
In the ever-evolving landscape of Generative AI, one breakthrough is making waves — Multi-Head Latent Attention (MLA), a game-changer that dramatically slashes the computational cost of training massive language models like DeepSeek, the latest buzz in GenAI. While models like GPT-4o rely on the well-established Multi-Head Attention (MHA), it comes with a significant drawback — requires a large amount of memory to store keys (k) and values (v) during inference. This memory bottleneck limits the model's efficiency, especially for long texts. MLA not only reduces memory usage but also improves performance, making large-scale training more efficient than ever. But how does it work? And why does it matter? In this article, we'll explore how MLA works, why it's better than MHA, and how it achieves these improvements. By the end, you'll have a clear understanding of MLA and its significance in transformer models like DeepSeek-R1
Multi-Head Attention (MHA): The Standard Attention Mechanism of Transformer
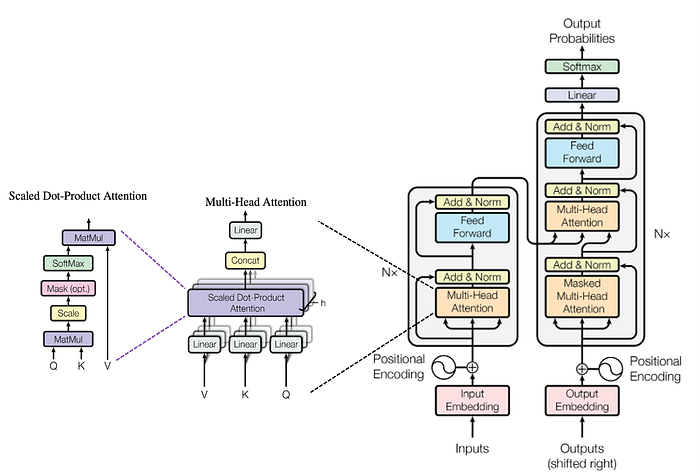
Multi-Head Attention is the backbone of transformer based large language models, enabling them to process and generate text effectively. Let us breakdown the components of MHA and how it works?
Here's a concise yet comprehensive breakdown of how MHA works:
1. Input Tokens & Embeddings

2. Computing Queries, Keys, and Values

3. Splitting into Multiple Heads

4. Computing Attention Scores

5. Computing Output

While MHA is effective, it has a major limitation — memory usage. During text generation, the model needs to store all the keys (k) and values (v) for every token it has seen so far. This is called the Key-Value (KV) cache. The size of the KV cache grows linearly with the sequence length, making it a significant bottleneck for long texts.

This large memory requirement is a significant bottleneck for efficiency.
Multi-head Latent Attention (MLA)
Multi-head Latent Attention (MLA) is a new attention mechanism designed to solve the memory problem of MHA. It achieves this by compressing the keys and values into a smaller, shared representation called a latent vector. This reduces the size of the KV cache while maintaining or even improving performance.
MLA introduces two key innovations:
- Low-Rank Key-Value Compression
- Decoupled Rotary Position Embedding (RoPE)

Low-Rank Key-Value Joint Compression
The core idea behind MLA is to compress the keys and values into a smaller representation. Instead of storing full keys and values, MLA compresses them into a latent vector. This latent vector is much smaller than the original keys and values, significantly reducing memory usage.


Decoupled Rotary Position Embedding (RoPE)
Rotary Position Embedding (RoPE) is a technique used to encode the position of tokens in a sequence. However, RoPE is position-sensitive, meaning it depends on the specific position of each token. This creates a problem when using low-rank compression because the position information gets mixed into the compressed keys and values, making it hard to reuse them efficiently during inference.


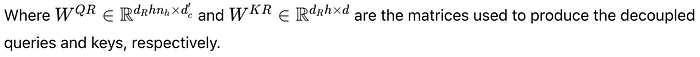
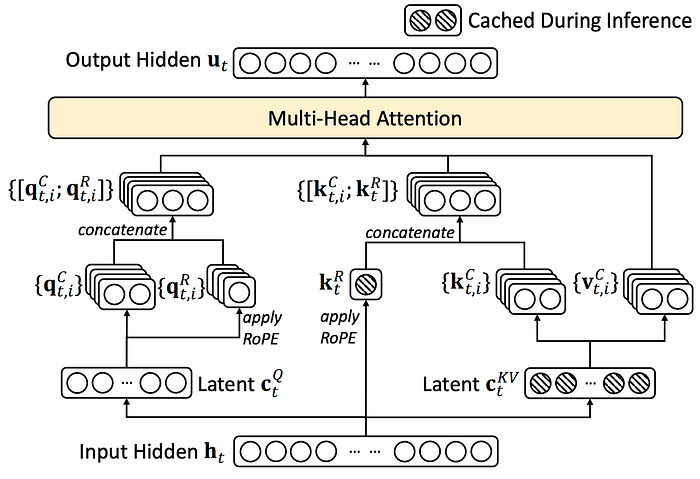
How MLA Reduces Computation During Inference
One of the key optimization in MLA is the absorption of weight matrices. This allows the model to avoid explicitly reconstructing the keys and values during inference, saving both computation time and memory.



MLA reduces the KV cache size by compressing the keys and values into a smaller latent vector and decoupling the position information (RoPE). Here's how the cache size is calculated.

Why MLA is a Game-Changer
Let us consider an example with below assumptions:

Key Takeaways
- Memory Efficiency: A smaller KV cache means the model can handle longer sequences or larger batch sizes without running out of memory.
- Inference Speed: With less data to store and retrieve, the model can generate text faster.
- Scalability: MLA makes it feasible to deploy large transformer models on devices with limited memory, like mobile phones or edge devices.
- Performance Gains: Despite its memory and computational optimizations, MLA achieves better performance than MHA, proving that efficiency and effectiveness can go hand in hand.
What's Next? If you're excited about the possibilities of MLA and want to dive deeper into its technical details, stay tuned for our upcoming articles exploring its implementation. Let us know your thoughts or questions in the comments below!
References
Vaswani, A. (2017). Attention is all you need. Advances in Neural Information Processing Systems.
Bi, X., Chen, D., Chen, G., Chen, S., Dai, D., Deng, C., … & Zou, Y. (2024). Deepseek llm: Scaling open-source language models with longtermism. arXiv preprint arXiv:2401.02954.
Liu, A., Feng, B., Wang, B., Wang, B., Liu, B., Zhao, C., … & Xu, Z. (2024). Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model. arXiv preprint arXiv:2405.04434.
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., … & Piao, Y. (2024). Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437.
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., … & He, Y. (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv preprint arXiv:2501.12948.