
DDPMs are reported promising results on image generation, image editing, and image inpainting. The self- and cross-attention maps of a well trained DDPM contain rich object information, e.g. object shape and location. Thus, apart from use Diffusion models for object detection like DiffusionDet, the pretrained DDPMs can be directly used to assist object detection and segmentation tasks. This article collects some of the relevant papers.
Generate Datasets
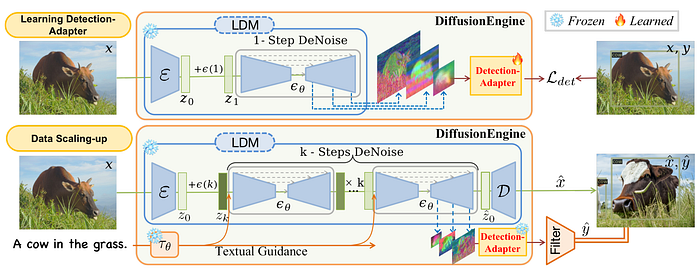
DDPMs can be used for object detection dataset expansion[1]. Pre-trained diffusion model has implicitly learned object-level structure and location-aware semantics, which can be explicitly utilised as the backbone of the object detection task. The generated image are simultaneously labeled with a pretrained detection adaptor.
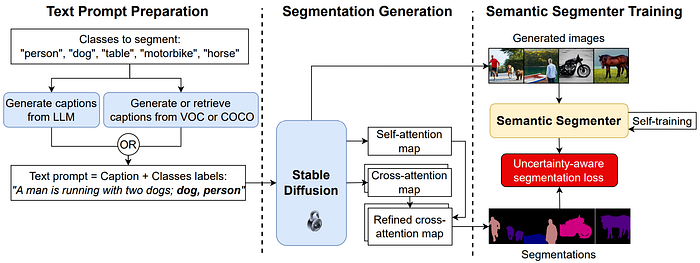
Similarly, Dataset Diffusion [2] proposed to use generated captions to generate images with segmentation labels using stable diffusion model. First stage, the target class labels are collected, the text prompts (captions) are generated with LLM models, e.g. ChatGPT, or from real captions from COCO or VOC datasets. Both caption and class labels are feed the frozen Diffusion model to generate images and corresponding self- and cross-attention maps. The self-attantion map is used to refine the cross attention map to obtain final segmentation labels. Finally, the generated dataset is used to train a segmentation model.
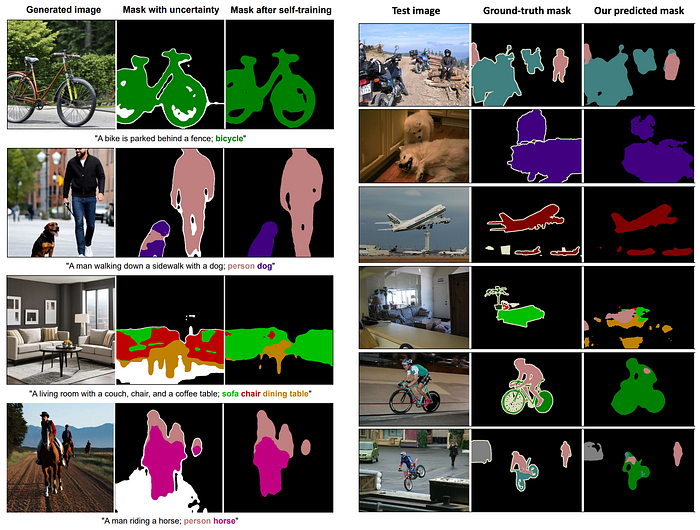
Here are some qualitative results. The refined segmentation label is reasonable but not very precise. for instance, the leg of the the table is missing in the third row. The prediction results are till noisy. This could be used for pretraining to give a good start for target domain tasks.
FreeMask[7] proposed a strategy to use generate images according to segmentation masks, also called mask-to-image synthesis. The checkpoints and generation model is from FreestyleNet[8]. The generated images may be noisy. A filter process based on the mask loss value of the generated images are thresholded to only use the images with relatively low mask loss. A resampling to balance out the difficult mask cases are also applied. The performance comparison between the synthetic datasets and original datasets (ADE20K and COCO) are very similar.

Data Augmentation/Editing
[4] proposed to use Diffusion Models for data augmentation. In order to augment any images with target concepts. The text embeddings are finetuned for generating new concepts which is not included in the existing diffusion model. Specifically, the model's text encoder learn new words to describe new concepts with Textual Inversion (TexInv). Given a target classification dataset, the TexInv learns a word embedding w_i from a handful of labelled images for each class in the dataset.
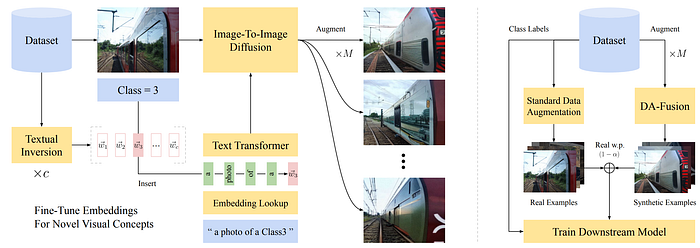
It is challenging to generate images from scratch, thus, real images are used as a guide. Given a reverse diffusion process with T steps, a real image with noise is inserted at time step t_i ∈ [0, 1]. Then the from time step t_i. the fused image are reversing to time step 0 to obtain generated image. Finally, the generated images combined with standard augmented images are used for training the downstream model. This paper also used balanced 50/50 real and synthetic dataset for training. The insertion time step t_i is also randomly chosen.
Shape-Guided Diffusion [5] proposed to use pretrained Diffusion model to edit image with specific mask area and text prompt. The mask shape is kept via constraints to the self and cross-attention maps. Cross-attention layers produce attention maps for textual token and self-attention layer produce attention maps for each pixel. Both self- and cross-attention maps are masked based on the input object mask to maintain the mask shape.

The shape of object mask seems well preserved. But interestingly, the example illustrated in the paper show that sometimes the background could be edited. The sofa pattern in this dog image example is changed.

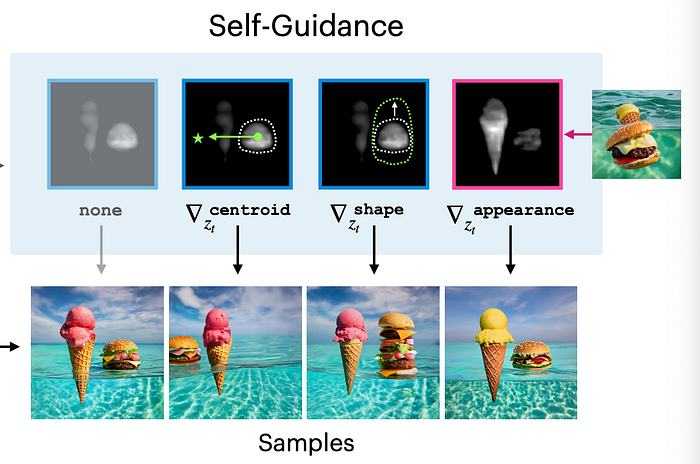
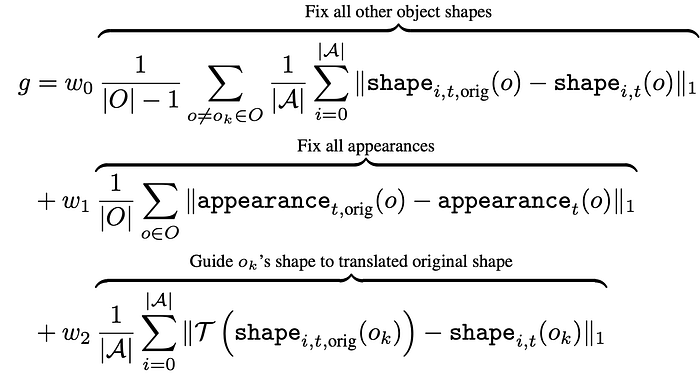
[6] proposed to use self-guidance for image generation. The self and cross-attention maps of pretrained DT encode structural information position and shape about object. This paper try to use the attention maps to produce object center, size and shape constraints for image generation. For instance, the object shape can be obtained through the thresholded attention map. Those constrains are then included in loss function.
- Zhang, Manlin, et al. "Diffusionengine: Diffusion model is scalable data engine for object detection." arXiv preprint arXiv:2309.03893 (2023).
- Nguyen, Quang, et al. "Dataset diffusion: Diffusion-based synthetic data generation for pixel-level semantic segmentation." Advances in Neural Information Processing Systems 36 (2024).
- Graikos, Alexandros, et al. "Diffusion models as plug-and-play priors." Advances in Neural Information Processing Systems 35 (2022): 14715–14728.
- Trabucco, Brandon, et al. "Effective data augmentation with diffusion models." arXiv preprint arXiv:2302.07944 (2023). repo
- Park, Dong Huk, et al. "Shape-guided diffusion with inside-outside attention." Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2024.
- Epstein, Dave, et al. "Diffusion self-guidance for controllable image generation." Advances in Neural Information Processing Systems 36 (2023): 16222–16239.
- Yang, Lihe, et al. "Freemask: Synthetic images with dense annotations make stronger segmentation models." Advances in Neural Information Processing Systems 36 (2024). repo
- Xue, Han, et al. "Freestyle layout-to-image synthesis." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.