
Introduction
In the rapidly evolving landscape of machine learning, the journey from raw data to a deployed, high-performing model is fraught with challenges. One of the most significant hurdles often lies in managing the data that feeds these models -specifically, the 'features' that represent the underlying patterns and insights. This is where the concept of a Feature Store emerges as a critical, yet frequently underestimated, component in the machine learning lifecycle.
A feature store acts as a centralized repository and management system for machine learning features. It's designed to ensure consistency, reusability, and discoverability of features across various stages of ML development, from initial experimentation and model training to real-time inference in production. Without a robust feature store, organizations often grapple with issues like feature drift (where features behave differently in production than during training), inconsistent data definitions, and painfully slow deployment cycles.
While the market has seen the rise of powerful commercial solutions such as Tecton, AWS SageMaker Feature Store, and Google's Vertex AI Feature Store, the open-source community has been diligently working to provide equally compelling, flexible, and cost-effective alternatives. These open-source projects are rapidly maturing, offering sophisticated capabilities that empower data scientists and ML engineers to streamline their MLOps practices.
This blog post will take a deep dive into the most prominent open-source projects in the feature store domain. We'll explore their historical context, delve into their architectural nuances, provide practical usage examples, and conduct a comparative analysis to help you understand how they stack up against each other. Whether you're just starting your ML journey or looking to optimize your existing MLOps infrastructure, understanding the open-source feature store landscape is crucial for building scalable and reliable machine learning systems.
A Brief History and Context: The Rise of Feature Stores
The genesis of feature stores can be traced back to the early days of large-scale machine learning deployments, particularly within tech giants like Uber, Google, and Facebook. As these companies scaled their ML initiatives, they encountered recurring pain points that hindered efficiency and model performance. These challenges included:
- Feature Drift and Skew: The phenomenon where the distribution of feature values changes between training and serving environments, leading to degraded model performance.
- Inconsistent Data Definitions: Different teams or even individuals within the same team often computed the same features in slightly different ways, leading to discrepancies and errors.
- Delayed Deployments: The manual, ad-hoc process of preparing features for both training and inference was time-consuming and error-prone, slowing down the pace of innovation.
- Lack of Feature Reusability: Features computed for one model often couldn't be easily reused for another, leading to redundant effort and wasted computational resources.
Feature stores emerged as a direct response to these challenges, acting as a critical layer to standardize feature engineering pipelines and ensure consistency between training and inference. By providing a centralized, versioned, and accessible repository for features, they aimed to accelerate the ML development cycle and improve the reliability of deployed models.
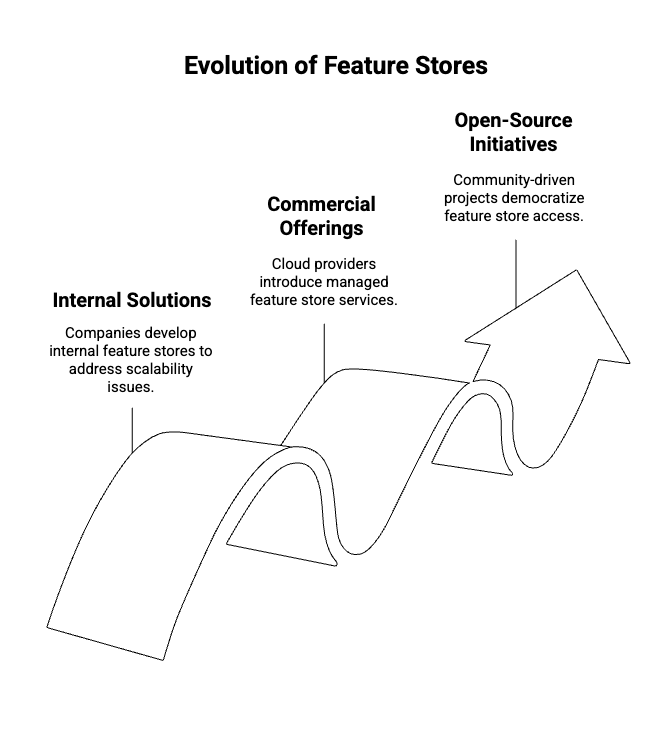
Early pioneers in this space were primarily internal solutions developed by companies facing these problems at scale. Notable examples include Uber's Michelangelo Platform, which eventually led to the creation of Tecton, a leading commercial feature store. Similarly, cloud providers recognized the growing need and introduced their own managed offerings, such as AWS SageMaker Feature Store and Google Cloud's Vertex AI Feature Store.
