

Think in Blocks[1] framework is a simple, yet, impactful enhancement in LLM reasoning by dynamically allocating reasoning depth based on problem complexity. Through a three-stage training process — supervised fine-tuning, direct preference optimization, and reinforcement learning — it enables large language models to predict and generate discrete reasoning blocks. This approach balances accuracy and efficiency, reducing token use and latency while improving performance. Think in Blocks ensures flexible, context-aware AI reasoning ideal for diverse applications, from simple queries to complex problem-solving.
Introduction
Overthinking Problem in Reasoning LLM Models
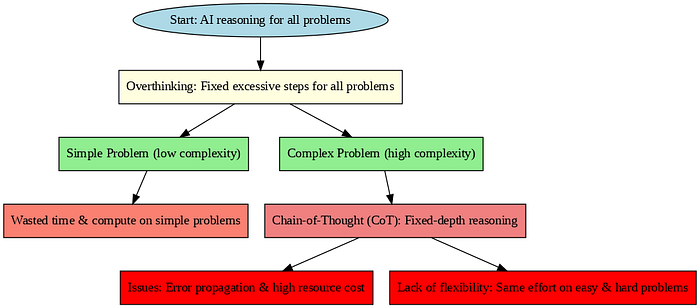
By applying a fixed or excessive number of reasoning steps to every problem, regardless of its complexity, Reasoning models frequently fall victim to the "overthinking" trap. This is comparable to when a student wastes time and effort by spending hours solving a straightforward math problem as though it were a challenging calculus problem. Such overthinking reduces the efficiency and viability of AI systems for large-scale or real-time applications by increasing computational costs and delaying response times.
Limitations of Chain-of-Thought Methods
Chain-of-Thought (CoT) prompting allows AI to generate intermediate reasoning steps, improving performance on complex tasks. However, using a fixed depth of reasoning for all prompts causes issues. CoT can propagate errors through each step, leading to faulty conclusions. Additionally, multi-step reasoning consumes more tokens and computational resources, often unnecessarily for simpler tasks. This fixed-depth approach lacks flexibility, making AI systems inefficient by spending equal effort on easy and hard problems alike and increasing latency and cost.
Think in Blocks Framework in a Nutshell
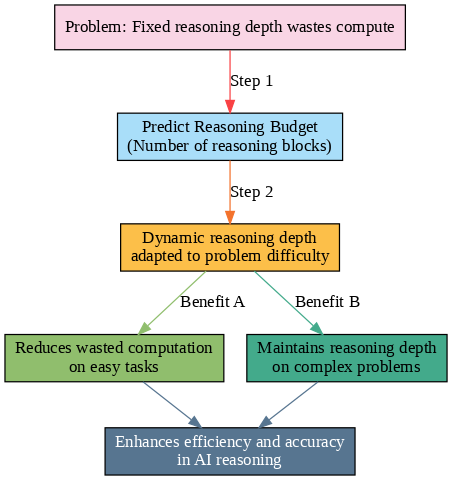
The Think in Blocks framework addresses these challenges by enabling AI models to dynamically decide how much reasoning they require for each specific problem. Instead of a one-size-fits-all solution, it predicts a "budget" of reasoning blocks tailored to the difficulty of the question. This adaptive approach significantly cuts down wasted computation on easy tasks while maintaining the depth needed for complex problems, enhancing both efficiency and accuracy in modern AI reasoning systems.
Current Reasoning Models
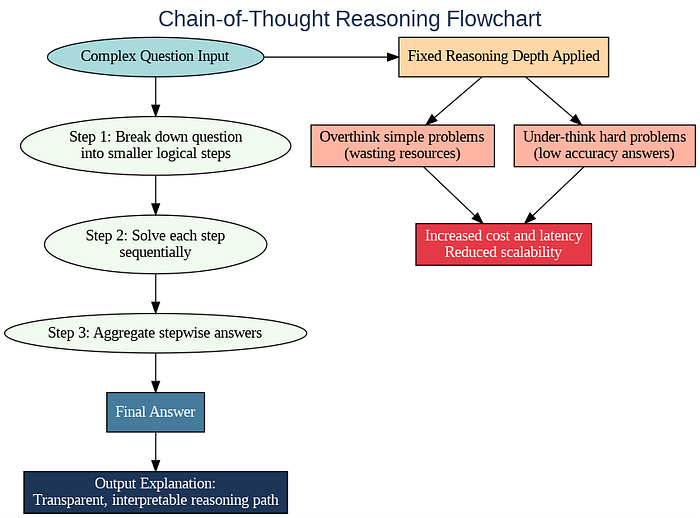
Reasoning techniques in large language models, rely heavily on fixed-depth strategies like Chain-of-Thought (CoT) prompting. This improves ability to solve complex tasks by generating intermediate reasoning steps, effectively mimicking human thought processes. However, this fixed-depth approach applies the same reasoning length to every problem, regardless of its difficulty, which creates inefficiencies and practical challenges in deployment.
