


RAG OPTIMISATION
In the ever-advancing world of AI, Generative AI models like ChatGPT, Claude, and Gemini are revolutionizing industries with their vast knowledge and reasoning prowess. Yet, their deployment in specialized sectors can be challenging.
Integrating specific industry data with these applications helps mitigating model inaccuracies and enhance control, making them dependable tools for any industry. That's why RAG Framework is all rage currently. However, developing these integrated applications is very challenging. From creating data pipelines to leveraging AI reasoning capabilities, developers face a complex puzzle. That's why many organisations that invested a lot in genAI initiatives in 2024 and tried POCs were are not able to move those to Production.
By acknowledging these complexities and continually improving, we can create applications that exceed expectations, ensuring trust and reliability in AI. Dive into this blog to explore how data-integrated LLMs like RAG can be optimised for complex queries and understand how it would use the data available to it at the best.
Understand the complexity of your User query
It's helpful to categorize RAG application queries based on their complexity and the depth of data interaction required. This categorization provides insight into the different levels of cognitive processing that LLMs must perform to generate accurate responses. These levels include explicit facts, implicit facts, interpretable rationales, and hidden rationales.
Level-1 Explicit Facts: These queries request explicit facts that are directly available in the provided data.
Level-2 Implicit Facts: These queries necessitate a degree of common sense reasoning or basic logical deductions to unearth implicit facts.
Level-3: Interpretable Rationales: These queries require more than just factual knowledge. They call for an understanding of domain-specific reasoning and the ability to apply it effectively within the given context.
For instance, in the pharmaceutical industry, an LLM must be able to interpret FDA guidance documents outlining the regulatory requirements for drug applications. In customer support, the model needs to follow structured workflows to process inquiries while complying with predefined protocols. In healthcare, diagnostic manuals, such as those guiding the management of acute chest pain, provide clear procedural steps and decision trees for specific conditions. By leveraging these external rationales, specialized LLM systems can serve as expert advisors in evaluating regulatory compliance, assisting customers, or managing medical conditions.
Level-4: Hidden Rationales: This level presents a more complex challenge. It involves queries where the rationale isn't explicitly documented but must be inferred from patterns and outcomes in external data. Hidden rationales entail implicit reasoning chains, logical relationships, and the challenging task of identifying and extracting the reasoning needed for each query.
For example, in IT operations, a cloud team might have managed numerous incidents, each with unique circumstances and resolutions. An LLM would need to mine this tacit knowledge, recognizing patterns in how past incidents were resolved. Similarly, in software development, debugging histories often contain implicit insights, even though the decision-making process isn't systematically recorded.
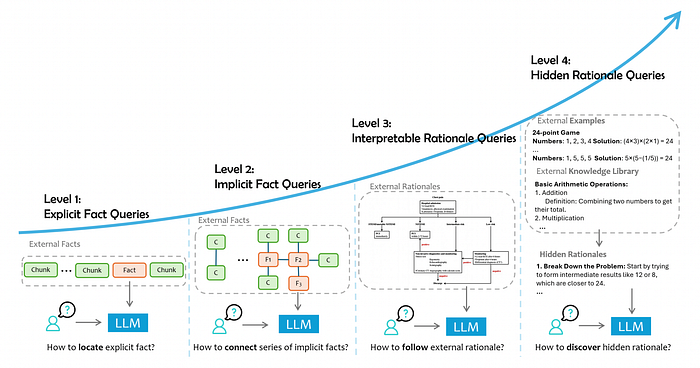
The categorization of queries into levels reflects the complexity and type of understanding required from the LLM. The first two levels focus on retrieving factual information, while the latter two levels necessitate deeper cognitive engagement and the ability to align with expert thinking or extract wisdom from unstructured data. Each level presents its own set of challenges and requires tailored solutions for effective handling. Delving into these levels will illuminate the current capabilities of LLMs and hint at potential future advancements in the field.
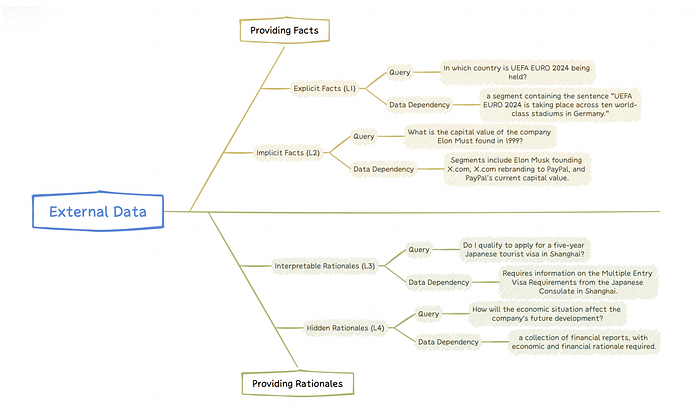
In my last blog post, I delved into the intricacies of Level 1 and Level 2 query types, exploring the optimization strategies for each category with practical examples.
You can check out that post below.
In this post, we're going to shift our focus towards Level 3 query types, discussing the best optimization strategies for each category and providing real-world implementation examples.
Interpretable Rationale Queries (L3)
These queries require the use of external data to provide logical explanations for their answers. They not only require a strong understanding of factual content but also require the ability to understand and apply specific logic relevant to the context of the data.
Examples of queries: • How should a patient with chest pain and specific symptom descriptions be diagnosed and treated? (given a chest pain management guideline) • How to respond to a user's question in a real-life scenario? (given a customer service workflow)
What type of External data are needed to answer Interpretable Rationale Queries?
Interpretable rationale queries are relatively straightforward and depend on external data to provide logical explanations. The support data for these queries often provide clear explanations of the thought processes used to solve problems. This data can be presented in various forms:
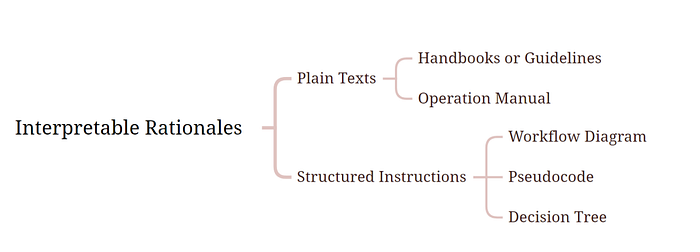
Plain Texts:
These are often textual descriptions that provide interpretable rationales. They may include specialized documents like handbooks or guidelines, or domain-specific manuals. These texts describe the reasoning processes used for decision-making in complex situations.
For example, FDA Guidance documents for pharmaceutical factories or medication guides for physicians offer insights into how experts, like FDA officers or doctors, handle specific cases.
Structured Instructions:
These provide more explicit reasoning relationships or decision paths in a structured format. The logic can be understood as either a Text-Conditioned Moore Machine or a Text Conditioned Mealy Machine.
In computational theory, a Moore machine is a finite-state machine where the output values are determined solely by its current state. The conditions that control state transitions are often expressed in text, which language models need to interpret.
For example, a customer support agent may use a handbook to handle a user's request for product changes or refunds. A Mealy machine is a finite-state machine where output values are determined by both its current state and the inputs. The difference here is that actions are determined not only by the state but also by the text messages associated with transitions from the previous state. These domain-specific rationales can be represented in formats such as workflows, decision trees, or pseudocode.
