Imagine you're the hiring manager of a company. But instead of employees, you're managing features in a regression model. At first, you're excited — you've got a massive pool of candidates, all eager to contribute.
But soon, you realize a problem. Some features are all-stars, making valuable contributions. Others? They're just taking up space, adding no value, causing unnecessary confusion and inefficiency.
If you keep everyone, your company (model) might suffer from overcrowding and inefficiency (overfitting). If you cut too many, you might lose key contributors. So, how do you build a team that's lean, efficient, and high-performing? That's where regularization techniques come in!
TYPES OF REGULARIZATION TECHNIQUES
- Ridge Regression (L2 Regularization)
- Lasso Regression (L1 Regularization)
- ElasticNet Regression
Ridge Regression (L2 Regularization)
Ridge Regression (also called L2 Regularization) adds a penalty term to the least squares cost function which is used to prevent overfitting. Let's understand what is overfitting.
What is overfitting?
A perfect fit (error = 0) means the model has memorized the training data exactly.
While this might seem ideal, it causes poor generalization, meaning the model does not perform well on new data.
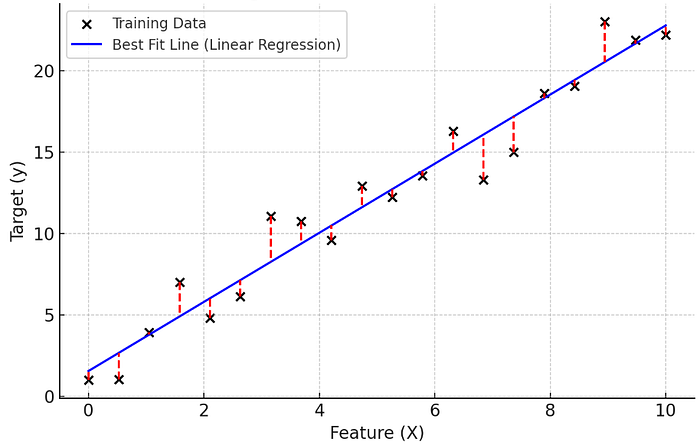
The black dots represent actual data points.
The blue line is the best fit line obtained from linear regression.
The red dashed lines show the errors (residuals), which are the differences between actual values and predicted values.
Here, if the error is approximately equal to zero, which means the model is overfitted, that is
It will have high accuracy for train data(low bias).
It will have low accuracy for test data (High Variance).
To reduce it , one of the regularization is ridge regression.
Cost function of Linear Regression:
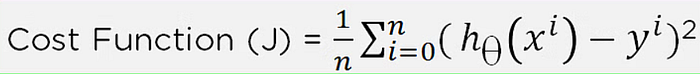
Here the value of cost function should not be zero. If it is zero , then the model is said to be overfitted. To overcome this we add a hyperparameter
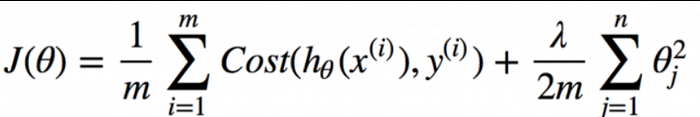
where,
- λ controls the strength of regularization,
- The additional term λ(∑θ²) penalizes large values of the regression coefficients.(where θ is slope)
- When λ=0 (orange line), the cost function behaves like standard linear regression.
- As λ increases, the curve steepens, penalizing large θ values.
- Higher λ values (pink line) push θ towards zero, reducing model complexity and preventing overfitting.
- As slope value increases , hyperparameter λ value decreases

Key Takeaways
✅ Ridge regression tunes linear regression by adding a regularization term that prevents overfitting. ✅ The cost function should not be zero, as that would mean perfect prediction, which is impractical in real-world applications. ✅ The hyperparameter λ controls the slope (θ), preventing extreme values and improving model generalization. ✅ Choosing the right λ is crucial — too small, and overfitting persists; too large, and underfitting occurs.
Lasso Regression (L1 Regularization)
Lasso Regression (Least Absolute Shrinkage and Selection Operator) is a powerful regularization technique, unlike Ridge Regression, which only shrinks coefficients, Lasso has a unique ability, that is it can force some coefficients to be exactly zero, effectively performing automatic feature selection.
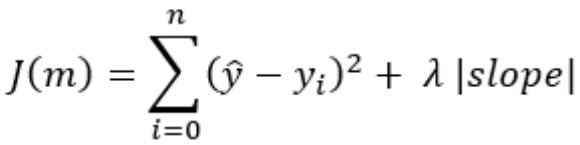
- As λ increases, the slope values (coefficients) shrinks and sometimes reaches zero due to the L1 penalty.
- Thus Lasso helps in feature selection by forcing some coefficients to become exactly zero.

Key Takeaways:
✔ Feature Selection — Lasso (L1 regularization) can shrink some feature coefficients to exactly zero, effectively selecting only the most important features and removing irrelevant ones.
✔ Sparsity in Coefficients — Due to the absolute penalty term λ∣θ∣, Lasso encourages sparse models, making them more interpretable.
✔ Prevents Overfitting — By penalizing large coefficients, Lasso reduces model complexity, improving generalization on unseen data.
✔ Effect of λ Higher → More coefficients become zero (stronger regularization) Lower → Retains more features (weaker regularization).
✔ Best for High-Dimensional Data — Lasso is effective when the number of features is large, as it automatically selects the most relevant ones.
ElasticNet Regression
The cost function for Elastic Net regression combines both Ridge (L2) and Lasso (L1) regularization
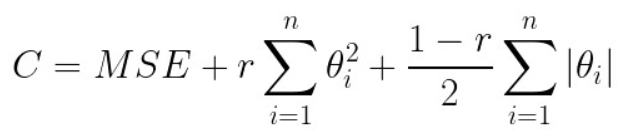
where:
- MSE is the Mean Squared Error.
- λ1 (L1 penalty) encourages sparsity (zero coefficients).
- λ2 (L2 penalty) shrinks coefficients but retains all features.
where,
- Lasso (Red, Dashed): Coefficients shrink to zero.
- Ridge (Blue, Dotted): Coefficients gradually decrease but stay nonzero.
- Elastic Net (Green, Solid): A combination of both — coefficients shrink but do not drop to zero abruptly.
Conclusion:
Final Thought
- If overfitting is your concern → Use Ridge
- If you need automatic feature selection → Use Lasso
- If you need both effects combined → Use Elastic Net
By carefully choosing the right technique, you can build more robust and interpretable models that balance accuracy and simplicity. Keep experimenting ! keep learning !