
"Have you ever searched for something on Google and found exactly what you needed within the first few results?
That's no accident — it's the magic of Learning-to-Rank algorithms."
When I first started working with search engines and recommendation systems, I was struck by how critical ranking is.
It's not just about finding results; it's about finding the right results.
Think about it: if Amazon didn't recommend products relevant to your preferences, or if Netflix showed you completely irrelevant movies, you'd likely lose interest. Ranking is the backbone of these systems.
This guide is for those of you who want to dive deep into implementing Learning-to-Rank (LTR) algorithms, not just learning their theory.
From my experience, most tutorials miss the hands-on details that make or break real-world projects.
So here, I'll focus on what matters most — clear implementation steps, pitfalls to watch for, and practical advice you can put into action right away.
If you're an experienced Data Scientist or ML Engineer, this is for you. My goal is to share practical knowledge so you can build, optimize, and deploy LTR models in your own systems.
2. Core Concepts and Objectives
Let me keep this brief because I know you're not here for a lecture. Learning-to-Rank (LTR) is all about ordering results in a way that maximizes relevance for a user.
In my projects, this often means balancing multiple factors: user behavior, item quality, and system-specific metrics like clicks or purchases.
Types of LTR: Which One Should You Use?
Here's how I think about it:
- Pointwise: This approach treats ranking as a regression or classification task. For example, predicting the relevance score of a query-document pair. It's simple and works well when your labeled data is straightforward. Best for: Systems with clean, explicit feedback data.
- Pairwise: Compares two items and predicts which one should rank higher. I've used this when data is noisy because it's often easier to label "A is better than B" rather than assigning absolute scores. Best for: Handling inconsistent or biased user feedback.
- Listwise: Looks at the entire ranked list and optimizes it as a whole. When I worked on optimizing recommendations for a streaming platform, this was a game-changer for improving metrics like nDCG. Best for: When you care about the global quality of the ranking.
Key Metrics in LTR
In my experience, you can't improve what you don't measure. These are the metrics I always rely on:
- Mean Reciprocal Rank (MRR): Measures the rank of the first relevant result. Use this when the top result is critical (e.g., search queries where users rarely scroll). Formula:
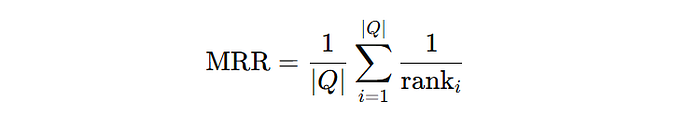
If your system shows relevant results far down the list, this metric will expose it.
- Normalized Discounted Cumulative Gain (nDCG): This is my go-to metric when relevance varies across results. It rewards ranking highly relevant items higher up. Formula:
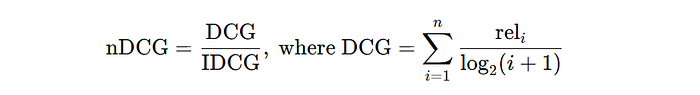
- I've found nDCG particularly useful in recommendation systems where items have varying levels of importance.
Here's a simple Python snippet I often use to calculate nDCG for a given ranking:
import numpy as np
def dcg(relevance_scores, k):
relevance_scores = np.asarray(relevance_scores)[:k]
return np.sum(relevance_scores / np.log2(np.arange(2, relevance_scores.size + 2)))
def ndcg(relevance_scores, k):
dcg_score = dcg(relevance_scores, k)
ideal_relevance = sorted(relevance_scores, reverse=True)
idcg_score = dcg(ideal_relevance, k)
return dcg_score / idcg_score if idcg_score > 0 else 0
# Example usage:
relevance_scores = [3, 2, 3, 0, 1, 2] # Relevance scores for a ranked list
k = 5
print("nDCG@5:", ndcg(relevance_scores, k))Pro Tip for Choosing Metrics
"You might be wondering: Should I always optimize for a single metric?"
In my experience, the answer is no.
Use multiple metrics to understand your system holistically. For example, combine nDCG (to reward relevance) with click-through rate (CTR) to gauge user engagement.
3. Data Preparation for LTR
"You can't build a great ranking model with bad data. Trust me, I've tried, and it just doesn't work."

When I started working on Learning-to-Rank systems, one of the biggest challenges was preparing data that could actually teach the model what "relevance" means.
LTR thrives on good data, so this section is all about ensuring you get that right.
Data Sources
The first step is collecting high-quality labeled data. Personally, I've found user interaction data (like clicks, purchases, or ratings) to be goldmines.
For instance, in an e-commerce project, I used clickstream data to extract features like time spent on a page, add-to-cart actions, and eventual purchases.
Here's the deal: raw user interaction data is often noisy and biased. If you're working with logs, make sure to filter out bot traffic and outliers.
One technique I've used is session filtering, where I discard sessions with unusually high activity rates (e.g., hundreds of clicks per second).
Feature Engineering
From my experience, the features you create can make or break your model. Here are a few that have consistently worked for me:
- Query-Document Features:
- Term frequency (TF)
- Inverse document frequency (IDF)
- Cosine similarity between query and document embeddings.
2. Behavioral Features:
- Click-through rate (CTR).
- Average time spent per item.
- User-item interaction counts (e.g., how often a user interacts with similar items).
Here's an example of feature engineering using Python and pandas:
import pandas as pd
import numpy as np
# Example: Clickstream data
data = pd.DataFrame({
'query': ['laptops', 'laptops', 'headphones'],
'doc_id': [101, 102, 201],
'clicks': [5, 2, 3],
'impressions': [10, 10, 5]
})
# Feature engineering
data['ctr'] = data['clicks'] / data['impressions'] # Click-through rate
data['log_ctr'] = np.log1p(data['ctr']) # Log transformation
print(data)This snippet creates CTR features, which are crucial for most LTR models.
Dealing with Bias
Bias in user data can skew your models. For instance, I've often seen position bias, where items higher in the list get more clicks simply because they're seen first. Here's what worked for me:
- Randomization during data collection:
- For one of my projects, we shuffled results for a subset of users to break the position bias. The resulting data was a lot more reliable.
2. Inverse Propensity Weighting:
- Another effective method is applying weights to clicks based on their position. Here's a quick example:
positions = np.array([1, 2, 3]) # Positions in the ranked list
clicks = np.array([10, 5, 2]) # Corresponding clicks
# Calculate weights using a simple decay model
weights = 1 / np.log2(positions + 1)
weighted_clicks = clicks * weights
print("Weighted Clicks:", weighted_clicks)This technique helps your model understand the true relevance of lower-ranked items.
4. Choosing the Right LTR Model
"I've tried them all — gradient boosting, neural networks, even transformers. The key is knowing when to use what."
Comparison of LTR Algorithms
- Gradient Boosting (e.g., LambdaMART):
- I've used this for most of my LTR projects because it's fast, interpretable, and handles sparse data well. If you're dealing with tabular features, LambdaMART is a solid choice.
2. Neural LTR Models (e.g., RankNet, ListNet):
- These shine when you have dense embeddings or contextual information. In a project where we ranked product search results, using neural models significantly improved relevance by capturing deeper patterns.
3. Transformer-Based Models (e.g., BERT):
- When I worked on text-heavy ranking tasks, like document search, transformer models like BERT were game-changers. However, they're resource-intensive, so I usually combine them with faster models for deployment.
Trade-offs
Choosing a model depends on your priorities. Here's a quick guide based on my experience:

Code Example: LambdaMART with LightGBM
Here's a code snippet for training a LambdaMART model using LightGBM. I've used this exact setup for ranking e-commerce products.
import lightgbm as lgb
import pandas as pd
# Sample dataset
data = pd.DataFrame({
'query_id': [1, 1, 2, 2],
'doc_id': [101, 102, 201, 202],
'feature1': [0.2, 0.4, 0.6, 0.8],
'feature2': [1, 0, 0, 1],
'relevance': [3, 2, 1, 0] # Labels
})
X = data[['feature1', 'feature2']]
y = data['relevance']
group = [2, 2] # Number of documents per query
# Train LambdaMART
train_data = lgb.Dataset(X, label=y, group=group)
params = {
'objective': 'lambdarank',
'metric': 'ndcg',
'ndcg_at': [1, 3],
'learning_rate': 0.05,
'num_leaves': 16
}
model = lgb.train(params, train_data, num_boost_round=100)
# Predict
preds = model.predict(X)
print("Predictions:", preds)Advanced Note: Hybrid Models
In one of my projects, we combined LambdaMART with neural embeddings from a BERT model.
The embeddings captured semantic similarity, while LambdaMART optimized for ranking. This hybrid approach gave us the best of both worlds.
5. Implementing LTR: End-to-End Workflow
"Building a Learning-to-Rank system is like solving a puzzle — you need all the right pieces, but they have to fit together perfectly. I've learned this the hard way."
This section will walk you through an end-to-end implementation of an LTR model, from setting up your dataset to deploying the final system. I'll share the exact steps I've followed in real-world projects, along with code you can use or adapt.
Dataset Setup
Before jumping into training, you need a good dataset. I've often used publicly available datasets like Yahoo LTR, MS MARCO, and Kaggle datasets to get started.
These datasets come with labeled relevance data, making them perfect for training LTR models.
Here's how I set up the data pipeline for an LTR project:
import pandas as pd
from sklearn.model_selection import train_test_split
# Load Yahoo LTR dataset
data = pd.read_csv("yahoo_ltr.csv")
# Split data into train and test
train_data, test_data = train_test_split(data, test_size=0.2, random_state=42)
# Create group data (queries grouped by query ID)
train_group = train_data.groupby('query_id').size().tolist()
test_group = test_data.groupby('query_id').size().tolist()
print(f"Train size: {len(train_data)}, Test size: {len(test_data)}")Pro Tip: Always check for imbalances in your dataset. In one project, I found that some queries had hundreds of documents while others had only a handful, which skewed the model. Normalizing query-document pairs can improve results significantly.
Model Training
For this walkthrough, I'll focus on training a LambdaMART model using LightGBM. Why LambdaMART? Because it's scalable, interpretable, and works exceptionally well for ranking tasks.
Here's how I set it up:
import lightgbm as lgb
# Prepare features and labels
X_train = train_data[['feature1', 'feature2', 'feature3']]
y_train = train_data['relevance']
X_test = test_data[['feature1', 'feature2', 'feature3']]
y_test = test_data['relevance']
# Convert group sizes to LightGBM format
train_group = train_data.groupby('query_id').size().tolist()
test_group = test_data.groupby('query_id').size().tolist()
# Train the LambdaMART model
train_dataset = lgb.Dataset(X_train, label=y_train, group=train_group)
test_dataset = lgb.Dataset(X_test, label=y_test, group=test_group, reference=train_dataset)
params = {
'objective': 'lambdarank',
'metric': 'ndcg',
'ndcg_at': [1, 3, 5],
'learning_rate': 0.1,
'num_leaves': 31,
'min_data_in_leaf': 20,
}
model = lgb.train(params, train_dataset, valid_sets=[test_dataset], num_boost_round=100, early_stopping_rounds=10)
# Save the model
model.save_model('lambdamart_model.txt')Hyperparameter Tuning
Getting the best results often requires fine-tuning. I've used Optuna for automated hyperparameter optimization, and it has saved me countless hours.
Here's how you can integrate Optuna with LightGBM for LTR:
import optuna
def objective(trial):
params = {
'objective': 'lambdarank',
'metric': 'ndcg',
'ndcg_at': [1, 3, 5],
'learning_rate': trial.suggest_loguniform('learning_rate', 0.01, 0.2),
'num_leaves': trial.suggest_int('num_leaves', 16, 64),
'min_data_in_leaf': trial.suggest_int('min_data_in_leaf', 10, 50),
}
model = lgb.train(params, train_dataset, valid_sets=[test_dataset], num_boost_round=100, early_stopping_rounds=10, verbose_eval=False)
ndcg_score = model.best_score['valid_0']['ndcg@3']
return ndcg_score
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=50)
print("Best parameters:", study.best_params)Pro Tip: In one project, tuning num_leaves and min_data_in_leaf significantly boosted nDCG without increasing training time too much.
Evaluation
"You can't improve what you don't measure."
I've always relied on metrics like nDCG and MRR to evaluate LTR models.
Here's how I calculate nDCG and MRR step-by-step:
from sklearn.metrics import ndcg_score
# Generate predictions
y_pred = model.predict(X_test)
# Calculate nDCG
ndcg_at_3 = ndcg_score([y_test.values], [y_pred], k=3)
print(f"nDCG@3: {ndcg_at_3}")Production-Ready Pipelines
Once your model is trained, you'll need to deploy it. I've used FastAPI and Docker for scalable deployments. Here's a quick pipeline:
- FastAPI for Serving Predictions:
from fastapi import FastAPI, Query
import lightgbm as lgb
import numpy as np
app = FastAPI()
# Load the trained model
model = lgb.Booster(model_file='lambdamart_model.txt')
@app.post("/predict/")
def predict(features: list = Query(...)):
features = np.array(features).reshape(1, -1)
prediction = model.predict(features)
return {"ranking_score": prediction.tolist()}2. Dockerfile for Containerization:
FROM python:3.8-slim
COPY . /app
WORKDIR /app
RUN pip install fastapi uvicorn lightgbm
CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "8000"]Deploying this way ensures your model can handle real-time predictions with low latency. One thing I've learned: always monitor the system after deployment. Sometimes, user behavior shifts, and you'll need to retrain the model.
6. Tools and Libraries for LTR
"When I first started implementing Learning-to-Rank systems, choosing the right tools felt overwhelming. But over time, I've narrowed it down to a handful of frameworks that deliver results consistently."
Popular Frameworks
Let me walk you through the tools I've used and why they work:
- TensorFlow Ranking I've used TensorFlow Ranking for neural LTR models. It's especially handy when you're already working in a TensorFlow ecosystem. You can define custom loss functions and scale easily. Example: Optimizing nDCG directly in a deep learning pipeline.
2. RankLib Back when I worked on my first LTR project, RankLib was my go-to. It's a Java-based tool, great for quick experiments with traditional algorithms like LambdaMART. While I've moved on to Python-based solutions, it's still worth exploring.
3. LightGBM I've found LightGBM to be the most versatile for LTR tasks. Its LambdaMART implementation is fast and easy to integrate into any pipeline. Plus, it handles large-scale datasets like a champ.
4. PyTorch-Based Libraries For advanced neural LTR, PyTorch gives you the flexibility to implement custom architectures. Once, I combined PyTorch with pre-trained transformers like BERT for a document ranking task, and the results were outstanding.
Tools for Evaluation
Evaluation can be tricky, especially when you're juggling multiple metrics. Personally, I've relied on MLflow to track experiments. It simplifies tracking and comparing metrics across runs.
Here's a snippet for integrating MLflow into your LTR pipeline:
import mlflow
import lightgbm as lgb
# Start MLflow tracking
mlflow.start_run()
# Train your model
params = {'objective': 'lambdarank', 'metric': 'ndcg', 'learning_rate': 0.1}
train_data = lgb.Dataset(X_train, label=y_train, group=train_group)
model = lgb.train(params, train_data, num_boost_round=50)
# Log model and metrics
mlflow.lightgbm.log_model(model, "ltr_model")
mlflow.log_metric("ndcg@3", model.best_score['valid_0']['ndcg@3'])
mlflow.end_run()This makes it easy to track experiments and ensures you don't lose critical insights.
Snippet: Integrating LTR into MLOps
Once, I had to integrate an LTR pipeline into a full-scale MLOps workflow. Here's an example of how I structured it:
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from lightgbm import LGBMRanker
# Define the pipeline
pipeline = Pipeline([
('scaler', StandardScaler()),
('ranker', LGBMRanker(objective='lambdarank', metric='ndcg'))
])
# Train the pipeline
pipeline.fit(X_train, y_train, ranker__group=train_group)
# Save the pipeline
import joblib
joblib.dump(pipeline, "ltr_pipeline.pkl")7. Advanced Techniques in LTR
"As LTR evolves, staying ahead means exploring advanced techniques. Here are some that I've used to take ranking systems to the next level."
Neural LTR Models
Neural models bring in the ability to understand complex relationships.
I've used BERT and T5 for contextual ranking tasks, like improving search relevance in NLP-heavy systems.
Here's a simplified PyTorch snippet for using BERT for LTR:
from transformers import BertTokenizer, BertModel
import torch.nn as nn
# Load BERT
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
bert_model = BertModel.from_pretrained("bert-base-uncased")
class NeuralRanker(nn.Module):
def __init__(self, bert_model):
super(NeuralRanker, self).__init__()
self.bert = bert_model
self.fc = nn.Linear(768, 1) # Output a single relevance score
def forward(self, input_ids, attention_mask):
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
cls_output = outputs.last_hidden_state[:, 0, :] # CLS token output
return self.fc(cls_output)
# Example usage
ranker = NeuralRanker(bert_model)Pro Tip: Fine-tuning transformers requires a lot of computational power, so consider using smaller pre-trained models like DistilBERT if resources are limited.
Learning to Optimize (L2O)
L2O is an emerging trend where optimization itself becomes a learning problem. Although I haven't fully implemented this yet, it's worth exploring if you're working on cutting-edge research.
Ensemble Techniques
One of my favorite tricks is combining models. For example, I've often paired LambdaMART with neural embeddings to get the best of both worlds.
Here's how you can ensemble them:
import numpy as np
# Predictions from LambdaMART and neural model
preds_lambdamart = np.array([0.8, 0.6, 0.4])
preds_neural = np.array([0.7, 0.5, 0.3])
# Weighted ensemble
ensemble_preds = 0.7 * preds_lambdamart + 0.3 * preds_neural
print("Ensemble Predictions:", ensemble_preds)Cross-Domain Ranking
In one project, I had to apply an LTR model trained on one domain to another. Transfer learning worked like a charm.
By fine-tuning the neural embeddings for the new domain, I could quickly adapt the model without starting from scratch.
Here's a simplified PyTorch example:
# Assuming ranker is the BERT-based ranker from above
optimizer = torch.optim.Adam(ranker.parameters(), lr=1e-5)
# Fine-tune on new data
for epoch in range(5):
ranker.train()
for batch in new_domain_loader:
input_ids, attention_mask, labels = batch
optimizer.zero_grad()
outputs = ranker(input_ids, attention_mask)
loss = nn.MSELoss()(outputs.squeeze(), labels.float())
loss.backward()
optimizer.step()8. Conclusion
"If there's one thing I've learned about Learning-to-Rank systems, it's that the devil is in the details."
Creating an effective LTR system isn't just about picking the right model or framework — it's about understanding the nuances of your data, the goals of your system, and the real-world constraints you'll face.
Throughout this guide, I've shared the approaches and techniques that have worked for me, from carefully engineering features to leveraging advanced neural architectures.
Here are a few parting thoughts:
- Start with the basics but aim for scalability: Tools like LightGBM and LambdaMART are great for getting a robust baseline. Once you have a solid foundation, you can experiment with neural models and ensembles to push the limits of performance.
- Always measure, iterate, and adapt: Metrics like nDCG and MRR are your best friends. They tell you where your model is excelling and where it's falling short. Use them wisely, and don't hesitate to go back and refine your approach.
- Keep deployment in mind from day one: It's easy to get carried away with complex models, but what matters is how they perform in production. Simplicity and scalability often trump complexity in real-world systems.
Finally, don't stop experimenting. The field of Learning-to-Rank is evolving rapidly, and there's always a new technique, tool, or framework to explore.
Whether you're tuning hyperparameters, building a hybrid model, or fine-tuning transformers, every project is an opportunity to learn something new.
Good luck, and feel free to share your thoughts, challenges, or successes — I'd love to hear how you're applying these techniques in your work. Let's keep pushing the boundaries of what's possible in search engines and recommendation systems!