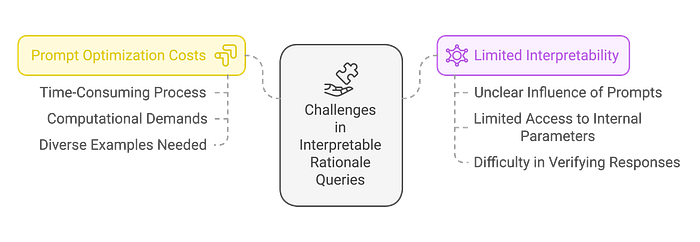
Challenges in Dealing with Interpretable Rationale Queries
The challenge in dealing with interpretable rationale queries lies in incorporating domain-specific logic into language models in a way that is easy to understand. The main challenges are:
Prompt Optimization Costs:
The process of optimizing prompts is time-consuming and computationally demanding. Different queries require different background knowledge and decision-making criteria, requiring diverse examples. While manually designed prompts can be very effective, they are labor-intensive and time-consuming. Also, training models to generate tailored prompts for various queries requires significant computational resources.
Limited interpretability:
The influence of prompts on language models is often unclear. In many instances, access to the internal parameters of language models is typically limited, making it difficult to determine the impact of different prompts on these models. This lack of transparency makes it hard to consistently understand and verify the interpretability of language model responses to different prompts.
Handling Interpretable Rationale Queries:
Solution 1: Prompt Tuning
What is Prompt Tuning?
Prompt tuning enhances the capabilities of large language models (LLMs) by employing soft prompts — adjustable vectors that are optimized and integrated alongside input text to guide the model's responses.
This approach maintains the model's pre-existing parameters in a frozen state, leveraging the pre-trained knowledge without altering the core architecture. Soft prompts are dynamic and continuously optimized during training to align the model's output with specific task objectives.
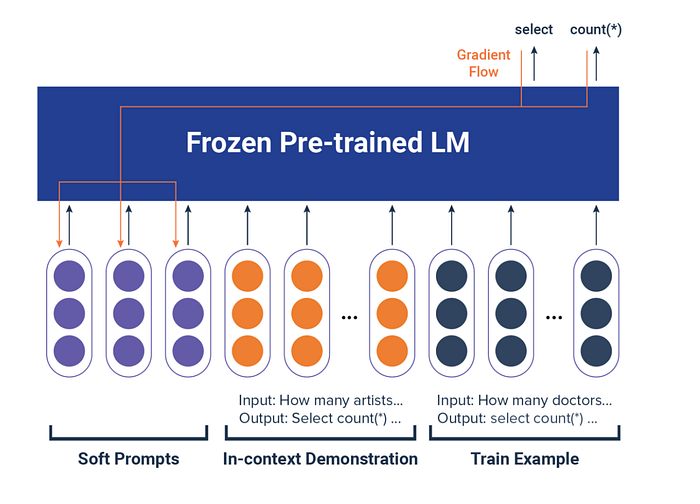
Key components in prompt tuning include:
- In-context demonstration: This involves providing the LLM with examples that show the expected input-output format. For instance, a soft prompt for a SQL query might include a counting question paired with its SQL command, teaching the model the desired response format.
- Train examples: These are broader and cover various scenarios, helping the model generalize across different contexts.
- Verbalizers: These act as translators between the model's outputs and task-specific categories, ensuring precise alignment. For example, a verbalizer in sentiment analysis would categorize the output "happy" as a positive sentiment.
Implementation:
A good implementation example of prompt tuning in RAG is available in the Github link below.
Some Implementations of Prompt Tuning from research:
Extracting Decision Trees for Clarity
Text2MDT[2] has introduced methods to extract medical decision trees from medical guidelines and textbooks automatically. This process helps to distill the logical chains within lengthy medical texts, making them more understandable and manageable for LLMs. MedDM[3] has followed a similar path, developing a format for clinical guidance trees that LLMs can execute. They've proposed a methodology for reasoning based on these guidance trees and a framework for multi-turn dialogues between patients and LLMs.
Enhancing Recommendation Systems
InstructRec[4] aims to harness the capabilities of LLMs in recommendation systems. They've designed a universal format to describe a user's preferences, intentions, task forms, and context in natural language. This innovation results in a high-performing, language-based recommendation system.
