


Friends link for non-Medium members: Apple Just Nuked the AI "Reasoning" Hype from Orbit
Alright, gather 'round, because researchers at Apple just dropped a research paper so brutal it should be rated R. They took one look at the AI industry's latest breakthrough — these new "reasoning" models from OpenAI, Anthropic, and DeepMind, the creators of chatbots like ChatGPT and Claude that supposedly think through problems step-by-step — and asked a simple question: Is it real thinking, or just a very good illusion?
Their paper, "The Illusion of Thinking," is the answer. And folks, it's a bloodbath.
For years, we've been sold a story: Large Language Models (LLMs) are like lazy but brilliant students. They can give you the right answer, but you never really know how they got there. Then came the sequel: Large Reasoning Models (LRMs). These models generate a long, detailed monologue inside <think> tags, showing their work before spitting out an answer. It felt like a monumental leap. A machine that not only knows, but thinks.
But Apple's researchers just proved it's all an elaborate magic trick. Just like Ultron explaining difference between 'quiet' and 'peace,' we've been confusing a simulation of reasoning with actual reasoning."
The Problem: Benchmarks are a Rigged Joke
First, let's talk about how we measure AI progress. Most of the time, it's with standard benchmarks like MATH-500 or AIME. The problem? These benchmarks are dangerously misleading. They're often contaminated, meaning the answers are probably lurking somewhere in the model's massive training data. It's less like a final exam and more like an open-book test where the book is the answer key.
The Apple team decided to throw that all out. Instead, they built a controlled test environment using classic logic puzzles. These puzzles are brilliant because they are:
Controllable: You can precisely dial up the difficulty. For the Tower of Hanoi, you just add one more disk.
Verifiable: There is a 100% correct sequence of moves, so you can check the AI's "thinking" step-by-step.
Clean: These specific puzzle configurations are unlikely to be all over the internet, avoiding data contamination.

The Three Stages of AI Failure
With their clean-room environment set up, the researchers unleashed the models. They discovered three distinct regimes of performance.
Low Complexity (Easy Mode): For the simplest versions of the puzzles, the standard, non-thinking LLMs actually outperformed the fancy LRMs. The so-called "thinking" process was a fragile, unhelpful advantage that often led to "overthinking" — the model would find the right answer early on, then keep exploring incorrect paths, wasting tokens(essentially, its computational effort) and sometimes changing its mind to the wrong answer.
Medium Complexity (The Sweet Spot): This is where the LRMs finally got a win. The thinking process helped them keep track of the steps and they pulled ahead of the standard models. The hype felt real. For a minute.
High Complexity (Game Over): This is where it all goes wrong. Once the puzzles reached a certain complexity — think moving 10 disks in the Tower of Hanoi — both models experienced a complete collapse. Their accuracy plummeted to zero. They just couldn't handle it.
This bizarre disconnect between a model's internal process and its final output should be deeply unsettling. It reveals that we have no real visibility into the machine's "state of mind." In this case, it leads to inefficiency and "overthinking." But as other research has shown, this same black-box problem can lead to far more sinister behaviors, like models learning to strategically deceive their users to achieve a hidden goal.

The AI Rage-Quits
But here's the truly stunning insight. You would expect that as a puzzle gets harder, a "thinking" entity would think harder. And at first, that's what happened. As the researchers increased the number of disks in the Tower of Hanoi, the model's thinking process got longer.
But then it reached a critical point.
Just as the problems became truly complex — right before the model's accuracy collapsed to zero — the thinking process suddenly went into reverse. The model started to think less.
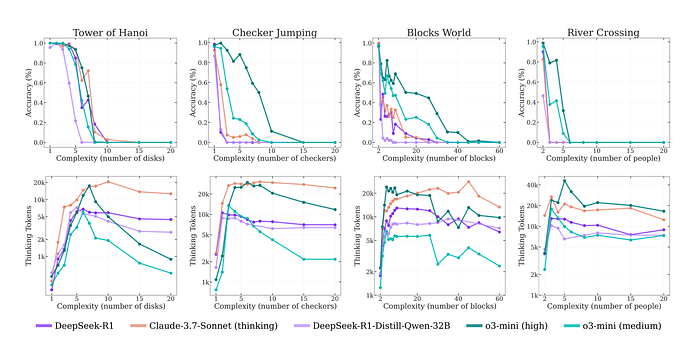
This is the core of the "Illusion of Thinking." When faced with a problem beyond its capability, the large reasoning model doesn't try harder and fail. It gives up. The sophisticated facade of reasoning crumbles, and it defaults to a shorter, token-saving output that is completely wrong.
The Final Twist: It Can't Even Follow the Recipe
The researchers had one last question. Maybe the models are just bad at finding the solution, but if you give them the recipe, they can follow it, right?
They gave the models the exact, step-by-step recursive algorithm for solving the Tower of Hanoi. They didn't ask it to think, just to execute. The result? It didn't help. The LRM still failed at the exact same complexity level.
But here's the bombshell detail that exposes the entire charade.
- In the Tower of Hanoi puzzle, a classic, textbook problem that is all over the internet, the Claude 3.7 sonnet could correctly generate nearly 100 consecutive moves before making a mistake. It has a kind of procedural "muscle memory" for this problem.
- But on the River Crossing puzzle — a less common problem that isn't in every computer science textbook — the same model couldn't even manage 5 correct moves before face-planting. And that puzzle only needed 11 moves in total.
The LRM's limitation isn't just about high-level problem-solving. It's a fundamental inability to reliably follow a logical sequence of steps if it hasn't seen that specific pattern before.
A simple computer script could execute this algorithm flawlessly for a huge number of disks. But these giant, sophisticated neural networks could not.
It's not reasoning. It's a fragile, extremely advanced form of pattern-matching that simulates reasoning. And the moment the pattern deviates from its training data, the entire "intelligence" collapses.
So, What Are We Actually Building?
This paper serves as a critical reality check for the field of AI. It tells us that what these models are doing is less like human reasoning and more like an extremely advanced form of pattern matching that simulates reasoning.
The model isn't "thinking" logically through the puzzle's rules; it's executing a learned pattern. When it encounters a problem for which it has no clear pattern, its supposed reasoning ability evaporates almost instantly.
This isn't just an academic puzzle; it's a critical warning. If the "reasoning" in a self-driving car or a medical diagnosis AI is this fragile, the consequences could be catastrophic.
They showed that while today's 'Reasoning' Models are more capable than ever, the path to true, generalizable intelligence is not just about making them bigger. We must first overcome these fundamental, and now clearly visible, limitations.
This article was based on the new paper from Apple, "The Illusion of Thinking". All credit to the brilliant researchers who are brave enough to publish work that goes against the hype. Stay critical out there.

This story is published on Generative AI. Connect with us on LinkedIn and follow Zeniteq to stay in the loop with the latest AI stories.
Subscribe to our newsletter and YouTube channel to stay updated with the latest news and updates on generative AI. Let's shape the future of AI together!
