignant tumors prediction from model is correct from actual malignant tumors in the dataset "
I hope you got the difference between these two metrics and enjoyed reading this tutorial.
For more details on precision/recall refer to links under references.
Thank you very much :)
Learn, create, share and repeat
References:
- https://developers.google.com/machine-learning/crash-course/classification/accuracy
- https://developers.google.com/machine-learning/crash-course/classification/precision-and-recall
- https://towardsdatascience.com/beyond-accuracy-precision-and-recall-3da06bea9f6c
Contact
Gmail: jalalmansoori19@gmail.com
Github: https://github.com/jalalmansoori19
Twitter: https://twitter.com/JalalMansoori19