
Designing scalable and maintainable microservices can be tricky, especially when multiple components need to interact with the same domain. After my last conversation with Rahul, where we explored the challenges of Events or Messages in an Event Driven Architecture (captured in the blog titled "Event-Driven Notifications: A Case for Queues Over Kafka Topics" available here), we found ourselves diving into another architectural puzzle over a cup of coffee.
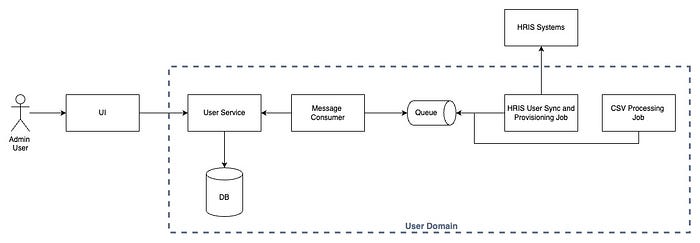
Rahul, who is working on a user microservice, shared a problem that had been keeping him up at night. He mentioned — in his Web based application, admins managed users via a UI, and all user data went into a database after passing business validations. Events were then emitted to Kafka for downstream consumers. But as new use cases emerged — integrating external HRIS systems and supporting bulk user provisioning via CSV — the architecture grew increasingly complex. Jobs and cron jobs were introduced to handle these scenarios, and Rahul was struggling with a crucial design decision —
Should every service (API, jobs, cron jobs) directly write to the user database, or should everything go through a central service?
As we sipped our coffee, we took a step back and analyzed the broader implications of this decision. What would be the impact on maintainability, performance, and system reliability? Would a central API service introduce a bottleneck, or would it help enforce consistency? We broke the problem down into key architectural considerations before diving into possible solutions.

The Case for a Central API Service
1. Data Integrity and Business Logic Enforcement
If each component writes to the database independently, you risk inconsistency. A licensing check, mandatory field validation, or other business rules might be applied differently across services, leading to data corruption. Having a central API service ensures —
- All data passes through the same set of business validations.
- Changes to the user schema don't require modifying multiple services.
- Kafka events are triggered reliably from a single source.

Trade-offs —
- A central API can become a bottleneck if not scaled properly.
- Increased latency compared to direct DB writes.
- If the API fails, all write operations are blocked unless a fallback mechanism is in place.
2. Performance & Scalability Considerations
- If multiple services query and write to the database directly, the load increases. Optimizing performance across multiple components becomes difficult.
- A central service can introduce caching and batching strategies to reduce database pressure.
- Kubernetes scaling policies for async jobs, cron jobs, and API services can be different. Keeping database writes within a controlled API service provides more predictable performance.
Trade-offs —
- API service needs to be highly available and horizontally scalable.
- More infrastructure required to support API-based scaling.
- Additional network hops might introduce minor latency.
3. Decoupling Through Message Queues
Instead of making synchronous API calls, jobs and cron jobs can push data to a queue, and a queue consumer can invoke the central API service. This approach —
- Ensures no data is lost if the API service is down.
- Allows for retry mechanisms and failure handling.
- Prevents jobs from blocking while waiting for the central service.
Trade-offs —
- Requires proper monitoring and alerting for queue failures.
- Increased complexity with queue management.
- Message duplication or out-of-order processing needs to be handled.
Handling Failures & Notifications
Rahul then brought up another concern: failure handling. If the API rejects a request due to a business rule violation, how does an admin get notified?
We explored two options —
Option 1 — Central API Handles Notifications
- The API service logs errors and triggers email notifications.
- Simplifies the jobs by removing error-handling responsibility from them.
Trade-offs —
- API service must handle additional responsibilities beyond validation and DB writes.
- More coupling between API and notification service.
Option 2 — Jobs Handle Notifications
- Jobs push data to the queue.
- The consumer calls the API service and listens for errors.
- If an error occurs, the job picks it up and notifies the admin.
Trade-offs —
- Jobs become more complex and need additional state tracking.
- Higher possibility of missed notifications if not handled correctly.
Which approach is better? If failure tracking and reporting need to be centralized, the API service should handle it. If failures are specific to individual jobs, keeping notifications within jobs might be preferable. However, if errors require human intervention, centralizing failure tracking in the API ensures a single source of truth and makes debugging easier. On the other hand, if errors are transient and can be retried without human intervention, jobs can handle them efficiently with their retry mechanisms.
Who Checks for User Profile Changes?
Rahul then asked another tricky question. Before updating a user's data, we need to check if it has actually changed. Should jobs query the database directly, or should they ask the API service?
We analyzed the trade-offs —
- Jobs Query the Database → Adds direct load to the DB, making optimizations difficult.
- Jobs Ask the API Service → Keeps all business logic centralized, but can increase API load.
- Queue Consumer Does the Validation → Might work well if we want to offload jobs but still keep writes controlled.
Trade-offs —
- More API calls if every job requests data first.
- If the queue consumer handles validation, it needs access to historical data.
- Latency concerns if large amounts of data need to be checked frequently.
- Jobs would push all data to the Queue, increasing the number of messages — including unchanged data — which consumes more network bandwidth and queue storage.
Since the API service is already handling all business logic, it makes sense for it to be responsible for checking if a user's data has changed before updating it. Jobs should push raw data to the queue, and the consumer can take care of the rest.
Microservice or Not?
As we wrapped up our conversation, Rahul asked one final question: With so many jobs and workers running independently, is this still a microservice?
This is where definitions get fuzzy. Traditional microservices are self-contained and have their own database, but in this case —
- The User Service remains a single logical domain.
- It has multiple processes (API, jobs, queue consumers), each scaling independently.
- External systems see this as a single service.
This is more of a modular monolith inside a microservices architecture. While individual services usually have separate databases, user data needs a single source of truth. So, this model makes sense.
The API service, jobs, and cron jobs are all independently deployed and scaled. However, because they all operate on the same domain and share a database, they form a tightly coupled unit within the broader microservices ecosystem. This setup allows independent scaling and deployment while maintaining strong consistency in business rules.
Trade-offs —
- Increased operational complexity due to multiple scaling components.
- Higher interdependency between processes.
- More monitoring required to ensure end-to-end consistency.
Final Thoughts
Rahul leaned back and nodded. "So, what's the least worst approach overall?"
I summarized our discussion —
- Use a Central API Service for all database writes, business validations, and event emissions.
- Introduce a Queue where jobs push data asynchronously, and a consumer calls the API.
- Handle Failures in the API and notify admins instead of making jobs wait.
- Have the API Validate Changes before writing to the DB, reducing redundant updates.
- Scale Components Independently, but maintain them as part of the same microservice domain.
Rahul smiled, picked up his cup, and said, "This makes so much sense! I feel like I finally have a clear direction."
I laughed. "Glad to help. This is what makes distributed systems both challenging and exciting!"
Stay Connected
I hope you found this blog insightful and thought-provoking. If it helped clarify any concepts or inspired new ideas, I'd love for you to share it with your friends and colleagues.
For more content like this, including insights on Microservices, Event-Driven Architecture, Kubernetes, DevOps, and more, follow me here on Medium and connect with me on LinkedIn. Let's continue exploring and solving complex engineering challenges together.
Happy coding, and cheers to building resilient systems!