The success of these internal and commercial solutions quickly highlighted the universal need for feature management. This spurred an open-source wave, driven by the MLOps community's demand for flexible, pluggable, and affordable solutions. This led to the birth of projects like Feast (initially by Gojek and later supported by Tecton) and Hopsworks (developed by Logical Clocks), alongside the emergence of 'DIY' stacks leveraging existing data infrastructure components like Airflow, Delta Lake, and Redis. These open-source initiatives have democratized access to feature store capabilities, making them accessible to a wider range of organizations and teams.
So … What is a Feature Store?
At its core, a Feature Store is a data management layer specifically designed for machine learning. It serves as a centralized repository for storing, managing, and serving features -the input variables or attributes that machine learning models use to make predictions. Think of it as a specialized database and serving system for the data that fuels your AI.

Why Do We Need a Feature Store?
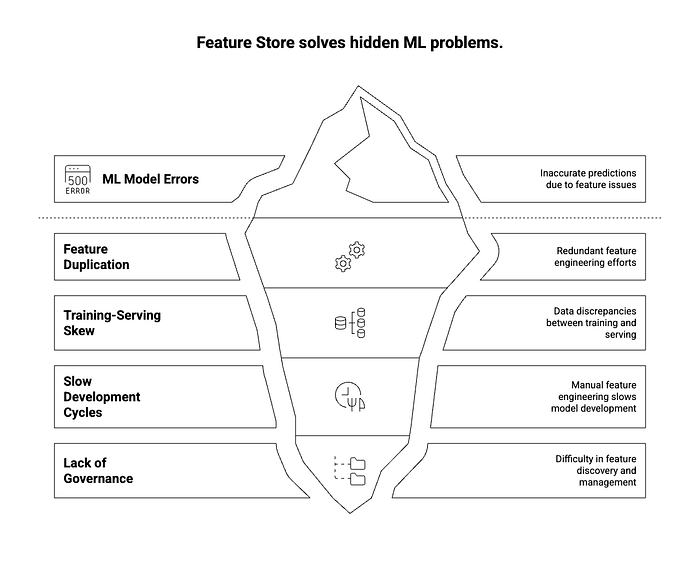
Before the advent of feature stores, data scientists and ML engineers often faced several challenges:
- Feature Duplication and Inconsistency: Different teams or even individuals would often re-engineer the same features, leading to redundant effort and, more critically, inconsistencies in how features were calculated. A 'customer lifetime value' feature might be calculated differently for training a churn model versus a recommendation model, leading to discrepancies and errors in predictions.
- Training-Serving Skew: This is a critical problem where the data used to train a model differs from the data used to serve predictions in production. This can happen due to different feature engineering logic, data sources, or processing pipelines between the offline (training) and online (serving) environments. Feature stores aim to eliminate this by ensuring the same feature definitions and pipelines are used for both.
- Slow Development Cycles: Without a centralized system, finding, understanding, and reusing existing features was a manual and time-consuming process. Each new model often required starting feature engineering from scratch, significantly slowing down the pace of ML development.
- Lack of Discoverability and Governance: It was difficult to know what features already existed, who owned them, how they were defined, or how they performed. This lack of governance led to a chaotic and inefficient ML ecosystem.
Key Functions of a Feature Store
A robust feature store typically provides the following core functionalities:
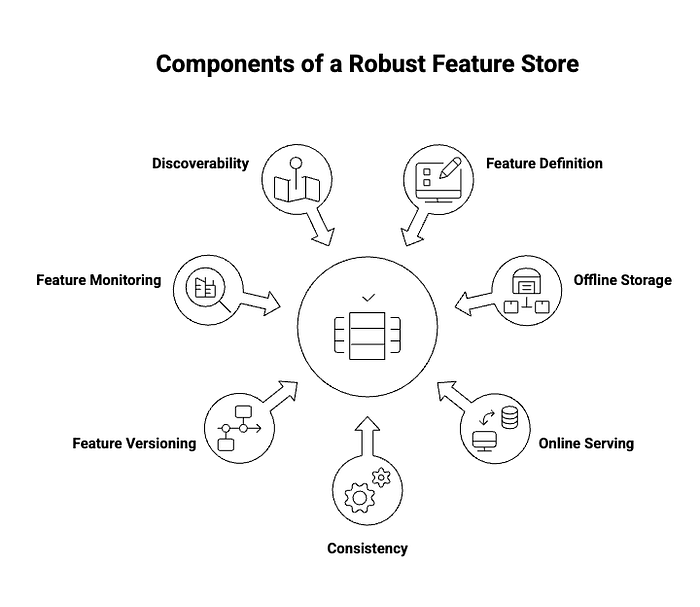
- Feature Definition and Registration: Allows data scientists to define features programmatically, often using a declarative language or SDK. These definitions are then registered in a central catalog, making them discoverable.
- Offline Storage: Stores large volumes of historical feature data, optimized for batch processing and model training. This data is typically stored in data warehouses (e.g., BigQuery, Snowflake) or data lakes (e.g., S3, HDFS).
- Online Serving: Provides low-latency access to the latest feature values for real-time model inference. This usually involves fast key-value stores (e.g., Redis, DynamoDB).
- Consistency (Online/Offline Parity): Ensures that the feature values used for training a model are identical to those used when the model makes predictions in production. This is achieved by using the same feature engineering logic and data sources for both environments.
- Feature Versioning: Tracks changes to feature definitions over time, allowing for reproducibility of experiments and models. This is crucial for debugging and auditing.
- Feature Monitoring: Enables monitoring of feature quality, freshness, and distribution to detect issues like data drift or anomalies that could impact model performance.
- Feature Discoverability and Reuse: Provides a central catalog or registry where data scientists can easily find, understand, and reuse existing features, fostering collaboration and accelerating development.
In essence, a feature store acts as a crucial bridge between data engineering and machine learning, streamlining the process of getting data ready for models and ensuring that those models perform reliably in production. It transforms raw data into a reusable, consistent, and versioned asset for machine learning applications.
Deep Dive into Each Tool
1. Feast (Feature Store)
Website: https://feast.dev
Feast, an acronym for Feature Store, stands out as one of the most widely adopted open-source feature stores. Its origins trace back to Gojek, the Indonesian tech giant, which developed it to manage features for its vast array of machine learning models. Later, it gained significant support from Tecton, a commercial feature store company, and is now a proud project under the Linux Foundation, ensuring its continued development and community-driven evolution.
Feast's primary purpose is to simplify feature retrieval and ensure consistency between offline training and online inference environments.
Architecture
Feast's architecture is designed for flexibility and scalability, allowing it to integrate seamlessly with various data ecosystems. Its core components include:
- Feature Registry: This acts as the central catalog for all defined features. It stores metadata about features, including their definitions, data sources, and transformations. Data scientists can discover and reuse features through this registry.
- Offline Store: This component is responsible for storing historical feature data, typically used for model training and backfilling. Feast supports a wide range of offline stores, including data warehouses like Google BigQuery, Snowflake, and even local dataframes, offering flexibility in data storage choices.
- Online Store: Designed for low-latency feature retrieval during real-time model inference, the online store holds the most recent feature values. Popular choices for online stores include Redis and DynamoDB, which can serve features with millisecond-level latency.
- Serving Layer: This layer facilitates the retrieval of features by entity (e.g., user_id, product_id). It intelligently fetches features from either the offline or online store based on the request, ensuring that models always receive the correct and most up-to-date feature values.
Usage Example
Feast emphasizes a code-centric approach to feature definition and management. Here's a simplified workflow:
- Initialize a Feature Repository: Use the CLI to scaffold your project:
feast init my_feature_repo
cd my_feature_repoThis creates a repo structure with example feature definitions, a registry config, and provider-specific settings (e.g., GCP, AWS, or local).
- Define Features: Inside feature_repo/example.py (or a similar file), you define your feature views, sources, and entities using Feast's Python SDK. For instance, you might define a user_transactions_feature_view that pulls data from a BigQuery table. you define:
- Entity (e.g., user ID)
- Data Source (e.g., BigQuery, file, or Snowflake)
- Feature View (how to compute and serve features)
Example (BigQuery source):
from feast import Entity, FeatureView, Field, FileSource
from feast.types import Float32, Int64
# Define the entity
user = Entity(name="user_id", join_keys=["user_id"])
# Define the data source
user_transactions_source = FileSource(
path="data/user_transactions.parquet",
timestamp_field="event_timestamp"
)
# Define the feature view
user_transactions_fv = FeatureView(
name="user_transactions",
entities=["user_id"],
ttl=timedelta(days=1),
schema=[
Field(name="total_spent", dtype=Float32),
Field(name="transaction_count", dtype=Int64),
],
source=user_transactions_source
)You can also pull from online tables like BigQuery or Redshift, depending on your provider.
- Apply Changes: This step updates the feature registry with your definitions
feast applyFeast generates or updates the feature registry.yaml and sets up necessary metadata for both online and offline stores.
- Materialize Features: Load historical data into the online store so it's available for real-time inference
# Materialize everything up to now
feast materialize-incremental $(date +%Y-%m-%dT%H:%M:%S)This step is only necessary for batch or backfilled features that need to be served in real time.
- Retrieve Features for Training/Inference:
a) Training Dataset (Offline Retrieval)
Use the SDK to create a training set by joining your entity list with historical features:
training_df = store.get_historical_features(
entity_df=pd.DataFrame.from_dict({
"user_id": [1, 2, 3],
"event_timestamp": [datetime.now()] * 3
}),
features=[
"user_transactions:total_spent",
"user_transactions:transaction_count"
]
).to_df()b) Real-Time Inference (Online Retrieval)
online_features = store.get_online_features(
features=[
"user_transactions:total_spent",
"user_transactions:transaction_count"
],
entity_rows=[{"user_id": 1}]
).to_dict()This retrieves the latest feature values from the online store (e.g., Redis).
Real-World Use Cases
Feast has been successfully adopted in various industries for a multitude of machine learning applications, including:
- Churn Prediction: Providing up-to-date customer behavior features (e.g., recent activity, spending patterns) to predict customer churn.
- Fraud Detection: Serving real-time transaction features (e.g., transaction velocity, unusual spending) to identify fraudulent activities.
- Product Recommendations: Delivering personalized user interaction features (e.g., past purchases, browsing history) to recommend relevant products.
Pros
- Simple to Use: Feast offers a clean and intuitive API, making it relatively easy for data scientists to define and manage features.
- Cloud-Agnostic: It supports a wide range of cloud providers and data technologies, preventing vendor lock-in.
- Active Community: Being a Linux Foundation project, Feast benefits from a vibrant and active community, ensuring continuous development, support, and a rich ecosystem of integrations.
- Online/Offline Parity: Its core design principle ensures that the features used for training are identical to those used for inference, mitigating feature skew.
Cons
- Lacks Native UI: Unlike some other solutions, Feast does not come with a built-in graphical user interface for feature exploration or management, relying primarily on its CLI and SDK.
- Limited Governance Features: Compared to more comprehensive platforms like Hopsworks, Feast offers fewer out-of-the-box governance features such as detailed lineage tracking or advanced access control mechanisms. While these can be built on top of Feast, they are not natively integrated.
2. Hopsworks
Website: https://www.hopsworks.ai
Hopsworks, developed by Logical Clocks (a spin-out from KTH Royal Institute of Technology in Sweden), is more than just a feature store; it's a comprehensive open-source MLOps platform with a strong emphasis on data-intensive machine learning. While it offers an open-source core, Logical Clocks also provides a managed cloud offering, catering to both self-hosted and managed service preferences. Hopsworks distinguishes itself by providing a rich set of MLOps capabilities, including an integrated UI, versioning, and lineage tracking, making it a powerful choice for organizations seeking a more holistic solution.
Architecture
Hopsworks is built on a robust distributed architecture, leveraging technologies like HopsFS (a distributed file system), Apache Kafka for real-time data streaming, and Apache Spark for large-scale data processing. Its integrated nature means it provides a unified environment for various MLOps tasks. Key architectural components and features include:
- HopsFS: A distributed file system optimized for machine learning workloads, providing efficient storage and access to feature data.
- Integrated UI and APIs: Hopsworks provides a user-friendly web interface and comprehensive APIs for managing feature groups, exploring features, and monitoring data. This UI significantly enhances discoverability and collaboration among data scientists and ML engineers.
- Versioning and Lineage: A core strength of Hopsworks is its robust support for feature versioning and lineage tracking. This allows users to track how features are created, transformed, and used across different models, ensuring reproducibility and auditability.
- Online/Offline Sync: Similar to Feast, Hopsworks maintains both online and offline stores, ensuring consistency between training and serving. It handles the synchronization of feature data between these stores.
- Security and Governance: Hopsworks offers enterprise-grade security features, including role-based access control and data encryption, which are crucial for regulated industries.
Usage Example
Hopsworks can be interacted with via Python, Spark, or its intuitive UI. Here's a Python example demonstrating feature group definition and insertion:
from hopsworks.feature_store import FeatureStore
# Connect to the Hopsworks Feature Store
fs = FeatureStore()
# Define or get a feature group
fg = fs.get_or_create_feature_group(
name="transactions",
version=1,
primary_key=["customer_id", "transaction_id"], # Added transaction_id for better primary key
description="Bank transactions data, including amount and type.",
online_enabled=True # Enable for online serving
)
# Create a sample DataFrame (e.g., from a data source)
import pandas as pd
data = {
"customer_id": [1, 2, 3],
"transaction_id": [101, 102, 103],
"amount": [100.50, 25.75, 500.00],
"transaction_type": ["debit", "credit", "debit"]
}
df = pd.DataFrame(data)
# Insert data into the feature group
fg.insert(df)
# You can then retrieve features for training or inference
# For example, to get historical features for training:
# query = fg.select_all()
# training_data = query.read()
# For online inference, you would use the online feature store client
# online_features = fs.get_online_feature_store().get_single_features(
# feature_group_name="transactions",
# primary_keys={"customer_id": 1, "transaction_id": 101}
# )Real-World Use Cases
Hopsworks has found significant adoption in various enterprise environments, particularly where robust MLOps capabilities and strong data governance are paramount:
- Telecom Churn Prediction (Ericsson): Used to manage and serve features for predicting customer churn in telecommunications, enabling proactive customer retention strategies.
- Banking Fraud Detection: Employed in financial institutions to provide real-time features for identifying fraudulent transactions, leveraging its low-latency serving capabilities.
- Anomaly Detection in IoT: Applied in industrial settings for detecting anomalies in IoT sensor data, ensuring the reliability and safety of connected devices.
Pros
- Full MLOps Platform: Beyond just a feature store, Hopsworks provides a comprehensive suite of MLOps tools, including experiment tracking, model serving, and data validation.
- Rich UI, Lineage, and Versioning: The integrated user interface, coupled with strong support for feature lineage and versioning, significantly improves discoverability, collaboration, and reproducibility.
- Strong Spark Support: Deep integration with Apache Spark makes it an excellent choice for organizations with existing Spark-based data pipelines and large-scale data processing needs.
- Enterprise-Grade Features: Offers robust security, governance, and multi-tenancy capabilities, making it suitable for large enterprises.
Cons
- Heavier Setup: Due to its comprehensive nature and reliance on distributed systems like Spark and Kafka, setting up and managing Hopsworks can be more resource-intensive and complex than a lighter-weight solution like Feast.
- Might Be Overkill for Small Teams: For small teams or individual data scientists with simpler needs, the full suite of Hopsworks features and its associated operational overhead might be more than necessary.
3. Airflow + Delta Lake + Redis (DIY Feature Store)
A DIY feature store typically involves orchestrating various components to manage the feature lifecycle:
- Raw Data Ingestion: Data is ingested from various sources (databases, data lakes, streaming platforms).
- Feature Engineering with Airflow: Apache Airflow serves as the orchestration engine for defining, scheduling, and monitoring feature engineering pipelines. These pipelines transform raw data into curated features.
- Offline Storage with Delta Lake/Parquet: Processed features are stored in a data lake format like Delta Lake or Parquet. Delta Lake, in particular, offers ACID transactions, schema enforcement, and time travel capabilities, making it suitable for reliable offline feature storage.
- Custom Feature Registry: Unlike dedicated feature stores, a DIY setup often requires building a custom metadata store or registry to track feature definitions, versions, and locations. This could be a simple database, a data catalog tool, or even a set of well-organized files.
- Online Serving with Redis/PostgreSQL: For low-latency online inference, features are materialized into a fast key-value store like Redis or a relational database like PostgreSQL, depending on the latency requirements and data volume.
