


Problem Statement:
We want to know if an user 'U' is allowed to see a piece of content 'S' or a ticket 'T'
We want to limit the no of times an user 'U' views a ticket 'O' in a time period 'T'
We want to know the number of users who have visited a particular page 'P'
Existing Solutions:
Each of the above problems are well defined and have been around with us in the Computer Science world for a long time. They all have solutions that could give us an exact/correct answer at the expense of growing Space & Time complexity.
For example, lets consider this problem statement :
We want to limit the no of times an user 'U' views a ticket 'O' in a time period 'T'
In its essence this is a "counting" problem. We want to maintain a count of how many times an actor / actors are visiting the underlying resource. A simple algorithm will look like this:
BEGIN
Define a hashmap or set with a TimeToLive(TTL) of T time units
An entry in the above map would be product_user_apiEndpoint_allowed_value:current_value
Everytime a view-ticket event occurs, make an entry in the hashmap above
Check if current_value is > allowed_value:
return decision to BlockUsage
else
return decision to AllowUsage
Reset the map/set at the end of TTL
DONENow, lets step back and ask our self some questions:
Q: Do we need the count to be exact, for example, lets say we want to limit users to view a ticket only 100 times per Minute, would we be adversely affected if the viewed it a 105 times? Ideally, the answer to that question should be "No". When we define a limit we should probably be doing it with a lot of headroom left for us.
So what useful insight does that give us? Well, it tells us that we could live another day with approximations which are close enough for this problem class and that, my dear friends, opens us up to a world of possibilities.
Lets welcome the class of data structures called "Sketches", as someone else put it succinctly, its like a well made replica of "The Mona Lisa", its not quite the real deal but good enough

Luckily for us, the well made replica is good enough. 😉
Count Min Sketch
This was originally described in https://dsf.berkeley.edu/cs286/papers/countmin-latin2004.pdf, the Abstract of which reads as follows:
Abstract: We introduce a new sublinear space data structure—the Count-Min
Sketch— for summarizing data streams. Our sketch allows fundamental queries
in data stream summarization such as point, range, and inner product queries to
be approximately answered very quickly; in addition, it can be applied to solve
several important problems in data streams such as finding quantiles, frequent
items, etc. The time and space bounds we show for using the CM sketch to solve
these problems significantly improve those previously known — typically from
1/ε2 to 1/ε in factor.Now, lets continue back to English and try to break down what is means for us.
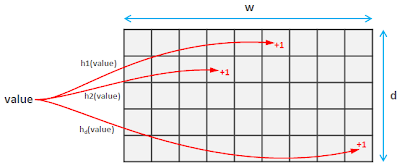

Now that the Count part is over, lets move on to the Min part of Count Min Sketch.
Now lets assume that we want to find out how many times, the no 84 has been seen. The final state of the above matrix after hashing 84 is shown below :
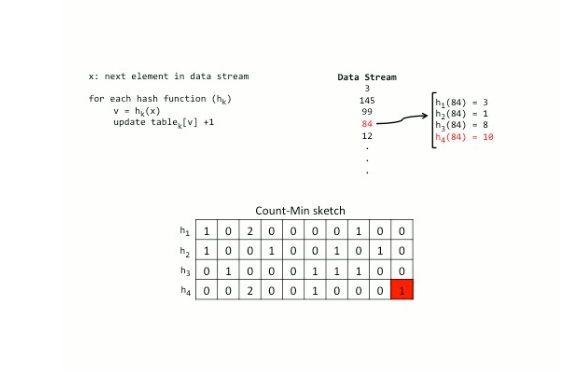
You could see from the animation above that h1(145) =3 && h1(84) = 3 what this means is that both 145 and 84 have incremented the cell M[1][3] [Yeah the notation is not 0 based] as the hash function h1 produces the same hash value for both those keys (In other words there is a hash collision).
So when we want to get the no. of times we have seen the number 84, we should take the min across all hash functions, i.e.,
count(84) = min( M[1][3], M[2][1], M[3][8], M[4][10] )
count(84) = min( 2, 1, 1, 1)
count(84) = 1See, we feel much better already. Now, to put it all together,
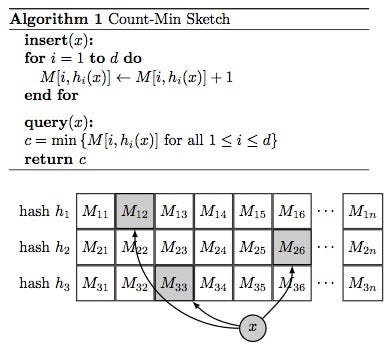
Here is a sample implementation:
class CountMinSketch {
long estimators[][] = new long[d][w] // d and w are design parameters
long a[] = new long[d]
long b[] = new long[d]
long p // hashing parameter, a prime number. For example 2^31-1
hash(value, i) {
return ((a[i] * value + b[i]) mod p) mod w
}
void initializeHashes() {
for(i = 0; i < d; i++) {
a[i] = random(p) // random in range 1..p
b[i] = random(p)
}
}
void add(value) {
for(i = 0; i < d; i++)
estimators[i][ hash(value, i) ]++
}
long estimateFrequency(value) {
long minimum = MAX_VALUE
for(i = 0; i < d; i++)
minimum = min(
minimum,
estimators[i][ hash(value, i) ]
)
return minimum
}
}It is worth noting that width of the sketch limits the magnitude of the error and height (also called depth, i.e., no of hash functions used) controls the probability that estimation breaks through this limit.

That should explain why this is called a "probabilistic" data structure in other words, why this is a well made Mona Lisa replica rather than the original, it has most of the information from the actual one but not all and probably why she's smiling more. 😉
So what is the big deal with this you ask, lets go back to the problem statement and run some numbers through..
Lets say we have 1 Million Customers — Lets say we have a 32 bit representation of a customer
API Endpoint — String
With Redis v4.0.1 64-bit and jemalloc, the empty string measures as follows:
> SET "" ""
OK
> MEMORY USAGE ""
(integer) 51
These bytes are pure overhead at the moment as no actual data is stored, and are used for maintaining the internal data structures of the server.
Longer keys and values show asymptotically linear usage.
> SET foo bar
OK
> MEMORY USAGE foo
(integer) 54
> SET cento 01234567890123456789012345678901234567890123
45678901234567890123456789012345678901234567890123456789
OK
127.0.0.1:6379> MEMORY USAGE cento
(integer) 153So lets say we have 4 Bytes (32 bit repr for a CustomerId), 200 Bytes (String repr for API Endpoint) Assuming we have about 1 Million hits per second, means that we store 204 * 1,000,000 ~= 100 MB
Safe to say that as the number of things we want to rate limit grows and the number of customers grow we are going to have a lot of Memory overhead.
Now lets run this same scenario on a Count Min Sketch (CMS):
The space complexity of CMS is the product of w, d and the width of the counters that it uses. For example, a sketch that has 0.01% error rate at probability of 0.01% is created using 10 hash functions and 2000-counter arrays. Assuming the use of 16-bit counters, the overall memory requirement of the resulting sketch's data structure clocks in at 40KB (a couple of additional bytes are needed for storing the total number of observations and a few pointers)
For a more detailed look at how one could play around with the error parameters, look at https://crahen.github.io/algorithm/stream/count-min-sketch-point-query.html
There are ways to improve against the effects of collisions to reach better counts, these are described in details here : https://highlyscalable.wordpress.com/2012/05/01/probabilistic-structures-web-analytics-data-mining/
So how could we bring all this together on a Rate Limiting example you ask, lets see if we could determine that.
Policy:
product: {Eg: Google Slides}
customer_type: {Eg: Enterprise, Premium}
resource_type: {Eg: API Call, Experience, DB Time, DB Query}
allowed_limit: {Eg: 1000, 200, 10ms, 100}
duration: {Eg: 1m, 1m, 1s, 30s}CMS DS:
Have a CMS defined per product, per customer, per resource for the lowest indivisible time unit (Lets take a Second to be this unit).
That should leave us with
Product_CustomerType_API_CMS_S1, Product_CustomerType_Experience_CMS_S1, Product_CustomerType_DBTime_CMS_S1 etc, each of these for fixed window intervals of 1 Second.
