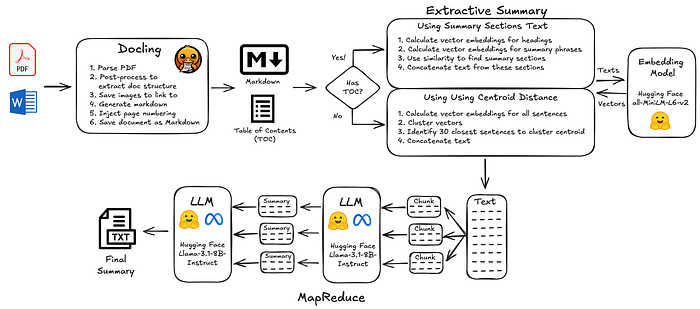


In this article, we explore how to process United Nations humanitarian evaluation reports, using AI to generate document summaries. These summaries are key to presenting reports on websites, as well as being an important component in subsequent AI analysis. Evaluation reports from 2023 to 2025 were parsed to extract text and document structure. Two different extractive summary methods were tested for generating text input for AI-generated summaries: (i) summary sections, identified by semantic similarity to typical summary headings; and (ii) A fallback to use centroid distance of clustered sentence vectors to identify salient sentences. Using open source code and open models, this process was able to complete within 3 days, running on a laptop, processing 2,743 evaluation reports at a total cost of $9.51. The generated summaries capture document key concepts well, but more work would be needed to collaborate with the humanitarian evaluation community to produce test datasets to tune LLM prompts and configurations for best performance.
Humanitarian Evaluation Reports
In humanitarian response, evaluation reports examine the relevance, effectiveness, efficiency, impact, and sustainability of humanitarian programs or interventions, typically those responding to crises such as conflicts, natural disasters, food insecurity, or refugee emergencies. They are a cornerstone of accountability and learning in the humanitarian system, used by organizations like the United Nations (UN), as well as non-governmental organizations (NGOs) and donor agencies, to improve future responses and demonstrate results.
In an era of advanced document processing powered by Artificial Intelligence (AI), evaluation reports represent an invaluable source of knowledge. The insights they contain can help save and improve lives across humanitarian and development contexts.
United Nations Evaluation Group (UNEG)
The United Nations Evaluation Group (UNEG) is an amazing inter-agency professional network that brings together the evaluation functions of the United Nations system, including the evaluation units of UN departments, specialized agencies, funds, and programmes. Its mission is to promote, strengthen, and advocate for an independent, credible, and useful evaluation function across the UN system in order to support learning, accountability, and decision-making. One of its key roles is facilitating the sharing and aggregation of evaluation reports from across its member agencies, thereby enabling a broader overview of evidence, emerging trends, and good practices within the UN system.
UNEG provides the community with a repository of member evaluation reports from 55 agencies and 7 observers. This wonderful public resource provides a centralized way to access about 15,000 evaluation reports.
Building a Report Corpus for Our Analysis
So that we can explore processing and AI-powered summarization, 2,743 evaluation reports were downloaded (PDF and Word formats) from UNEG, as published between January 2023 and November 2025. The automatic process waited several seconds before each web request to ensure it never added load to the website greater than that of a single human user, so it took about a day to complete.
The end result was PDF and Word files saved into a data folder, plus a metadata spreadsheet with their details (provided below).
Note: The code for this article can be found here. However, in order to be respectful of UNEG website traffic, the download process is not included.
Choosing a Document Processing Toolkit
For this article, we will focus on using open source tools and open LLMs, with emphasis on keeping costs as low as possible.
Well-established frameworks such as Langchain and LlamaIndex provide full ecosystems and community support for a wide range of document ingestion tasks. There is a wide range of PDF parsers — still a challenging task in these heady days of AI — many of which now offer Optical Character Recognition (OCR) capabilities and AI support for processing complex images and tables. Docling, Unstructured, pdfminer, pdfplumber, are all solid choices, especially when combined with enhanced tools for parsing tables, such as Camelot and Tabula. Finally, we now live in a world where LLMs can be used to parse, process images, and summarize.
The choice of processing pipeline tools also depends on a wide range of factors related to organization and use-case:
- What document formats need to be supported: PDF, Word, presentations, audio, video, etc?