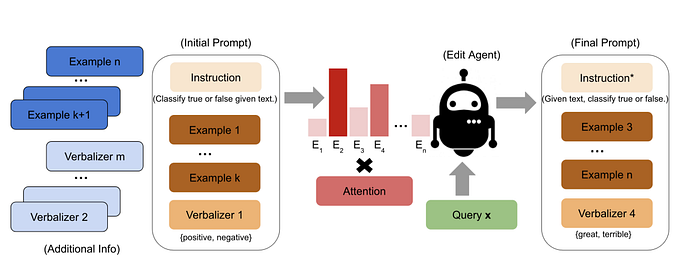
Reinforcement Learning for Prompt Tuning
One effective approach involves the application of reinforcement learning. The TEMPERA[5] framework exemplifies this strategy, designing prompts that incorporate limited instructions, examples, and verbalizers within the action space of reinforcement learning. The LLM's probability of generating correct responses serves as the reward, guiding the model to discover the optimal prompt configuration across datasets.
Directional Stimulus Prompting
Another innovative strategy is Directional Stimulus Prompting. This method leverages the performance of LLMs on downstream tasks as a reward mechanism. It trains models to extract and utilize directional stimuli which are specific cues or keywords tailored to individual instance as prompts. This ensures the LLMs' actions align more closely with expected outcomes.
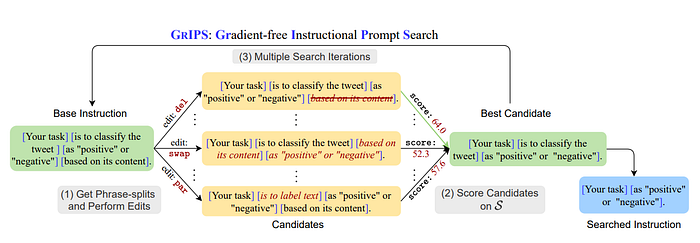
Edit-based Methodologies for Optimization
For optimization within discrete prompt spaces, edit-based methodologies such as GrIPS[6] are utilized. This technique involves using a small dataset as a scoring set to experiment with various prompt modifications including deletions, swaps, paraphrases, and additions to ascertain the most effective prompt configurations swiftly and effectively.
Using LLMs for Prompt Optimization
Recent advancements have also seen the rise of using LLMs themselves to facilitate prompt optimization. OPRO[7] employs an LLM both to generate new prompt solutions based on historical data and their associated performance metrics and to score these prompts. This streamlines the optimization process.

In another innovative approach, the Reflexion framework introduces a novel prompt optimization strategy based on linguistic feedback. It uses a language model to analyze and store reflections on LLM outputs in an episodic memory buffer. This memory component aids in refining decision-making processes and evaluating outcomes in future interactions, leveraging accumulated historical insights.
Solution 2: Chain-of-Thoughts Prompting
Addressing complex rationales often requires LLMs to engage in extended chains of reasoning, a process that differs significantly from the reasoning across disparate factual information typical of fact queries. However, methodologies such as Chain-of-Thoughts (CoT), Tree-of-Thoughts, or Graph-of-Thoughts have proven effective in these scenarios.
What is Chain of Thought Prompting?
Chain of thought prompting is an AI technique designed to mimic how humans think by breaking down complex tasks into a series of logical steps.
Instead of just finding the answer, this method also has the model explain the reasoning process it used to get there.
This differs from the usual approach where the focus is solely on the final answer. With chain of thought prompting, the AI is guided to reveal its thought process, leading to more accurate and understandable results.
The image below compares a typical few-shot prompt (left) with a chain of thought prompt (right). While the standard prompt goes straight to the answer, the chain of thought prompt encourages the AI to lay out its reasoning step by step, making the outcome more reliable and interpretable.