Chain-of-Thought (CoT) Reasoning
Chain-of-Thought reasoning works by breaking down complex questions into a sequence of smaller, logical steps. By doing so, it enhances the model's ability to arrive at accurate answers for tasks that require multi-step reasoning, like math problems or logical puzzles. This method improves transparency and interpretability in AI responses, allowing users to follow the model's reasoning path step-by-step.
Fixed Length Reasoning: Overthinking Simple Problems & Under-Thinking Hard Ones
A major drawback of fixed-depth Chain-of-Thought (CoT) reasoning is its uniform application to all problems, regardless of complexity. This causes AI models to overthink simple tasks by engaging in overly long reasoning chains that waste valuable computational resources and time. Conversely, these models under-think challenging problems needing deeper analysis, resulting in incomplete or inaccurate answers. Such imbalance hampers AI's effectiveness and efficiency. Fixed reasoning depths increase latency and consume excessive tokens during easy tasks, while failing to provide sufficient reasoning for harder ones. This rigidity limits scalability and elevates operational costs, reducing AI's usability in real-time and large-scale deployments.
Think in Blocks Deep Dive
By moving away from static, fixed-depth approaches, "Thinking in Blocks"empowers large language models to tailor their reasoning effort dynamically to each individual problem. This flexibility addresses the dual challenges of overthinking simple tasks and under-thinking complex ones, enabling models to allocate just the right amount of cognitive resources, thus optimizing both accuracy and computational cost.
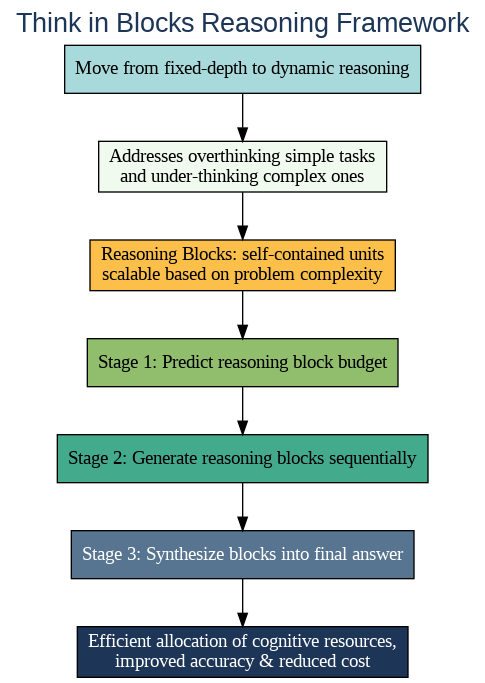
At the heart of "Think in Blocks" lies the notion of "reasoning blocks" — self-contained units of thought that the model can flexibly assemble based on the problem's complexity. Instead of committing to a fixed number of steps, the Model predicts how many blocks it needs to thoroughly solve a given question. Each block can represent a distinct logical step, a tool invocation, or a sub-analysis, allowing the model to scale its reasoning depth up or down in a granular, controlled way.
Three-Stage Reasoning Process Overview: Prediction, Block formation, Answer
The Think in Blocks process unfolds in three key stages. First, the model predicts a "budget" for how many reasoning blocks are required before starting the analysis. Next, it sequentially generates the content of each block, executing the targeted reasoning or computation. Finally, after completing all blocks, the model synthesizes the results into a final answer. This structured approach empowers models to "think about their thinking" and allocate effort more efficiently and transparently.
Examples of Blocks
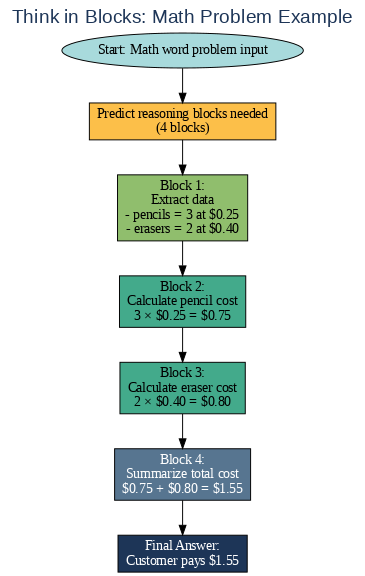
Consider a math word problem that requires multiple steps to solve. Using Think in Blocks, the model might predict it needs four reasoning blocks — one to extract relevant data, two to perform sequential calculations, and a final block to summarize the answer. Conversely, for a straightforward factual question, it might allocate zero or one block, directly generating an answer with minimal computation. This adaptability marks a major improvement over rigid, one-size-fits-all reasoning methodologies.
How It Works: Training and Mechanism
Think in Blocks framework employs a sophisticated three-stage training pipeline that empowers the model to dynamically allocate reasoning effort. It begins with supervised fine-tuning to teach the model the fundamental block-based reasoning format and generate examples from zero-block to multi-block reasoning. Next, direct preference optimization refines the model's ability to select an appropriate reasoning depth by rewarding difficulty-aligned responses that balance thoroughness with brevity. Finally, reinforcement learning fine-tunes the reasoning policy, optimizing for accuracy while controlling computational costs and maintaining consistent block structure.
Difficulty-aware responses & balancing accuracy vs length
A central innovation of Think in Blocks is its difficulty-aware response mechanism that conditions the model's reasoning depth on the complexity of the input. Through training rewards that consider both answer accuracy and token usage, the model learns to avoid unnecessary verbosity for simple queries while allocating sufficient reasoning steps for difficult problems. This balance between accuracy and response length leads to more efficient use of computational resources, reduces latency, and improves overall model performance in adaptive reasoning settings.
Practical controls (auto/override modes)
To ensure applicability across diverse use cases, Think in Blocks offers practical control modes for reasoning depth. In auto mode, the model dynamically determines the number of reasoning blocks required for each query, optimizing efficiency without user intervention. The override mode empowers users or applications to set explicit minimum or maximum block limits, catering to needs such as strict latency requirements or critical accuracy demands. These control features provide flexibility and enable seamless integration of the framework into real-world AI deployments.

Real-World Impact and Results
Token efficiency improvements and speed gains
By allocating just enough reasoning blocks, the framework reduces latency and computational load, leading to meaningful speed improvements in response generation. Experimental results demonstrate that Think in Blocks can maintain or improve answer accuracy while dramatically lowering token consumption, enabling faster and more cost-effective model deployments.

Use cases: enterprise AI, edge computing, cost control
By dynamically adjusting reasoning depth, enterprises can better control computational expenses while maintaining service-level accuracy requirements. The framework's efficiency gains also make AI more practical on edge devices with limited resources, enabling local inference with intelligent reasoning capacity. Cost control is further enhanced through the option to fix reasoning depth limits via override mode, allowing organizations to balance accuracy and budget constraints tightly.
Challenges & Future Directions
Format Reliability & Training Stability
Think in Blocks does face technical challenges including ensuring consistent adherence to the block-structured reasoning format, which is critical for interpretability and downstream processing. Additionally, maintaining stable and efficient training across the three-stage pipeline requires sophisticated methods to prevent issues like mode collapse or reward hacking during reinforcement learning. Addressing these challenges is essential for reliable, scalable deployment.
Research Opportunities
Future research opportunities include exploring integrating external tools within reasoning blocks, and automating adaptive block sizing in more complex domains. The deployment roadmap envisions incremental integration into production AI systems starting with latency-sensitive edge applications and expanding to large-scale enterprise solutions. Building comprehensive evaluation benchmarks and interpretability tools will further support widespread adoption and continuous improvement of the Think in Blocks approach.
References
- Zhu, Chen, Mao (2025) — Think in Blocks: Adaptive Reasoning from Direct Response to Deep Reasoning. (Introduces block-wise adaptive reasoning.)
- Mathur et al. (2025) — Change of Thought: Adaptive Test-Time Computation. (Framework for switching between shallow vs deep reasoning.)
- Li et al. (2025) — AdaptThink: Reasoning Models Can Learn When to Think. (RL-based method for deciding reasoning depth adaptively.)
- Wang et al. (2025) — Adaptive Deep Reasoning: Triggering Deep Thinking When Needed. (Dynamic triggering of long-form reasoning only when necessary.)
- Wei et al. (2024) — Scaling LLM Test-Time Compute Optimally can be More Effective than Increasing Model Size.(Foundational work on test-time compute scaling strategies.)
A message from our Founder
Hey, Sunil here. I wanted to take a moment to thank you for reading until the end and for being a part of this community.
Did you know that our team run these publications as a volunteer effort to over 3.5m monthly readers? We don't receive any funding, we do this to support the community. ❤️
If you want to show some love, please take a moment to follow me on LinkedIn, TikTok, Instagram. You can also subscribe to our weekly newsletter.
And before you go, don't forget to clap and follow the writer️!