- How will the parsed content be used? Can we live with slightly lower fidelity for tables, images, or do we need to take a cost hit for higher quality?
- What capacity does the organization have for custom development and maintaining code?
- Is performance an important factor? Do new reports have to be available immediately, is the corpus very large?
- Does the organization have sufficient hardware for running local LLMs and OCR models?
- Is there already organizational knowledge in using a particular software framework?
The list goes on. No one size fits all with the current state of the field; it all depends.
Requirements
For this article, we will choose our tools based on the following set of requirements:
Licensing Model
- All open source
Parsing
- Ability to extract text in PDFs and Word Documents
- Ability to extract document structure, hierarchical heading detection
- Output to Markdown
- Basic table parsing and no image processing, ie no OCR
Extraction
- Document summarization
Performance
- Ability to process 2,700 documents in a weekend (when I can write blog posts!), on a 2021 Apple M1 Pro Laptop
Cost
- Costs, such as Open LLM inference, should not exceed $20
Future Proofing
The above items cover core requirements for this article, but there will be follow-up articles on other ways we can use AI with this corpus. In preparation for this, we will add a few more requirements:
- Generated markdown should include images, linked to an external folder
- Markdown should also include page numbers and separators for deep linking of citations
- Support for more advanced OCR techniques
Docling and Hugging Face
Having worked with many of the open-source tools and given the requirements above, the following components were chosen:
- Parsing documents and extracting structure and text: Docling
Docling supports a wide range of document formats, as well as advanced OCR capabilities. At the time of writing, one limitation is limited support for extracting document headings structure. There is an enhancement coming soon, but as we shall see below, the interim solution of using the Docling hierarchical post-processor package does a pretty good job.
2. Embedding and Large Language Models: Hugging Face
Hugging Face is the go-to place for open models. For vector embedding, we will use the venerable sentence transformers, specifically all-MiniLM-L6-v2 downloaded locally. There are way more sophisticated embedding models out there, but this simple choice will suffice for this article.
For the LLM used as part of summarization, because we want to run the pipeline on a laptop, we won't run models locally. Instead, we will use Hugging Face inference providers and call a hosted model via APIs. The still provides access to open models, but mitigates the need for significant compute capacity. A Huggingface Pro account (costing $9 a month) provides $2 of free inference and higher API calling limits, sufficient for this article. It should be noted that we could also use a free Hugging Face account, but due to lower limits, the processing would need more than a weekend to process 2,700 documents.
The pipeline was tested (and supports) Mistral-7B-Instruct-v0.2 and Bart-Large-CNN as well as a range of other models provided on Hugging Face, but we will use Meta's open Llama 3.1 8 Billion parameter LLM due to its multilingual support, large context window, fast performance, and relatively low cost.
Note: You will need to initially submit a request in Hugging Face to be able to use the Llama models on their model page.
Methods for Summarization
Once documents are converted to markdown with headings, they need to be summarized. If using commercial models that support a very large number of input tokens (at significant cost), reports could be summarized simply by uploading the document in full, or in one or two pieces, to the LLM. However, for this article, we need to keep costs down, and using large context windows like this may not provide the best performance.
So how can we summarize a document without using all of its text?
There are two main types of summarization: (i) extractive, which is salient text extracted verbatim from the source document; (ii) abstractive, where a model has taken text input and generated an easy-to-read summary. One way to avoid feeding the whole document to an LLM is to first create an extractive summary, then use that as input for the abstractive LLM summary (a hybrid summary strategy).
Extractive summaries from document summary sections
Some of the best extractive summaries to use are those created by the (human) authors, as captured in sections such as executive summaries, conclusions, and findings. These should include the key concepts of a document, providing text that can be distilled into abstracts (and in some cases might be abstracts).
Side Note: In an ideal world, these would suffice for our corpus document summaries, but due to differing standards, writing styles, and document types, it's still useful to pass these sections to an LLM so consistent summaries can be generated across the whole corpus.
There is a catch, though; not all reports have the same section heading titles, so it's not always easy to automatically identify which sections are 'Summary' sections. They can even be in different languages for humanitarian evaluation reports. Maintaining a hard-coded list of titles would be brittle and a lot of work.
To get around this, we will use the vector embedding model to (i) calculate the vector for each heading in the document; (ii) calculate the vector for a set of phrases like 'Summary' and 'Conclusion', then, using these two sets of vectors, identify the headings that are most similar to the summary-like phrases. Basically, building a mini search engine to search for the titles of sections we hope will have summary content.
Extractive summaries using embedding centroid distance
But what if we can't determine the document heading structure?
A small number of evaluation reports are saved in such a way that automatic extraction of hierarchical headings isn't possible with fast and inexpensive techniques. We could use more powerful LLMs, but keeping with our goal of a low-cost pipeline, we will use another trick. First, we split the whole document into sentences, and then we calculate the embedding vector for each sentence. If we cluster these sentence vectors, there is an average center, called a centroid. If we then take the 30 closest sentences to this centroid, we should capture salient sentences for the document, which can then be used for the LLM summary. This centroid-based extractive summary technique has been around for some time and may not be as sophisticated as other techniques, but it offers a simple, less accurate fallback for the small number of documents where document structure isn't parsed well.
Using MapReduce to limit LLM inputs
If, after distilling documents into extractive summaries, there is still too much text for the LLM to process?
In this scenario, we will apply a trick called MapReduce. This breaks the document into chunks, calling an LLM for each chunk to generate a set of summaries. These summaries are themselves combined. If the length of the combined content is still too long, the process is repeated until eventually there is a single summary of summaries.
Summarization Prompt(s)
This article is focused on generating easily readable abstracts, but future articles will explore how we can automatically identify topics and themes in the corpus. To try and avoid having to reprocess, we will therefore create prompts that address both the summarization requirement, as well as attempt to extract information that might be pertinent to taxonomy discovery.
On experimenting with the full process, it also emerged that using the prompt for creating the final summary may not be appropriate for summarizing interim chunks of text as part of the MapReduce process. Instead, the two simple prompts were used:
Chunk summarization prompt
You are an expert research summarizer. Summarize the following text with a focus on identifying its key *concepts*, *methods*, *findings*, and *terminology*.
Organize your output as a structured summary to support taxonomy development. Capture recurring or novel terms, thematic groupings, and conceptual relationships.
Include both positive and negative findings or limitations. Do not assume overall success unless explicitly supported.
Only include findings or claims explicitly stated in the source text. Do not infer new themes.
TEXT: <<< {document_text} >>>
OUTPUT FORMAT: - **Summary:** [2–3 paragraph summary of the report] - **Main Topics:** [List key subjects, domains, or disciplines covered, with brief descriptions] - **Key Terms & Concepts:** [Extract important domain-specific terminology and emerging phrases, with brief definitions] - **Methods / Approach:** [Summarize methods, frameworks, or analytical strategies mentioned, with brief descriptions] - **Findings / Conclusions:** [Summarize main insights or takeaways, with brief descriptions] - **Related Concepts / Themes:** [List secondary ideas, linked concepts, or cross-cutting themes, with brief descriptions]
Final Summarization prompt
You are a research analyst consolidating multiple structured summaries into a comprehensive overview.
Your task is to write a report synopsis, identify overarching themes, recurring terminology, and
conceptual groupings to support taxonomy or ontology creation.
Include both positive and negative findings or limitations. Do not assume overall success unless explicitly supported.
Only include findings or claims explicitly stated in the source text. Do not infer new themes.
Here are the interim summaries:
<<< {map_summaries} >>>
YOU MUST ADHERE TO THE EXACT FORMAT and TITLES:
- **Title:** [title of the report]
- **Summary:** [2–3 paragraph summary of the report]
- **Report Summary:** [2–3 paragraph summary of the report]
- **Topics:** [Summarize the main thematic clusters emerging across documents, with brief descriptions]
- **Core Concepts and Terms:** [List and briefly define the most important recurring or novel terms, with brief definitions]
- **Methodological Patterns:** [Summarize common approaches or frameworks across sources, with brief descriptions]
- **Key Conclusions:** [Highlight consensus findings and important divergences, with brief descriptions]
- **Emergent Taxonomy Proposal:** [Organize related terms or ideas hierarchically; e.g. Category → Subcategory → Concept, with brief descriptions]
- **Notable Gaps or Contradictions:** [Mention where the data diverges or lacks clarity, with brief descriptions]
These are by no means perfect and quick first passes for this article. If this pipeline is deployed in a production setting, evaluation and tuning with the target audience would need to be carried out to ensure the best performance.
Processing Metrics
The pipeline uses a simple Excel metadata sheet to list documents and to capture parsing status, table of contents for each document, and the AI-generated summaries (see here). Using this data, we can analyze how the pipeline processed our documents …
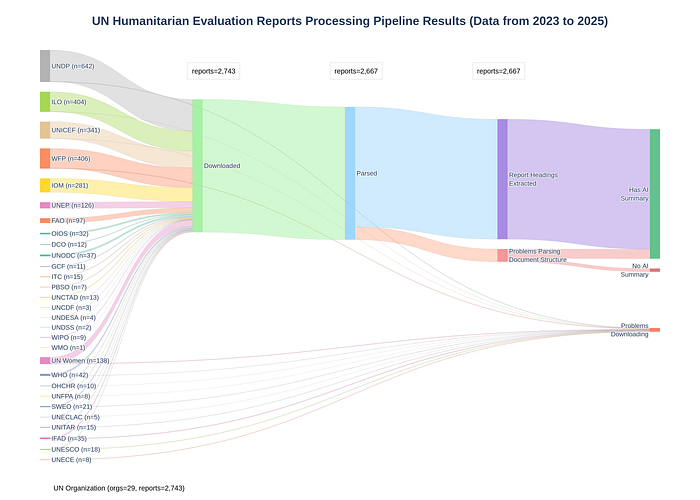
As we can see, the majority of the evaluation reports seem to have processed successfully. A small number of reports listed by UNEG were challenging to download as there was no PDF or Word document. Others were saved in such a way that automatic heading structures were difficult to extract with low-cost, fast techniques.
We expect issues like this with volume. At the end of this article, we provide some recommendations for organizations to help make evaluation reports more easily accessible for use in AI systems.
Results
You can find a spreadsheet of the full pipeline results for UNEG documents published since 2023 here.
Taking the first United Nations Development Cooperation Office (DCO) document "Evaluation of the Government of Seychelles & United Nations Strategic Partnership Framework (SPF) 2019–2023", the pipeline generated a table of contents …
[H2] Evaluation of the Government of Seychelles & United Nations Strategic Partnershi | page 1
[H3] DISCLAIMER | page 2
[H3] ACKNOWLEDGEMENTS | page 3
[H4] Table of Contents | page 4
[H4] LIST OF ACRONYMS | page 6
[H4] EXECUTIVE SUMMARY | page 9
[H4] SUMMARY OF KEY FINDINGS | page 9
[H5] LESSONS LEARNT | page 10
[H5] RECOMMENDATIONS | page 11
[H6] RELEVANCE AND ADAPTABILITY | page 11
[H5] COHERENCE | page 11
[H5] EFFECTIVENESS | page 12
[H5] EFFICIENCY | page 12
[H5] Coordination | page 12
[H5] PART I: INTRODUCTION, COUNTRY CONTEXT AND METHODOLOGY | page 13
[H5] 1 INTRODUCTION | page 13
[H5] 1.1 Background | page 13
[H5] 1.2 Purpose and Objectives of the Seychelles SPF Evaluation | page 13
[H5] Objectives of the Evaluation: The evaluation was anchored around three main obje | page 13
[H5] 1.3 Scope of the Evaluation | page 13
[H5] 1.4 Structure of Evaluation Report | page 14
[H5] 2 COUNTRY CONTEXT | page 15
[H3] Seychelles SYC GDP per capita (current US$) 1960-2020 | page 18
[H4] Table 2: SPF Stakeholders | page 21
[H4] 3 METHODOLOGICAL APPROACH | page 23
[H4] PART II: EVALUATION FINDINGS | page 25
[H4] 4 RELEVANCE AND ADAPTABILITY | page 25
[H4] 4.1 Relevance | page 25
[H5] The Seychelles SPF was strongly aligned to the national development pr | page 25
[H4] 4.2 Adaptability | page 26
[H5] UN Response to COVID-19 Pandemic | page 27
[H5] 5 COHERENCE | page 30
[H5] 6 EFFECTIVENESS | page 32
[H5] EQ 1: To what extent were planned SPF results achieved (What were the facilitati | page 32
[H5] 6.1 The Blue Economy | page 32
[H5] Key: Indicator Performance Rating: | page 33
[H6] Overall Performance of SDGs for Outcome 1 | page 36
[H4] 6.2 Agriculture, Livelihoods, Food and Nutrition Security | page 36
[H5] Overall Performance of SDGs for Outcome 1 | page 39
[H5] 6.3 Environmental Sustainability, Climate Change Mitigation, and Resilience | page 40
[H5] Overall Performance of SDGs for Outcome 3 | page 44
[H5] 6.4 Human Capital Development and Quality of Life | page 45
[H5] (disaggregated by sex, gender and | page 46
[H5] Overall Performance of SDGs for Outcome 4 | page 50
[H5] 6.5 Data Development and, Science, Technology and Innovation Development | page 50
[H5] 5(g). Level of demand and supply driven science, technology and innovation uptak | page 53