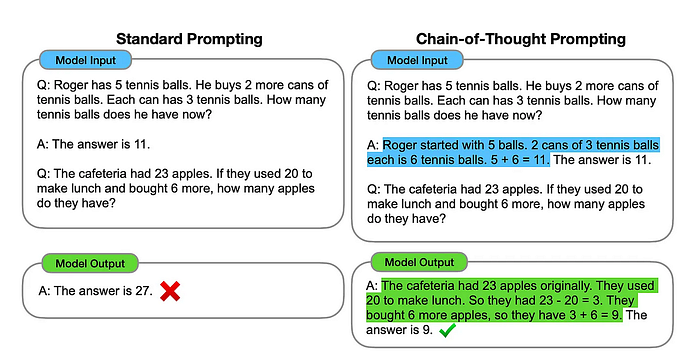
Manually Designing CoT Prompts
For issues that are well-studied and have high general applicability, manually designing CoT prompts can be a viable solution. For instance, a method of self-reflection proposed by Ji et al. (2023)[8] integrates knowledge acquisition with answer generation. By using external tools and designing prompts, they created three types of self-reflection loops: the Factual Knowledge Acquiring Loop, the Knowledge-Consistent Answering Loop, and the Question-Entailment Answering Loop. This approach effectively incorporates external rationales into the model's processing.

In another example, Wu et al. (2024)[9] conducted a manual analysis of error types in clinical records and developed three distinct CoT prompts to guide the GPT-4 model. These prompts focus on intervention, diagnostic, and management errors, facilitating automatic error detection, span identification, and correction within clinical records.
While manual design of CoT prompts can be highly effective, it requires substantial human and temporal resources. To mitigate these costs, Automate-CoT[10] proposed a technique for generating augmenting rational chains from a minimally labeled dataset. This approach employs a variance-reduced policy gradient strategy to evaluate the importance of each CoT chain, thus facilitating the selection of the most effective prompt combination.
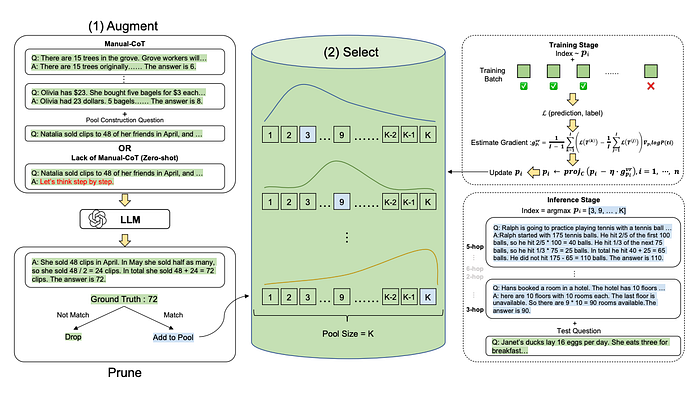
Building Agent Workflows Around LLMs
Another form of utilizing Chain of Thoughts prompting involves constructing an agent workflow centered around LLMs. This typically requires the development of a more comprehensive system to address various real-world scenarios. Such systems can be broadly divided into profiling, memory, planning, and action modules. Interpretable rationales can be integrated into multiple modules in various forms, allowing the agent to adapt and iterate based on environmental or human feedback.
Recent advancements, such as those by LLM Reasoners and SocREval[11], have focused on automatically evaluating the quality of reasoning chains. These methodologies also assist in constructing robust data augmented LLM applications.
Implementation Examples:
Self RAG:
The SELF-RAG framework trains a single arbitrary language model to adaptively retrieve passages on-demand.
To generate and reflect on retrieved passages and on own generations using special tokens, called reflection tokens. Reflection tokens are categorised into retrieval and critique tokens to indicate the need for retrieval and its generation quality respectively.
SELF-RAG uses reflection tokens to decide the need for retrieval and to self-evaluate generation quality. Generating reflection tokens makes the LM controllable during the inference phase, enabling it to tailor its behaviour to diverse task requirements.
