
The real magic trick behind Transformers → Attention.
It's not just a layer. It's the engine. The thing that makes everything else work from ChatGPT , Gemini, llama , grok , deepseek etc…
So today, we're going to focus on just one thing:
What is Attention? Why is it so powerful? And how can you actually understand it?
A Quick History: What Came Before Attention?
Let's rewind to the pre-Transformer era (before 2017):
- RNNs (Recurrent Neural Networks): Processed words one-by-one, left to right. Problem? Long sentences = memory loss.
- Imagine reading a book where you forget everything after 2 pages.
- LSTMs (Long Short-Term Memory networks): Tried to fix this. Better memory, still struggled with long-term dependencies.
- Attention Mechanism (2014): First used as a sidekick in machine translation tasks (like aligning words between languages). It improved things a lot so much that…
💥 In 2017, a paper titled "Attention Is All You Need" proposed removing RNNs entirely and keeping just the attention part.
That's right. No recurrence. No memory cells. Just Attention. That paper gave us the Transformer and changed NLP forever.
So… What Is Attention, Really?
In one sentence:
Attention tells the model which words to focus on when processing a given word.
It's like giving every word in a sentence the ability to look at every other word and ask:
"Hey, how relevant are you to me right now?"
Self-Attention: The Core Idea
Let's take this sentence: 👉 "The cat sat on the mat because it was tired."
What does "it" refer to?
- A human might say "the cat" without thinking.
- A model needs to figure this out based on word relationships.
That's what self-attention does. It scores how much each word is related to every other word.
Think of it as a giant group chat, where every word gets to gossip about every other word:
"Yo, I'm 'it'. Who's most likely my reference? Oh… 'cat' has a strong vibe. Bet."
The Math But Chill
Here's the core formula:
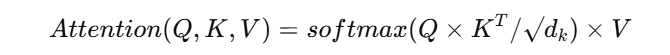
- Q = Query (what we're trying to understand)
- K = Key (what's available for lookup)
- V = Value (the meaning we extract if K is relevant)
The idea:
- Compute how similar the Query is to every Key (dot product).
- Normalize those scores using softmax.
- Use those scores to take a weighted average of the Value vectors.
Real Example: Let's Actually Do It
Example: Step-by-Step Self-Attention Calculation
Let's say we have 3 tokens: "I", "love", "pizza"
We assign each token a Query (Q), Key (K), and Value (V) vector. Let's keep it 2D for simplicity.
Step 1: Assign Vectors
Q (Queries):
I → [1, 0]
love → [0, 1]
pizza → [1, 1]
K (Keys):
I → [1, 0]
love → [0, 1]
pizza → [1, 1]
V (Values):
I → [10, 0]
love → [0, 10]
pizza → [5, 5]Step 2: Compute Attention Scores
We compute the dot product of each Query with all Keys: (Q × Kᵀ)
Let's do this for "pizza" (Q = [1, 1]):
Q_pizza ⋅ K_I = [1,1] ⋅ [1,0] = 1
Q_pizza ⋅ K_love = [1,1] ⋅ [0,1] = 1
Q_pizza ⋅ K_pizza = [1,1] ⋅ [1,1] = 2So, the raw scores for "pizza" are: → [1, 1, 2]
Step 3: Scale & Softmax
We divide by √dₖ (dimension of key vectors = 2): So, √2 ≈ 1.41
Scaled scores = [1/1.41, 1/1.41, 2/1.41] ≈ [0.71, 0.71, 1.41]Apply softmax:
softmax([0.71, 0.71, 1.41])
= exp(x) / sum(exp(x))
≈ [e^0.71, e^0.71, e^1.41] ≈ [2.03, 2.03, 4.10]
Total = 8.16
Attention weights ≈ [0.25, 0.25, 0.50]Step 4: Weighted Sum of Values
Now we multiply the weights with the corresponding Value vectors, then sum:
0.25 × [10, 0] → [2.5, 0]
0.25 × [0, 10] → [0, 2.5]
0.50 × [5, 5] → [2.5, 2.5]
Final output = [5.0, 5.0]What Just Happened?
The model looked at the word "pizza", and decided:
- "I" is a little relevant (25%)
- "love" is a little relevant (25%)
- "pizza" is highly relevant to itself (50%)
Then it blended the meanings accordingly. The result is a contextual vector for "pizza" shaped by the other words around it.
Heads-Up: What's Multi-Head Attention?
We'll save the full breakdown for another day, but in short:
Instead of computing attention once, Transformers do it multiple times in parallel, from different "perspectives" (aka, heads). Then they combine all those views into one rich, contextual representation.
You can think of it like this:
"If one head understands grammar, another might understand emotion, and another might focus on topic relevance."
All heads together = a better understanding of the sentence.
TL;DR — Attention, Simplified
Attention = "Who should I care about?" Self-Attention = "I'll look at every other word in the sentence" Formula = softmax(QKᵀ / √d_k) × V Result = Meaning that changes with context It's why Transformers work
What's Next?
Now that you understand how Transformers understand language using Attention… Next, we'll explore how they generate language.
That means: