
The basics of TDD and why I decided to write this short-series of texts are the themes of Part 1.
Later, in Part 2, I presented the Detroit school of TDD as we dove into some interesting concepts about Clojure, such as schemas, Java Interop and some language-agnostic concepts such as The 3 laws of TDD.
In this part we will understand how the London Approach of TDD is different from Detroit's, learn about mocks, while I share some of my personal thoughts on how make use of these tools.
I wrote this series with an incremental approach in mind. It means that I'll make constant references to content of other parts, so please, if you have not done yet, read the previous parts before going beyond this point.
TDD crossing the Atlantic
After Kent Beck started the XP movement in Detroit, as discussed in Part 2, some of the early adopters were in the London area.
When applying TDD, they took a slightly different approach: Instead of starting with the less dependent part of a system, they decided to follow the execution flow: Start from the application entry point and go towards the lowest-level layers.
In our example, the Quadratic formula, this means to start writing our quadratic-formula function, and after we are done with it, create the discriminant function.
But, since quadratic-formula is dependent upon discriminant, how can we go on?
Mocks

Those early adopter of TDD began writing some Object Oriented constructs to replace objects that were not implemented yet. With time they started aggregating more functionalities to those constructs, such as validating how many times one given function was called, and which arguments were used. After a while, they realized that they had something very useful in their hands, and created the first mock libraries.
If you are interested in learning how mock came to be on that early days of Test Driven Development, I recommend reading A Brief History of Mock Objects.
So, when using London School of TDD and you see yourself making some call to code that has not been written yet, you just mock it.
Mock libraries come in all colors and flavors. Whichever language you end up using, you can count as sure that someone somewhere made a mock library for that language.
For Clojure it is not different. We have MockFn, created by some folks at Nubank!
Starting from scratch
We will continue to use the Quadratic as subject of our study on TDD, but will start a new project from scratch, clicking File -> New -> Project:
I named my new project as quadratic-london, but you may choose whatever name suits you best.
After doing this, I added both plumatic/schema and nubank/mockfn as dependencies in project.clj.
Now we are ready to start! Again…
A skeleton in the closet
As I mentioned in part 2, sometimes I like creating some skeleton implementation of my functions, in order to verify if my tests fail. I'll define both my functions:
These two guys don't do much. The function discriminant only returns the BigDecimal zero, and quadratic-formula a set containing BigDecimal zero.
Wait a minute… You may be wondering how the heck I know about the existence of discriminant even before creating quadratic-formula. Doesn't it feel like cheating? Do I only know about it because it was already created in part 2?
Now we are heading to MyOpinionLand. This are my personal thoughts on the subject, based on my experience:
When I first started using TDD, years ago, I haven't made much prior research about it. I watched some videos, listened to a few podcasts, bought the idea and tried on my own, only to fail.
I was trying, empirically, use the London School of TDD. I started following the execution flow, even used mocks, but always ended up losing myself somewhere in the middle and giving up writing the tests. Then, one day, it struck me like a bolt! The problem was that I had no idea where I was heading to. I just let the code guide myself, instead of driving it. I was a passenger instead of the pilot.
I started drafting my classes and methods(I still used Java back then), planning my code before implementing it.
Often I say that doing Test Driven Development improved the quality of my code tenfold. I believe that it was, mostly, because it taught me the importance of planning before writing code.
