
Introduction
About
This paper proposes SimMTM, a simple yet effective self-supervised learning framework tailored for masked time-series modeling (MTM). SimMTM introduces a manifold-based approach that reconstructs the original time series from multiple randomly masked variants, rather than relying on a single corrupted view. Through extensive experiments across diverse datasets and tasks — including forecasting and classification — the framework demonstrates consistent improvements over previous state-of-the-art methods in both in-domain and cross-domain settings.
Background
Self-supervised pre-training has gained traction across modalities, particularly in vision and NLP, offering a means to learn robust representations from unlabeled data. In the context of time-series data, two major paradigms have emerged: contrastive learning and masked modeling. Contrastive methods, such as SimCLR, TimeCLR, and TS2Vec, learn representations by maximizing similarity between augmented versions of the same input (positive pairs) while distinguishing them from others (negative pairs). These approaches exploit the structural invariance of time series through techniques like dynamic time warping, patch-wise augmentation, or seasonality disentanglement. While effective, contrastive learning often targets high-level semantics and may underperform on low-level tasks like fine-grained forecasting.
Masked modeling, on the other hand, draws from advances in NLP (e.g., BERT) and computer vision (e.g., MAE), focusing on learning to reconstruct masked parts of the input from its unmasked context. This technique has been applied to time series via models like TST and Ti-MAE, which predict missing values based on randomly masked sequences. However, time series present unique challenges: unlike discrete tokens in text or patches in images, essential semantics in time-series data are embedded in temporal variations such as trends and seasonality. Randomly masking individual time points may destroy these structures, rendering the reconstruction problem excessively hard and counterproductive for learning useful representations. Motivated by this, the authors revisit the problem from a manifold learning perspective, aiming to recover original sequences through aggregation across multiple corrupted versions, thereby capturing the local structure of the data distribution more effectively.
Method
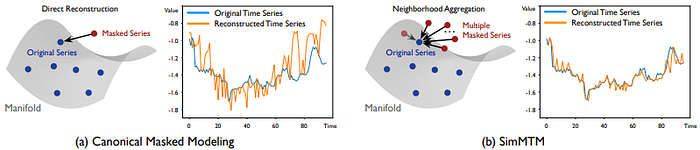
SimMTM is a novel pre-training framework for time series that addresses the drawbacks of random temporal masking by reconstructing the original signal using multiple masked views. As shown in Figure 1, SimMTM views it through the lens of manifold learning, instead of treating the masked modeling task as a direct denoising problem. The proposed manner assumes that masked variants lie near the original signal on the data manifold. This view enables the model to aggregate information from several partially corrupted instances to restore the full sequence, making the task more stable and informative for representation learning.
Temporal Masking
In the first step, each time series sample xᵢ∈ℝᴸᕽꟲ is used to create M randomly masked variants, where a masking ratio r ∈ [0,1] determines the proportion of time points replaced by zeros:
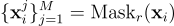
The total input set 𝒳 includes the original series and its masked augmentations:

This augmentation is used to generate two types of supervision:
- Series-wise contrastive pairs, where xᵢ and xᵢʲ are treated as positives.
- Point-wise reconstruction targets, where xᵢ serves as the ground truth for reconstruction from its neighbors.
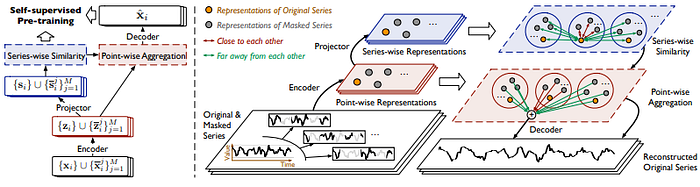
This masking process is visualized in the left side of Figure 2, where the original and masked series form the basis for contrastive and reconstruction objectives.
Series-wise Contrastive Learning
All sequences in 𝒳 are passed through a shared encoder to generate temporal representations z∈ℝᴸᕽᵈ. A temporal pooling layer (e.g., average or max pooling) condenses these into series-level embeddings s∈ℝ¹ᕽᵈ:
SimMTM computes the pairwise similarity among all embeddings in 𝒮, forming a matrix 𝐑∈ℝᴰᕽᴰ, where D = N(M + 1) using cosine similarity:

From these, SimMTM defines a contrastive loss that pulls each series sᵢ toward its masked augmentations {sᵢʲ} and pushes it away from representations of other sequences {sₖ,sₖʲ} for k ≠ i:
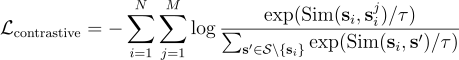
This process is illustrated in the upper right side of Figure 2. Importantly, the model captures series-level semantics (e.g., trends, seasonal patterns) in this space, making the similarity matrix useful for downstream aggregation.
Point-wise Reconstruction via Neighborhood Aggregation
The key novelty of SimMTM lies in its point-wise reconstruction strategy, depicted in the center right side of Figure 2. Instead of reconstructing the time series from its own corrupted view, SimMTM aggregates representations from other masked series using a similarity-based weighted sum.
Let ẑᵢ∈ℝᴸᕽᵈ denote the aggregated latent sequence for reconstructing xᵢ. It is computed as:

The point-wise representation ẑᵢ is then decoded into the final reconstruction:

The reconstruction loss is:
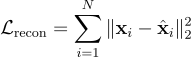
This reconstruction is not just a denoising operation — it enforces the model to learn the manifold structure of the time series space, since reconstruction depends on similarity-aware aggregation from diverse neighborhoods.
Self-Supervised Pre-training Objective
To ensure the structural consistency of the learned representation space, SimMTM introduces an additional manifold constraint loss. Based on the assumption that masked views of the same sample should be closer than others, the loss penalizes violations of this proximity assumption:
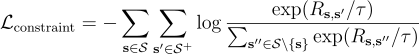
Here, 𝒮ᕀ includes all masked versions of the same sample, while negatives are all others.
The total loss combines reconstruction and constraint terms:
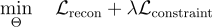
The hyperparameter λ is tuned adaptively using uncertainty estimation techniques from prior work.
Experiment
To evaluate SimMTM, the authors designed a comprehensive set of experiments across a range of representative real-world time series benchmarks. The goal is to verify whether the framework can learn transferable and effective representations that generalize to both low-level tasks like forecasting and high-level tasks such as classification. Experiments are conducted under in-domain and cross-domain transfer settings to validate SimMTM's generality.
Dataset