The typical flow would be:
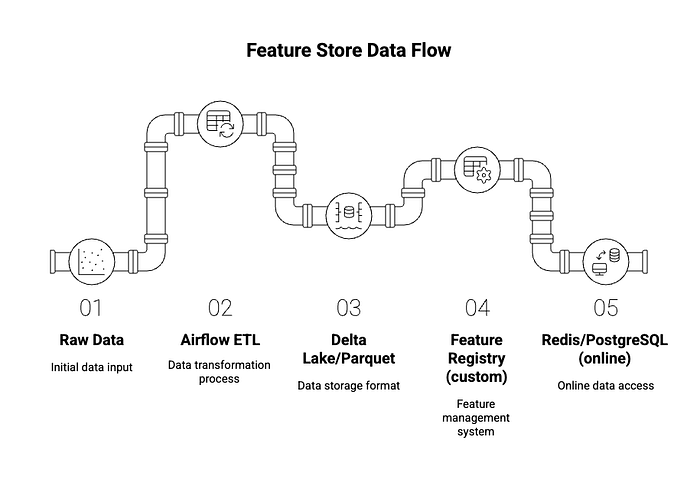
Usage Scenarios
A DIY approach is particularly well-suited for:
- Custom Workloads: When off-the-shelf solutions don't perfectly fit specific, highly customized feature engineering or serving requirements.
- Educational Use: For learning and understanding the underlying mechanics of a feature store by building one from scratch.
- Research Prototypes: Rapidly prototyping new ML systems where flexibility and quick iteration are more important than immediate production readiness.
- Organizations with Existing Infrastructure: Teams that have already heavily invested in and are proficient with tools like Airflow, Spark, and data lake technologies.
Pros
- Fully Customizable: Provides the ultimate flexibility to design and implement a feature store that precisely meets an organization's unique needs and integrates perfectly with existing systems.
- No Vendor Lock-in: By using generic open-source components, teams avoid being tied to a specific vendor's ecosystem or proprietary technologies.
- Easy to Integrate with Existing Infra: Leverages existing data infrastructure and expertise, potentially reducing the learning curve and initial setup costs if the team is already familiar with the chosen components.
- Cost-Effective: Can be more cost-effective in the long run, especially for organizations with significant on-premise infrastructure or those looking to minimize cloud vendor expenses.
Cons
- No Out-of-the-Box Governance: Lacks built-in features for governance, lineage, versioning, and access control, which need to be custom-built and maintained.
- Requires More Engineering Effort: Building and maintaining a DIY feature store demands significant engineering resources, including development, testing, deployment, and ongoing operational support. This can be a substantial overhead compared to using a dedicated solution.
- Higher Operational Complexity: Managing multiple disparate components (Airflow, Delta Lake, Redis, custom registry) can lead to increased operational complexity and potential points of failure.
Comparative Overview
To provide a clearer picture, let's compare the discussed open-source feature stores with each other and briefly with some prominent commercial offerings. This table highlights key aspects such as their type, online/offline store capabilities, UI availability, versioning, governance, and learning curve.
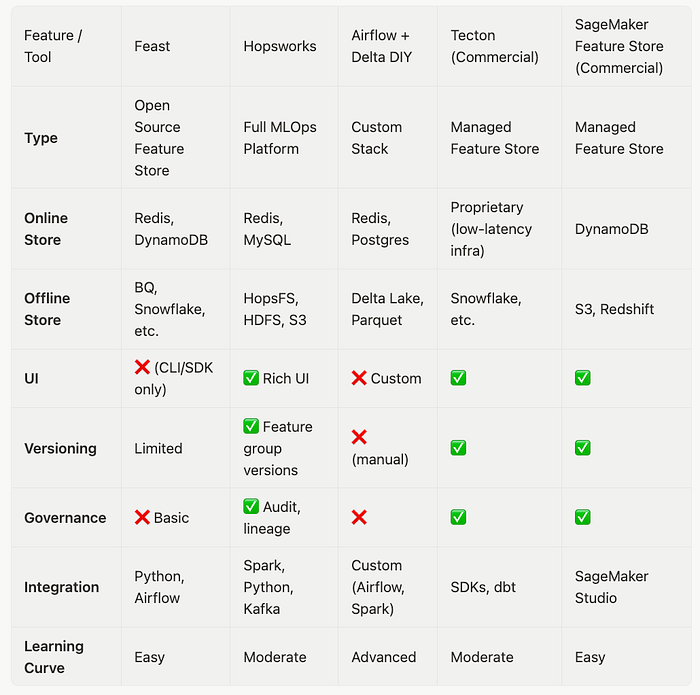
Recommendation: Where Should You Start?
Choosing the right feature store depends heavily on your team's size, existing infrastructure, technical expertise, and specific requirements. Here's a guide to help you navigate the decision:

Challenges to Expect
Regardless of the feature store solution you choose, be prepared to address certain challenges to ensure its successful implementation and long-term viability:
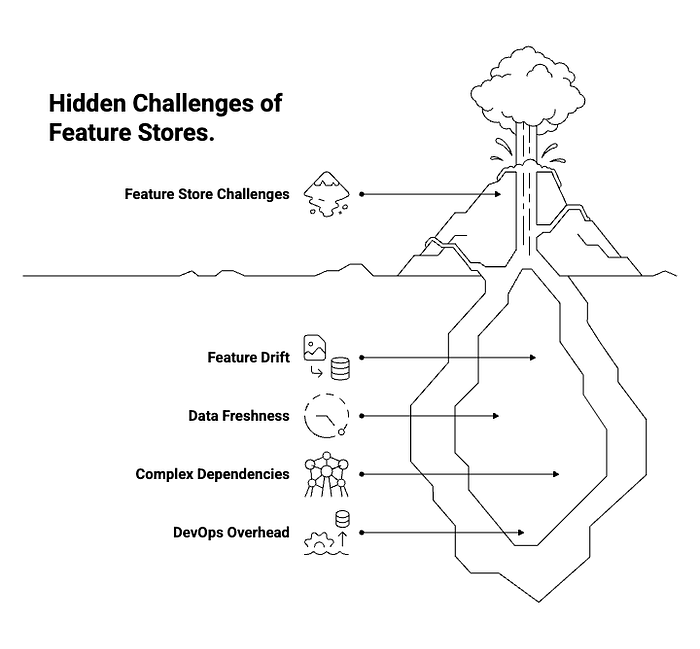
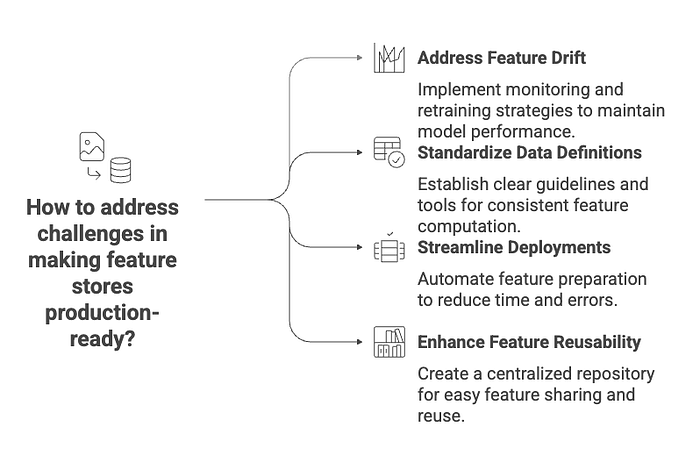
- Feature Drift: While feature stores help ensure consistency between training and serving, they don't magically solve feature drift. It remains your responsibility to monitor upstream data sources and feature distributions to detect and mitigate drift. Tools like Great Expectations can be integrated to help with data quality monitoring.
- Data Freshness: For batch-oriented feature stores like Feast, ensuring data freshness in the online store requires regular materialization. This means setting up robust and timely data pipelines to update feature values.
- Complex Dependencies: Comprehensive platforms like Hopsworks, while powerful, can introduce a steeper learning curve and require expertise in underlying technologies like Spark and Kafka. Ensure your team has the necessary skills or is willing to invest in training.
- DevOps Overhead: Even with open-source solutions, deploying and managing a feature store in production requires significant DevOps expertise. This includes managing infrastructure (e.g., Kubernetes clusters), configuring databases (e.g., Redis), and setting up monitoring and alerting systems.
This applies to both Feast and DIY setups, which require proper infrastructure knowledge.
How to Make Your Feature Store Production-Ready
Building a feature store is only the first step; making it production-ready involves integrating it seamlessly into your MLOps workflow and ensuring its reliability and performance. Here are key considerations:
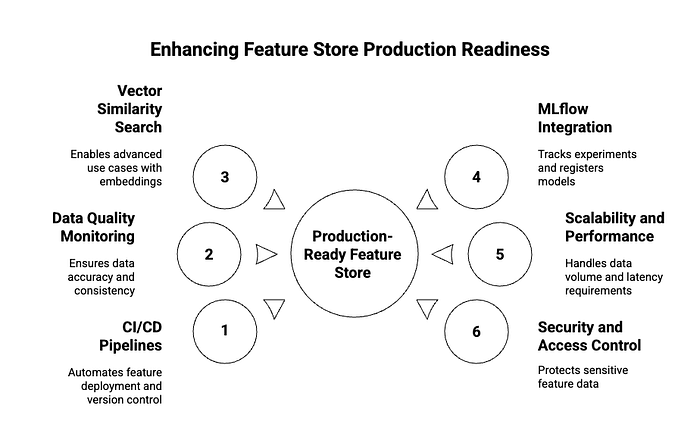
- Automate with CI/CD Pipelines: Integrate your feature definition and deployment processes into your Continuous Integration/Continuous Delivery (CI/CD) pipelines. This enables GitOps-style workflows for features, where changes to feature definitions are version-controlled, reviewed, and automatically deployed. Feast, for example, supports this approach, allowing teams to manage feature definitions alongside their code.
- Monitor Data Quality: Implement robust data quality monitoring for your features. This involves tracking data freshness, completeness, validity, and consistency. Tools like Great Expectations or Deequ can be integrated with your feature pipelines to automatically validate data quality and alert you to anomalies before they impact models. This is crucial for preventing silent model degradation due to data issues.
- Leverage Vector Similarity for Advanced Use Cases: For applications involving embeddings (e.g., from natural language processing or computer vision models), integrate vector similarity search. Combining a feature store (to manage and serve embeddings) with a vector database or library like FAISS (Facebook AI Similarity Search) allows for efficient nearest-neighbor searches, enabling use cases like semantic search, recommendation systems, and anomaly detection based on feature similarity.
- Combine with MLflow for Experiment Tracking and Model Registration: Integrate your feature store with an MLOps platform like MLflow. This allows you to track which features were used for which model experiments, register models with their associated feature schemas, and ensure that the correct features are used when deploying models to production. This tight integration enhances reproducibility and traceability across the entire ML lifecycle.
- Scalability and Performance: Design your feature store infrastructure for scalability. This includes choosing appropriate online and offline stores that can handle your data volume and serving latency requirements. For high-throughput, low-latency serving, consider in-memory databases or specialized key-value stores. For large-scale batch processing, distributed data warehouses or data lakes are essential.
- Security and Access Control: Implement strong security measures, including authentication, authorization, and encryption, to protect sensitive feature data. Define clear access policies to ensure that only authorized users and services can access or modify features.
Conclusion
The feature store has solidified its position as an indispensable component in the modern ML ecosystem. It addresses fundamental challenges related to data consistency, reusability, and operational efficiency, enabling organizations to build and deploy ML models faster and more reliably.
While commercial platforms offer highly integrated and managed experiences, the open-source landscape provides powerful, flexible, and cost-effective alternatives. Tools like Feast and Hopsworks, along with the option to build a custom DIY solution, empower teams to tailor their feature management strategy to their specific needs and resources.
Choosing the right feature store is a strategic decision that impacts the entire ML lifecycle. By carefully considering your team's size, technical capabilities, existing infrastructure, and specific use cases, you can select a solution that accelerates your MLOps journey and unlocks the full potential of your machine learning initiatives. Whether you're a solo ML engineer, part of a startup, or leading an enterprise MLOps transformation, there's an open-source feature store solution waiting to help you build more robust and impactful AI systems.
References & Further Reading
[1] Feast Documentation: https://feast.dev/
[2] Hopsworks Documentation: https://www.hopsworks.ai/
[3] Feature Stores: The Missing Layer in ML: https://www.tecton.ai/blog/feature-stores-the-missing-layer-in-ml/
[4] Hopsworks Real-Time Fraud Detection Use Case: https://www.hopsworks.ai/use-case/real-time-fraud-detection
[5] Hopsworks Anomaly Detection: https://www.hopsworks.ai/events/enterprise-ml-build-ml-apps-for-anomaly-detection
[6] What is a Feature Store for Machine Learning?: https://www.featurestore.org/what-is-a-feature-store
[7] MLOps: Building a Feature Store? Here are the top things to keep in mind: https://medium.com/data-science/mlops-building-a-feature-store-here-are-the-top-things-to-keep-in-mind-d0f68d9794c6