


An overfit model is full of surprises but not the good ones.
I have come across several definitions of overfitting. They all point the same meaning with different wordings. My definition is that an overfit model captures unnecessary details, noise, or too specific relationships within a dataset.
Overfitting occurs when a model fails to generalize well to the data. Thus, an overfit model is not very stable and it usually behaves unexpectedly. In general, overfitting results in poor performance on previously unseen data.
Overfitting is a serious problem in machine learning. We can never trust an overfit model and put it into production. It is full of surprises, but not the ones that make you happy. The predictions might change dramatically even if there are very small changes in the feature values.
There are some strong indicators of overfitting. If there is a substantial amount of difference between the accuracies on the training and test set, we are likely to have an overfit model. Another indicator is getting very different results with different test sets.
We need to reduce or eliminate overfitting before deploying a machine learning model. There are several techniques to reduce overfitting. In this article, we will go over 3 commonly used methods.
Cross validation
The most robust method to reduce overfitting is collect more data. The more data we have, the easier it is to explore and model the underlying structure. The methods we will discuss in this article are based on the assumption that it is not possible to collect more data.
Since we cannot get any more data, we should make the most out of what we have. Cross validation is way of doing so.
In a typical machine learning workflow, we split the data into training and test subsets. In some cases, we also put aside a separate set for validation. The model is trained on the training set. Then, its performance is measured on the test set. Thus, we evaluate the model on previously unseen data.
In this scenario, we cannot use a portion of the dataset for training. We are kind of wasting it. Cross validation allows for using every observation in both training and test sets.
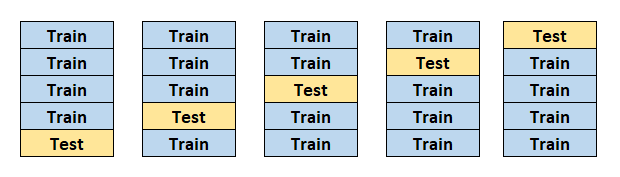
The image above demonstrates a 5-fold cross validation. The dataset is split into 5 pieces. At each iteration, 4 pieces are used for training and the remaining one is used for testing. The entire process is completed after 5 iterations. Each piece is used for both training and testing.
In a sense, cross validation is a way of increasing the amount of training data. The accuracy of the model is calculated as the average of all iterations. As a result, we get a more robust evaluation of the performance of our model.
Regularization
If a model is too complex with respect to the data, it is highly likely to result in overfitting. In the following image, the model is shown with the red line. The blue dots represent the data points.
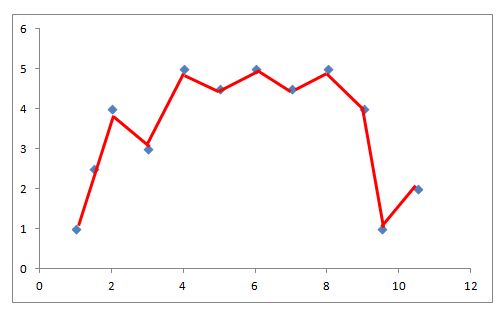
The model tries to capture each and every detail about all the data points. It fails to generalize well to the trend in the dataset.
This model is too complex with respect to the data (blue dots). Hence, we have an overfitting problem. We can solve this problem by reducing the complexity of the model.
Regularization is a method for reducing the complexity. It controls the model complexity by adding a penalty for higher terms. Normally, a model aims to minimize the loss according to the given loss function. If a regularization terms is added, the model tries to minimize both the complexity and loss.
Two commonly used regularization techniques are L1 and L2 regularization. Before explaining how L1 and L2 work, let's first talk about what increases the complexity of a model.
- Total number of features
- The weights of features
L1 regularization handles the complexity due to the total number of features. It acts like a force that substracts a small amount from the weights at each iteration. Thus, some of the weights eventually become zero.
L2 regularization handles the complexity due to the magnitude of feature weights. It acts like a force that removes a small percentage from the weight at each iteration. Thus, the weights decrease but never become zero.
The following demonstrates a more acceptable model for this dataset.

We can also reduce the model complexity by tuning the hyperparameters. Each algorithm has its own hyperparameters. In case of a random forest model, tree depth has a large impact on the model complexity.
Ensemble models
Ensemble models consist of many small (i.e. weak) learners. The overall model tends to be more robust and accurate than the individual ones. The risk of overfitting also decreases when we use ensemble models.
The most commonly used ensemble models are random forest and gradient boosted decision trees. They are a combination of several decision trees.
Let's focus on the random forest. It uses a technique called bagging to put together multiple decision trees. The prediction is calculated by aggregating the predictions of individual decision trees.
Random forest model reduces the risk of overfitting by using uncorrelated decision trees. They are generated by bootstrapping and feature randomness.
Bootstrapping means randomly selecting samples (i.e. data points) from training data with replacement. As a result, each decision tree is trained on a different dataset.
Feature randomness is achieved by randomly selecting a subset of features for each decision tree. Consider the dataset contains 20 features and we randomly select 15 features for each tree. The number of selected features can be controlled by a parameter.
At the end, we have several decision trees that fit on a potentially different sample from the original dataset. We prevent the overall model from focusing too much on a specific feature or set of values. Thus, the risk of overfitting is reduced.
Conclusion
Overfitting is a serious issue in machine learning. It is of crucial importance to solve it before moving forward with our model. I prefer a less accurate model than an overfit model with high accuracy.
There are several techniques to reduce overfitting. We have covered the 3 commonly used ones.
Thank you for reading. Please let me know if you have any feedback.