The natural question then becomes, What if I want to be able to rate limit across multiple Seconds, we have you covered here : http://practicalquant.blogspot.com/2012/11/hokusai-adds-a-temporal-component-to-count-min-sketch.html, start from Hokusai from Yahoo! Research [https://arxiv.org/abs/1210.4891]. Once we are done with the linear aggregations we could choose to cull these data structures (Eg: Cleanup everything for the prior day).
If you are thinking well all that is great but I do not really want to spend a lot of time implementing the ideas presented, then lucky you, Here is the Redis implementation of the same : https://oss.redislabs.com/redisbloom/CountMinSketch_Commands/ This is a gif, wait for it 😉
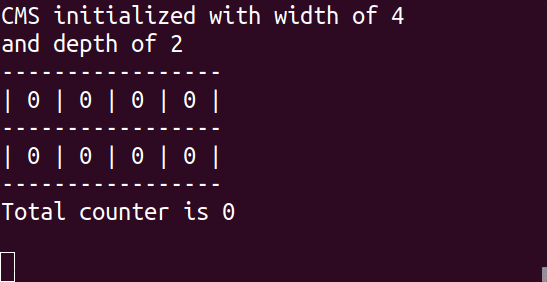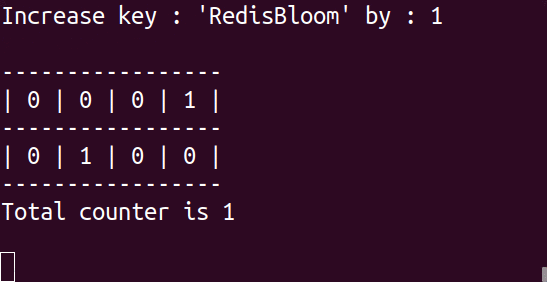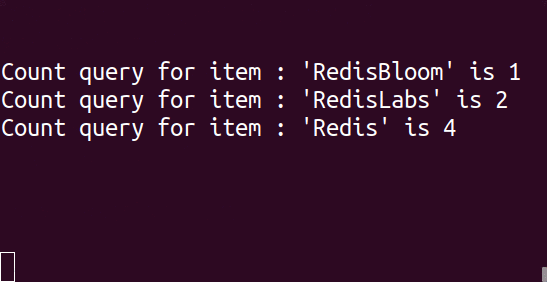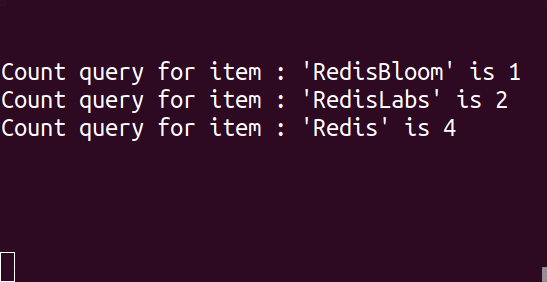
SparkLib Implemetation : https://spark.apache.org/docs/latest/api/java/index.html?org/apache/spark/util/sketch/CountMinSketch.html
References & Further Reading:
https://github.com/florian/reading-notes/blob/master/papers/016_What_is_Data_Sketching_and_Why_Should_I_Care.md https://redislabs.com/blog/count-min-sketch-the-art-and-science-of-estimating-stuff/ https://redislabs.com/blog/how-to-get-started-with-probabilistic-data-structures-count-min-sketch/ https://highlyscalable.wordpress.com/2012/05/01/probabilistic-structures-web-analytics-data-mining/ http://practicalquant.blogspot.com/2012/11/hokusai-adds-a-temporal-component-to-count-min-sketch.html https://dsf.berkeley.edu/cs286/papers/countmin-latin2004.pdf https://towardsdatascience.com/big-data-with-sketchy-structures-part-1-the-count-min-sketch-b73fb3a33e2a http://web.stanford.edu/class/cs369g/files/lectures/lec7.pdf
Bloom Filters
For example, lets consider the problem statement : We want to know if an user 'U' is allowed to see a piece of content 'S'', An algorithm would look like this:
BEGIN
Define a MxN matrix where M = No of Spaces, N = No of Users
Mark the cell M[r][c] as TRUE if an user 'U' is allowed to view the content 'S'
When queried for whether an user is allowed to view the Space, return the above value
DONEThe obvious problem with this is going to be the width and depth of that matrix. Storing and retrieving such a massive data set will be strenuous. Could we do better?
To be continued….