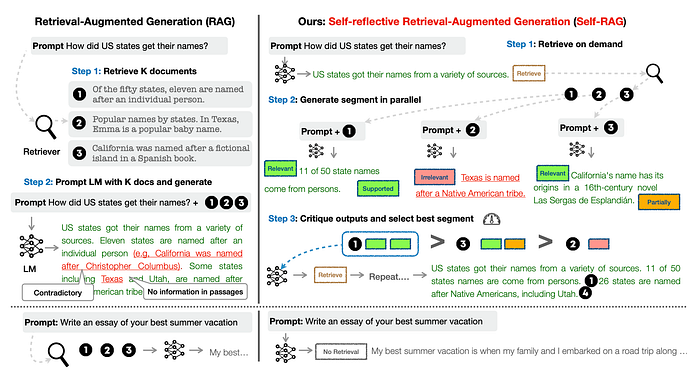
The framework trains an LLM to generate self-reflection tokens that govern various stages in the RAG process. Here is a summary of the tokens:
Retrievetoken decides to retrieveDchunks with inputx (question)ORx (question),y (generation). The output isyes, no, continueISRELtoken decides whether passagesDare relevant toxwith input (x (question),d (chunk)) fordinD. The output isrelevant, irrelevant.
ISSUPtoken decides whether the LLM generation from each chunk inDis relevant to the chunk. The input isx,d,yfordinD. It confirm all of the verification-worthy statements iny (generation)are supported byd. Output isfully supported, partially supported, no support.ISUSEtoken decides whether generation from each chunk inDis a useful response tox. The input isx,yfordinD. Output is{5, 4, 3, 2, 1}.
This table in the paper supplements the above information:

We can outline this as simplified graph to understand the information flow:
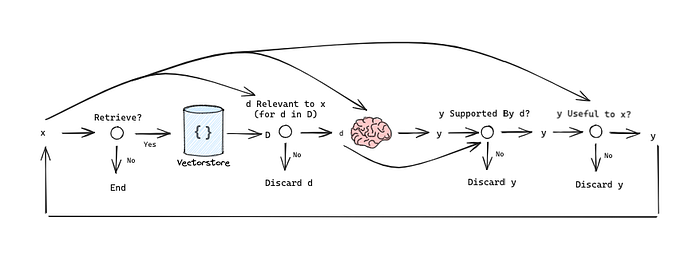
Implementation of Self RAG:
import os
import sys
from dotenv import load_dotenv
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.pydantic_v1 import BaseModel, Field
sys.path.append(os.path.abspath(os.path.join(os.getcwd(), '..'))) # Add the parent directory to the path sicnce we work with notebooks
from helper_functions import *
from evaluation.evalute_rag import *
# Load environment variables from a .env file
load_dotenv()
# Set the OpenAI API key environment variable
os.environ["OPENAI_API_KEY"] = os.getenv('OPENAI_API_KEY')
path = "../data/Understanding_Climate_Change.pdf"
vectorstore = encode_pdf(path)
llm = ChatOpenAI(model="gpt-4o-mini", max_tokens=1000, temperature=0)
class RetrievalResponse(BaseModel):
response: str = Field(..., title="Determines if retrieval is necessary", description="Output only 'Yes' or 'No'.")
retrieval_prompt = PromptTemplate(
input_variables=["query"],
template="Given the query '{query}', determine if retrieval is necessary. Output only 'Yes' or 'No'."
)
class RelevanceResponse(BaseModel):
response: str = Field(..., title="Determines if context is relevant", description="Output only 'Relevant' or 'Irrelevant'.")
relevance_prompt = PromptTemplate(
input_variables=["query", "context"],
template="Given the query '{query}' and the context '{context}', determine if the context is relevant. Output only 'Relevant' or 'Irrelevant'."
)
class GenerationResponse(BaseModel):
response: str = Field(..., title="Generated response", description="The generated response.")
generation_prompt = PromptTemplate(
input_variables=["query", "context"],
template="Given the query '{query}' and the context '{context}', generate a response."