[H5] 7 EFFICIENCY | page 55
[H5] EQ 1: How efficiently were resources of the SPF used in the implementation of th | page 55
[H5] 7.1 Operations Management Team (OMT) | page 55
[H5] 7.2 Delivering as One (DaO) | page 55
[H4] 7.3 UNCT SWAP- Scorecard for Gender Mainstreaming | page 56
[H4] 7.4 Integration of Gender and Human Rights | page 57
[H4] 7.5 Other Normative Frameworks for Efficiency | page 57
[H5] 8 COORDINATION | page 59
[H4] 8.1 Adequacy and Effectiveness of SPF Structures | page 59
[H4] 8.2 Management Accountability Framework (MAF) | page 59
[H5] 9 LESSONS LEARNED | page 61
[H5] 10 CONCLUSIONS & RECOMMENDATIONS | page 62
[H4] 10.1 Conclusions | page 62
[H5] Effectiveness: Performance of Planned results for the 5 Outcomes : | page 62
[H4] 10.2 Recommendations | page 65
[H5] RELEVANCE AND ADAPTABILITY | page 65"This aligns perfectly with the PDF Report, though the heading levels seem off by 1 (something to be fixed in future work).
The AI-generated summary …
**Summary:**
This report evaluates the Government of Seychelles and United Nations
Strategic Partnership Framework (SPF) 2019-2023. The evaluation aimed
to assess the SPF's contributions to Seychelles' development priorities,
identify gaps and lessons, and provide recommendations for the next SPF
cycle. The report highlights the SPF's alignment with national development
priorities and SDGs, as well as its effectiveness in implementing
programming principles and adapting to the COVID-19 pandemic. However,
the report also notes challenges, including inadequate data and high
government official turnover, which hindered the SPF's implementation.
**Main Topics:**
1. **Evaluation of the Seychelles SPF 2019-2023**: The report evaluates the
SPF's relevance, effectiveness, and adaptability in the context of
Seychelles' development priorities and SDGs.
2. **Methodology**: The evaluation was conducted in line with the
UN Evaluation Group (UNEG) Norms and Standards for Evaluation (2021)
guidelines.
3. **Seychelles' Development Priorities**: The report highlights
Seychelles' national development priorities, including economic
transformation, environmental sustainability, human capital development, and science, technology, and innovation development.
4. **SDGs and International Obligations**: The report emphasizes the
importance of aligning the SPF with SDGs and international obligations,
such as the African Union Agenda 2063.
**Key Terms & Concepts:**
1. **Strategic Partnership Framework (SPF)**: A framework for cooperation
between the Government of Seychelles and the United Nations.
2. **SDGs (Sustainable Development Goals)**: A set of 17 goals adopted by
the United Nations to achieve sustainable development.
3. **UN Common Country Analysis (CCA)**: A report that provides an
analysis of a country's development priorities and challenges.
4. **LNOB (Leave No One Behind)**: A principle that emphasizes the
importance of inclusivity and leaving no one behind in development efforts.
5. **GEWE (Gender Equality, Women's Empowerment)**: A principle that
emphasizes the importance of promoting gender equality and women's
empowerment in development efforts.
**Methods / Approach:**
1. **Evaluation Framework**: The evaluation was conducted in line with
the UN Evaluation Group (UNEG) Norms and Standards for Evaluation (2021)
guidelines.
2. **Data Analysis**: The report uses data analysis to assess the SPF's
effectiveness and relevance.
3. **Stakeholder Engagement**: The report highlights the importance of
stakeholder engagement in the evaluation process.
**Findings / Conclusions:**
1. **Relevance**: The Seychelles SPF was strongly aligned to national
development priorities and SDGs.
2. **Effectiveness**: The UN in Seychelles successfully implemented the
SPF, adapting to the COVID-19 pandemic.
3. **Challenges**: The report notes challenges, including inadequate
data and high government official turnover, which hindered the SPF's implementation.
4. **Recommendations**: The report provides recommendations for the
next SPF cycle, including the need for more effective data management
and stakeholder engagement.
**Related Concepts / Themes:**
1. **Development Cooperation**: The report highlights the importance of
development cooperation between governments and international organizations.
2. **Institutional Capacity Building**: The report emphasizes the need
for institutional capacity building to support effective development
cooperation.
3. **Data-Driven Decision Making**: The report highlights the importance
of data-driven decision making in development efforts.
4. **Stakeholder Engagement**: The report emphasizes the importance of
stakeholder engagement in development efforts."Seems to do a reasonable job, but as always, caution is needed with LLM initial output. LLMs will LLM!
Let's first try and compare with the overview on the UNEG page …
General Assembly resolution A/RES/72/279 designated the United Nations
Development Assistance Framework (UNDAF), now renamed the United Nations
Sustainable Development Cooperation Framework (CF) as "the most important
instrument for the planning and implementation of United Nations
development activities in each country, in support of the
implementation of the 2030 Agenda for Sustainable Development".
Evaluation of the UNSDCF is a mandatory independent system-wide
country evaluation conducted in the penultimate year of each cycle
to ensure accountability, enhance learning, and guide the development
of the next CF cycle.Interestingly, this seems to be more of a general text on why the report was written. It contains entities such as 'A/RES/72/279' which aren't mentioned in the actual PDF report itself, and doesn't describe its contents in detail.
Let's instead look at the report's executive summary. On the whole, the AI summary does capture the main elements in the document summary. It identifies what is being evaluated — the Seychelles–UN SPF 2019–2023, correctly notes that the evaluation aimed to assess contributions, identify gaps and lessons, and make recommendations. It also accurately mentions alignment with national priorities and SDGs, and adaptation during COVID-19.
However, there are some omissions. For example, the AI summary omits that the SPF had five outcome areas, 78 indicators, and 54 outputs, which are key framing facts in the Executive Summary. It also doesn't mention the timeline for the analysis and various other key factors.
Such is the challenge of summarization: deciding on what to include in the summary.
By its nature, a summary will omit information, so deciding on the required information density and the most important facts is where evaluation and prompt tuning would come in. The next step would be for domain experts to create an evaluation test set of 100 summaries, capturing the key aspects they would like to see represented in each document. Then experiments could be run on these documents, varying prompts, chunk sizes for MapReduce, LLM model and its parameters, all tuned for best performance.
That said, even the quick prompting for this article at least generates reasonable summaries that inform the user as to each report's content.
Cost Analysis
Cost for running the pipeline was as follows:
- Hugging Face Pro, $9 a month
- Hugging Face Inference Costs, $0.51
Since the process ran on my laptop, there is no immediate server costs.
So processing 2,700 documents costs about $9.51, which is pretty inexpensive for a reasonable volume.
Recommendations for Organizations to Make Their Reports AI-Friendly
One outcome of this work has been to identify that a small subset of reports is difficult to parse with inexpensive tools, such that the document structure is preserved. This is a key consideration if those documents are to be used with AI tools. The spreadsheet of results for the UNEG documents provided above can be filtered to identify examples.
Future Work
The work for this article was done over 1–2 days, and as such is a quick analysis. In order to convert the code into production-grade, more work is of course required, mainly working with domain experts in running evaluation experiments to improve prompts and model parameters.
Currently, the code uses a simple Excel spreadsheet to track metadata on reports and processing statistics. This is good for a quick analysis, but it would be better managed in a relational database.
As intimated above, the corpus will be used in the following articles to explore taxonomy discovery and other aspects which may be of relevance ot humanitarian evaluation reports. This will include some new steps in the pipeline. Watch this space!
Resources
The code for this article and pipeline results can be found in Github here.
The processing results for UNEG reports between 2023 and 2025, to include generated summaries, can be found here.