The experimental study spans twelve datasets across two primary tasks: forecasting and classification. These datasets cover diverse modalities such as electricity consumption, EEG signals, traffic data, and gesture or fault detection patterns.
- Forecasting Datasets: — ETTh1, ETTh2, ETTm1, ETTm2: Electricity load series with different sampling rates. — Weather, Electricity, Traffic: Public datasets capturing environmental and infrastructure-related time series.
- Classification Datasets: — SleepEEG, Epilepsy: EEG-based physiological signal classification. — FD-B, Gesture, EMG: Time series from mechanical or muscular sensor data.
These datasets differ significantly in temporal resolution, channel dimensionality, and sequence length, providing a robust benchmark for evaluating representation generality.
The summary of the employed datasets are briefly shown in Table 1.
Model Set-up
To ensure fair comparisons across different methods, the authors adopt a unified encoder strategy for both tasks:
- Forecasting: — Encoder: Vanilla Transformer with channel-independent modeling (following PatchTST). — Pretext Task Input Length: 336 — Prediction Lengths: 96, 192, 336, 720 (averaged for evaluation) — Optimization: Adam optimizer — Training Details: Same masking ratio and augmentation count across all methods.
- Classification: — Encoder: 1D ResNet as in TF-C. — Pre-trained representations from SimMTM are transferred to downstream classifiers.
- Pre-training Loss: Combination of reconstruction and constraint loss.
- Decoder: Simple MLP layer across the channel dimension.
Comparison
SimMTM is compared against a range of state-of-the-art pre-training baselines, both contrastive and masked modeling based:
- Contrastive Learning Methods: — TF-C, TS2Vec, CoST, LaST, Mixing-Up
- Masked Modeling Methods: — Ti-MAE, TST
- Foundation Models: — NS-Transformer, AutoFormer, Vanilla Transformer (for forecasting)
The results are reported using unified encoders, and where appropriate, include comparisons to performance with the authors' original configurations.
Evaluation Metrics
Two main categories of metrics are employed:
- Forecasting: Mean Squared Error (MSE), Mean Absolute Error (MAE)
- Classification: Accuracy (Acc)
Results
Main Results
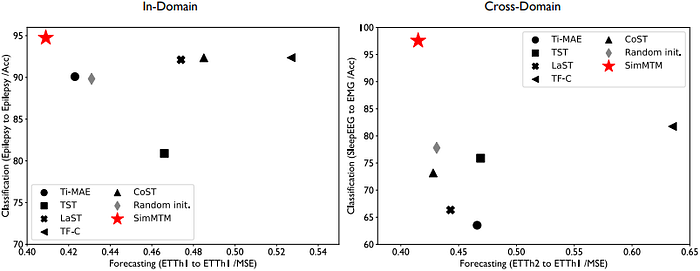
Figure 3 (left) summarizes the performance of all models under the in-domain setting. SimMTM consistently outperforms both masked modeling and contrastive learning baselines across nearly all benchmarks. Figure 3 (right) shows SimMTM maintains its advantage even in cross-domain scenarios, highlighting its robustness in transferring learned representations.
Forecasting
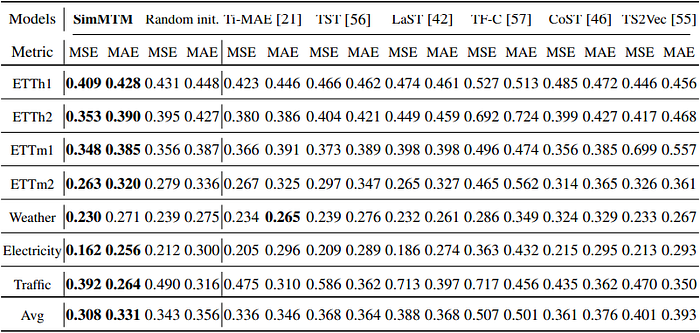
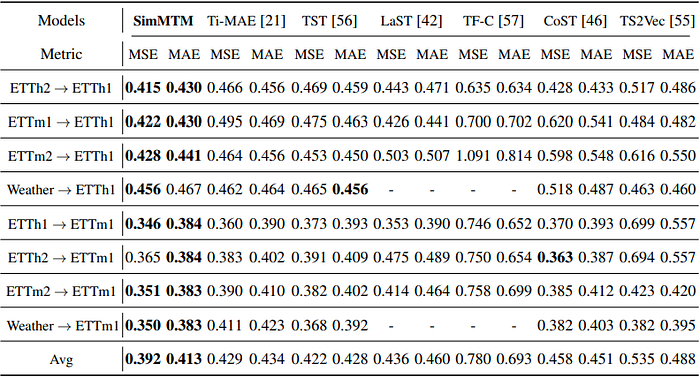
In Table 2 and Table 3, SimMTM demonstrates strong performance gains in forecasting tasks, regardless of In-domain task and Cross-domain settings. Especially, the performance improvement is particularly evident on challenging datasets like ETTh2 and ETTm2, where SimMTM handles noisy and non-stationary trends more effectively.
Classification

As shown in the accuracy results in Table 4, SimMTM significantly improves classification accuracy over contrastive learning-based methods such as TF-C and CoST. Notably, while Ti-MAE performs well on forecasting, it fails to generalize to classification, reinforcing SimMTM's value in unifying series- and point-level learning in terms of both In-domain and cross-domain tasks.
Model Analysis

- Ablations: The authors ablate major design choices in SimMTM to assess their contributions. As shown the outcomes in Figure 4, removing the contrastive objective degrades classification accuracy, while discarding point-wise reconstruction harms forecasting, confirming the complementary nature of these two components. Additionally, replacing manifold aggregation with direct reconstruction notably reduces overall performance.
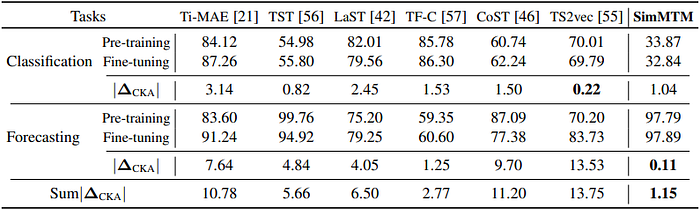
- Representation Analysis: The results of the conducted representation analysis tests are depicted in Table 5. Through t-SNE visualizations, SimMTM shows clearer clustering and class separability compared to Ti-MAE and TF-C. Furthermore, reconstructions under high masking ratios retain seasonality and structure, highlighting the model's ability to preserve temporal semantics via neighborhood aggregation.
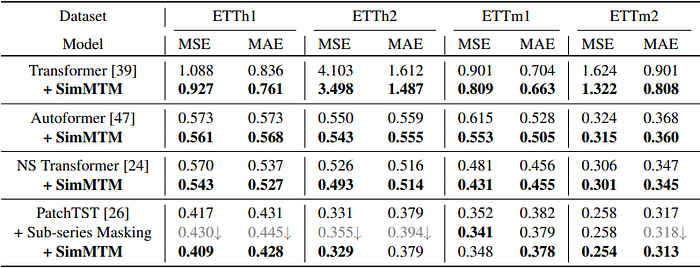
- Model Generality: As shown in Table 6, SimMTM exhibits encoder-agnostic transferability. When pre-trained using a Transformer and fine-tuned using a 1D ResNet (and vice versa), it still outperforms methods trained from scratch or using prior pre-training techniques. This suggests that the learned representations are not tightly coupled to any specific backbone.
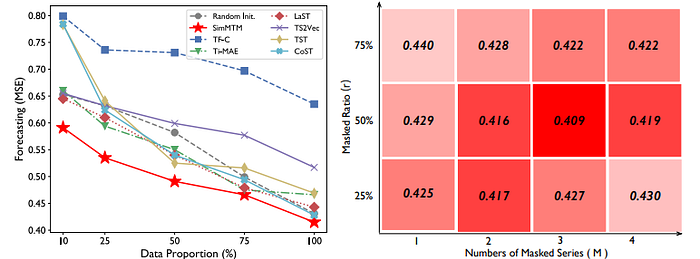
- Fine-tuning on Limited Data: According to the results of the authors' experiments in the left part of Figure 5, the framework is shown to be data-efficient. When fine-tuned with only a small fraction of labeled data (as low as 20%), SimMTM retains competitive performance, outperforming baselines that degrade more steeply under data scarcity.
- Masking Strategy: Finally, the authors explore how different masking ratios and numbers of augmented views affect results. The corresponding outcomes are depicted in the right part of Figure 5. SimMTM is robust across a wide range of masking settings, and increasing the number of masked views improves performance up to a saturation point — supporting its core assumption of manifold smoothness and aggregation benefit.
Conclusion
SimMTM proposes a conceptually simple yet highly effective framework for pre-training time series models. By shifting from direct masked reconstruction to manifold-aware neighborhood aggregation, the framework addresses the shortcomings of conventional MTM and contrastive learning. SimMTM unifies series-wise and point-wise objectives to yield generalizable representations for diverse tasks. Its performance on both forecasting and classification, under in-domain and cross-domain settings, confirms the model's adaptability and robustness. The combination of masked augmentation, contrastive similarity, and aggregation-driven reconstruction establishes SimMTM as a new benchmark for time-series pre-training.
Review
The paper presents a principled and well-executed contribution to the field of self-supervised time-series learning. SimMTM's integration of multiple masked augmentations and its projection onto the manifold via weighted aggregation address a key weakness of existing masked modeling techniques — the destruction of temporal coherence. Its modular and encoder-agnostic architecture also facilitates easy adaptation to various tasks. Importantly, the unification of high-level and low-level representation learning within a single framework results in significant performance gains, as demonstrated across a wide spectrum of datasets. The inclusion of contrastive and reconstruction signals ensures that the model captures both global semantics and local structures.
However, some limitations remain. The computational overhead introduced by maintaining multiple masked variants and computing a full pairwise similarity matrix may limit scalability in high-throughput or low-resource settings. Also, while the manifold learning view is compelling, its application depends heavily on the quality of learned similarities, which might be unstable in sparse or noisy domains. Potential researches may explore more efficient similarity modeling, adaptive neighbor selection, or dynamic masking strategies to enhance scalability and robustness. Nevertheless, this paper makes a notable advancement in time-series representation learning and sets a strong foundation for further exploration in self-supervised sequence modeling.
Reference
SimMTM: A Simple Pre-Training Framework for Masked Time-Series Modeling
I always think time series analysis-forecasting is a field with a lot of research topics!