)
class SupportResponse(BaseModel):
response: str = Field(..., title="Determines if response is supported", description="Output 'Fully supported', 'Partially supported', or 'No support'.")
support_prompt = PromptTemplate(
input_variables=["response", "context"],
template="Given the response '{response}' and the context '{context}', determine if the response is supported by the context. Output 'Fully supported', 'Partially supported', or 'No support'."
)
class UtilityResponse(BaseModel):
response: int = Field(..., title="Utility rating", description="Rate the utility of the response from 1 to 5.")
utility_prompt = PromptTemplate(
input_variables=["query", "response"],
template="Given the query '{query}' and the response '{response}', rate the utility of the response from 1 to 5."
)
# Create LLMChains for each step
retrieval_chain = retrieval_prompt | llm.with_structured_output(RetrievalResponse)
relevance_chain = relevance_prompt | llm.with_structured_output(RelevanceResponse)
generation_chain = generation_prompt | llm.with_structured_output(GenerationResponse)
support_chain = support_prompt | llm.with_structured_output(SupportResponse)
utility_chain = utility_prompt | llm.with_structured_output(UtilityResponse)
def self_rag(query, vectorstore, top_k=3):
print(f"\nProcessing query: {query}")
# Step 1: Determine if retrieval is necessary
print("Step 1: Determining if retrieval is necessary...")
input_data = {"query": query}
retrieval_decision = retrieval_chain.invoke(input_data).response.strip().lower()
print(f"Retrieval decision: {retrieval_decision}")
if retrieval_decision == 'yes':
# Step 2: Retrieve relevant documents
print("Step 2: Retrieving relevant documents...")
docs = vectorstore.similarity_search(query, k=top_k)
contexts = [doc.page_content for doc in docs]
print(f"Retrieved {len(contexts)} documents")
# Step 3: Evaluate relevance of retrieved documents
print("Step 3: Evaluating relevance of retrieved documents...")
relevant_contexts = []
for i, context in enumerate(contexts):
input_data = {"query": query, "context": context}
relevance = relevance_chain.invoke(input_data).response.strip().lower()
print(f"Document {i+1} relevance: {relevance}")
if relevance == 'relevant':
relevant_contexts.append(context)
print(f"Number of relevant contexts: {len(relevant_contexts)}")
# If no relevant contexts found, generate without retrieval
if not relevant_contexts:
print("No relevant contexts found. Generating without retrieval...")
input_data = {"query": query, "context": "No relevant context found."}
return generation_chain.invoke(input_data).response
# Step 4: Generate response using relevant contexts
print("Step 4: Generating responses using relevant contexts...")
responses = []
for i, context in enumerate(relevant_contexts):
print(f"Generating response for context {i+1}...")
input_data = {"query": query, "context": context}
response = generation_chain.invoke(input_data).response
# Step 5: Assess support
print(f"Step 5: Assessing support for response {i+1}...")
input_data = {"response": response, "context": context}
support = support_chain.invoke(input_data).response.strip().lower()
print(f"Support assessment: {support}")
# Step 6: Evaluate utility
print(f"Step 6: Evaluating utility for response {i+1}...")
input_data = {"query": query, "response": response}
utility = int(utility_chain.invoke(input_data).response)
print(f"Utility score: {utility}")
responses.append((response, support, utility))
# Select the best response based on support and utility
print("Selecting the best response...")
best_response = max(responses, key=lambda x: (x[1] == 'fully supported', x[2]))
print(f"Best response support: {best_response[1]}, utility: {best_response[2]}")
return best_response[0]
else:
# Generate without retrieval
print("Generating without retrieval...")
input_data = {"query": query, "context": "No retrieval necessary."}
return generation_chain.invoke(input_data).responseTest the self-RAG function easy query with high relevance and with a more challenging query with low relevance.
query = "What is the impact of climate change on the environment?"
response = self_rag(query, vectorstore)
print("\nFinal response:")
print(response)
query = "how did harry beat quirrell?"
response = self_rag(query, vectorstore)
print("\nFinal response:")
print(response)Closing Thoughts:
Navigating the world of interpretable rationale queries presents its own unique set of challenges, particularly when it comes to integrating domain-specific rationales into Large Language Models (LLMs) in a way that is easily understandable.