Our first test using mock
Now we can continue and write our first test. We already know that our quadratic-formula function will eventually call our discriminant function. We also know that for
a=1, b=-1, c=-12 the result of the discriminant should be 49,
and
the result of the quadratic-formula should be a set containing 4 and -3 ( #{4M, -3M})
That is enough information to code our test:
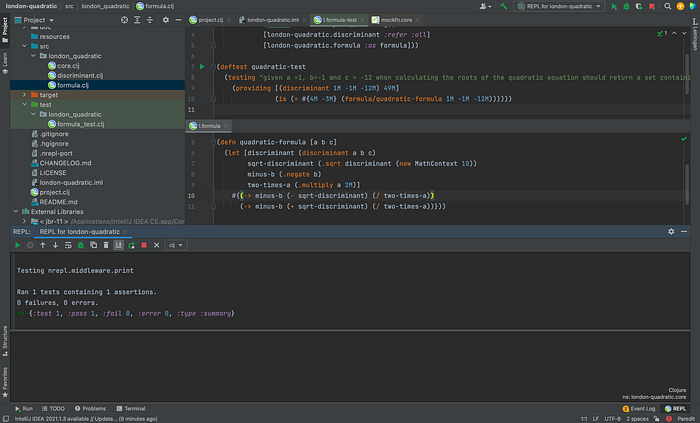
Please take a look at line 8. There we have:
(providing [(discriminant 1M -1M -12M) 49M]
...)The macro providing, from mockfn, creates a mock for discriminant function, in a way that given it was called with BigDecimals 1, -1 and -12, it should return the BigDecimal 49.
When we run this test, it fails, just as expected:

Let's take a closer look at the feedback message that was displayed:
FAIL in (quadratic-test) (formula_test.clj:10)
given a =1, b=-1 and c = -12 when calculating the roots of the quadratic equation should return a set containing 4 and -3
expected: (= #{-3M 4M} (formula/quadratic-formula 1M -1M -12M)) actual: (not (= #{-3M 4M} #{0M}))We expected to receive a set containing -3 and 4, but got a set with 0, since it is what our skeleton function gave us. Now we can write the production test to make it pass:
And now our test passes:
Using Schemas
In part 2 we discussed how using schemas can prevent abnormal behavior if our function receives something that is not a BigDecimal as a parameter.
We should apply the same here. There is really no difference here from what we did using the Detroit approach, so instead of going step by step showing how our code will incrementally grow, I'll share the end result. Sorry for hushing.
The test will comprehend the validations for a,b and c
And the production code will use s/defn instead of defn, and make use :- macro to specify the type.
Don't forget the discriminant
Now that our quadratic-formula function is ready, we can create discriminant.
As it is the least dependent module in our system, there is no difference from what we did before, in part 2. We will end up with this test:
and this production code:
The code
You can find the complete code of this part of the series in:
Some disclaimers
The Quadratic Formula, our subject in this series, is a bit simplistic to apply the London School in all it's glory. In real life, if you end-up having to deal with some calculation, you should isolate that in a pure function (and TDD it). Our discriminant is exactly that. Instead of mocking it, a true London TDD'er would isolate that part in a pure function and probably never think about mocking it. But that would defeat the point of using this as an exercise on TDD to learn how to use this techniques.
Pure functions are the heart and soul of functional programming. They are function the have two attributes:
1- deterministic, for a given set of arguments always return the same thing
2- has no side effect. Don't produce any other change in the system. Printing something in the screen, in a file, changing anything in a database, calling an external API or producing a message are some examples of side-effects.
Our simplistic exercise is 100% pure, and it is what makes it wonderful to learn about TDD. Pure functions are extremely easy to test. They are predictable and don't rely on external things such as databases and message-brokers.
In real life, where we have to deal with external dependencies, mock shines. It removes dependency and turns the unpredictable in a set of expected values.
Even if you are following the Detroit school of TDD and following the dependency flow, you can leverage from mocking.
Our subject here is simplistic. One interesting experiment, for sake of learning, could be encapsulating it inside an API, having to isolate it from the non-pure functions out there. I recommend you to try this for yourself!
Writing this part was not a walk in the part. When I started writing the series, I planned divide it in 3 parts, so this was supposed to be the last. There are a bunch of topics that I still want to cover, and this part started getting too big. I ended up deciding to keep it shorter, and discuss the other topics in the next part. But, then, it got too small. I hope, in the end, achieved a good balance. Please let me know if you have any feedback.
In the next (and hopefully last) part of this series, I'll discuss the limitations of TDD, and how schemas can be used for more than type checking.
Keep reading
Part 4 is available: