
For data analysis tasks and to capture the underlying patterns in the data, we need to design and prepare some features that will be used in a machine learning model. Features are the measurable properties or characteristics used as input for data analysis tasks and modeling.
This process is called Feature Engineering which includes four steps of (1) Feature Creation from data and domain knowledge (2) Feature Transformation by encoding categorical variables, aggregation (combining multiple features into a single feature), and normalization and scaling (3) Feature Selection to remove redundant features and select a subset of relevant features (4) Feature Extraction to reduce the dimentionality or dealing with text or image features.

In this article, we focus on the first two steps, namely feature creation and feature transformation.
Consider Tabular data, also called structured data, which refers to data that is organized into a table format, where each row represents an individual observation or record, and each column corresponds to a specific feature, attribute, or variable.
There are various types of features, requiring different preprocessing or handling. The main types of features are:
1- Binary Feature: has a value of either 0 or 1, indicating the presence or absence of a specific characteristic. Example: Purchased item (Yes: 1, No: 0)
2-Categorical Feature: represents (not necessarily ordered) discrete categories or labels. Example: Gender (Male, Female)
3- Numerical Feature: takes on continuous or discrete numerical values that can be ordered and have a measurable difference between them. Example: height, temperature, number of items purchased.
Note: Date/Time features (year, month, day, hour, etc.) can be cast as numerical features. Also, we can use cyclical features (e.g., sine/cosine transformation for hours).
Other types of features such as text features, image features, audio features are not considered in this article.
Normalization for Numerical Features:
Normalization (or min-max scaling) adjusts the values of a feature to fit within a specified range, typically [0, 1] or [-1, 1].

Standardization for Numerical Features:
Standardization (or z-score normalization) transforms features to have a mean of 0 and a standard deviation of 1, which makes the data normally distributed with a standard normal distribution.
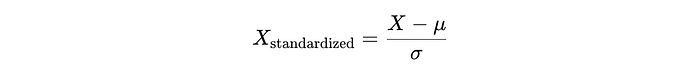
One Hot Encoding for Categorical Features:
One hot encoding is a very popular method used to represent categorical data (features) as binary vectors. Each category is represented as a binary vector where only one element is "hot" (1) and all other elements are "cold" (0). Example:

Since, we assign one binary vector for each unique category for a column in tabular dataset, one hot encoding can create thousands of new columns and high-dimensional feature vectors. This results in expensive computation and high memory consumption.
Note: One hot encoding is not so suitable for Tree-Based Models (such as decision trees or random forests), as these methods often pick a feature (column in tabular dataset) to split. If we have several levels, only a small fraction of the data will usually belong to any given level, so the one hot encoded columns will be mostly zeros. Since splitting on this column will only produce a small gain, tree-based algorithms typically ignore the information in favor of other columns.
Best Practices:
- When levels (categories) are not important, we can group them together in "Other" class.
- Make sure that unseen data in the test set are handled in the machine learning pipeline [*].
Mean Encoding for Categorical Features:
Mean encoding (also called mean target encoding or mean response encoding) is a technique in feature engineering to encode categorical variables in a way that captures the relationship between the categorical feature and the target variable.
Consider the following tabular data and we want to handle Age as a categorical feature. Thus, potentially there could be many unique values (categories) for this column. In mean encoding, we would treat the Age feature as continuous variable by taking the average of income for that Age value, and then work with Age_mean_enc feature instead of Age feature in your model.

This method simplifies categorical data, but can create problems when dealing with new or unseen categories in the test set. In addition, mean encoding can lead to label leakage, as the information from the target variable (or label) is influencing the features used to train the model. To mitigate this issue we use (1) a separate data set to compute mean encoding, (2) cross validation methods, to further improve the robustness.
Label Encoding for Categorical Features:
Label encoding is a technique used to convert categorical variables into numerical format. In this method, each unique category in the categorical variable is assigned a distinct integer value. For example "the" is mapped to 1, "cat" is mapped to 2, and "sat" is mapped to 3, and then the original categorical values in the dataset are replaced with their corresponding integer values.
While label encoding is simple and easy to use, it introduces an ordinal relationship between categories, which may not exist in the original data. In addition, label encoding is not suitable for all ML models. Label encoding is generally not appropriate for regression task, while it can be suitable for tree-based models.
Feature Hashing for Categorical Features:
Similar to label encoding, the feature hashing (also called hashing trick), is a technique for transforming categorical data into numerical representations. Feature Hashing employs a prespecified hash function to the input data to map categories into a fixed-size vector space (called hash buckets), unlike label encoding which would map m categories into m numerical values.
Feature hashing is primarily used to encode high-dimensional categorical features into a lower-dimensional space. Thus, in that sense feature hashing can be thought of as grouping categories.
Cross Feature (Conjunction):
For categorical features x1 and x2, we can create a new categorical feature x3:=x1*x2. Cross feature is usually used with a hashing trick to reduce the high dimensions.
Cross features are also very common in recommendation systems. This allows to consider linear models such as a1x1+a2x2+a3x3.
[*] A machine learning pipeline refers to the sequence of steps of the machine learning process to automate the process of preparing data, training a model, and evaluating its performance.
The ML pipeline includes data preprocessing, model training and evaluation, post-processing (e.g., adjusting thresholds), and prediction. ML pipeline is a key component of the ML system design.