Prompt optimization is a complex, artisan-like process that needs a lot of time and computational resources. Every unique query needs custom-made prompts, which can be quite labor-intensive and slow to produce, despite their effectiveness. Furthermore, training AI models to create these personalized prompts is a hefty task, similar to running a marathon, due to the high computational costs involved. Then there's the challenge of limited interpretability. However, every challenge presents an opportunity for innovation and growth.
With ongoing research and development, we're gaining ground in understanding these complexities, inch by inch. By acknowledging these challenges, we can better equip ourselves to create AI models that are not just efficient and effective, but also transparent and trustworthy.
References:
[1]. Siyun Zhao , Yuqing Yang , Zilong Wang, Zhiyuan He, Luna K. Qiu, Lili Qiu, "Retrieval Augmented Generation (RAG) and Beyond: A Comprehensive Survey on How to Make your LLMs use External Data More Wisely", paper [2]. Wei Zhu, Wenfeng Li, Xing Tian, Pengfei Wang, Xiaoling Wang, Jin Chen, Yuanbin Wu, Yuan Ni, and Guotong Xie. Text2mdt: extracting medical decision trees from medical texts. arXiv preprint arXiv:2401.02034, 2024.
[3]. Binbin Li, Tianxin Meng, Xiaoming Shi, Jie Zhai, and Tong Ruan. Meddm: Llm-executable clinical guidance tree for clinical decision-making. arXiv preprint arXiv:2312.02441, 2023
[4] Junjie Zhang, Ruobing Xie, Yupeng Hou, Wayne Xin Zhao, Leyu Lin, and Ji-Rong Wen. Recommendation as instruction following: A large language model empowered recommendation approach. arXiv preprint arXiv:2305.07001, 2023.
[5] Tianjun Zhang, Xuezhi Wang, Denny Zhou, Dale Schuurmans, and Joseph E Gonzalez. Tempera: Test-time prompting via reinforcement learning. arXiv preprint arXiv:2211.11890, 2022.
[6] Archiki Prasad, Peter Hase, Xiang Zhou, and Mohit Bansal. Grips: Gradient-free, edit-based instruction search for prompting large language models. arXiv preprint arXiv:2203.07281, 2022.
[7] Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V Le, Denny Zhou, and Xinyun Chen. Large language models as optimizers. In The Twelfth International Conference on Learning Representations, 2024.
[8] Ziwei Ji, Tiezheng Yu, Yan Xu, Nayeon Lee, Etsuko Ishii, and Pascale Fung. Towards mitigating llm hallucination via self reflection. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 1827–1843, 2023.
[9] Zhaolong Wu, Abul Hasan, Jinge Wu, Yunsoo Kim, Jason PY Cheung, Teng Zhang, and Honghan Wu. Chain-ofthough (cot) prompting strategies for medical error detection and correction. arXiv preprint arXiv:2406.09103, 2024.
[10] KaShun Shum, Shizhe Diao, and Tong Zhang. Automatic prompt augmentation and selection with chain-ofthought from labeled data. arXiv preprint arXiv:2302.12822, 2023
[11] Hangfeng He, Hongming Zhang, and Dan Roth. Socreval: Large language models with the socratic method for reference-free reasoning evaluation. In Findings of the Association for Computational Linguistics: NAACL 2024, pages 2736–2764, 2024.
[12] https://blog.langchain.dev/agentic-rag-with-langgraph/
[13] Akari Asai† , Zeqiu Wu† , Yizhong Wang†§, Avirup Sil‡ , Hannaneh Hajishirzi, "SELF-RAG: LEARNING TO RETRIEVE, GENERATE, AND CRITIQUE THROUGH SELF-REFLECTION"