
Si tu as dompté un serpent, ce n'est pas un lapin qui va te faire peur !
RabbitMQ est un outil de transfert de messages très populaire qui repose sur un serveur qui utilise un message broker pour permettre aux applications de communiquer de manière efficace et fiable. Le broker, lui-même, est un service distinct.
Les producteurs et les consommateurs communiquent avec le broker en utilisant un protocole standard AQMP, de sorte que les applications individuelles n'ont pas à assumer la responsabilité et complexité du rassemblement des données, du routage, de la traduction des messages, de la persistance et la livraison des messages.
Cet article permet notamment d'introduire les notions clés avant d'utiliser le module python-rmq-module-1.1.0 créé pour uniformiser et accélérer les développements autour de RabbitMQ avec Python.
Pour plus d'informations connexes :
- Documentation RMQ
- La doc dont sont tirés les exemples 😉
- Un article de comparaison Kafka / RMQ
Speed Rabbit
RabbitMQ est un Message Broker très robuste développé en Erlang, basé sur AMQP.
Il s'appuie notamment sur :
- un système de clustering, ce qui en fait un système distribué compatible pour la haute disponibilité, fiabilité et l'évolutivité. Il permet d'augmenter la fiabilité, la disponibilité et les performances de RabbitMQ en répartissant la charge et en garantissant la disponibilité même en cas de défaillance d'un nœud.
- des virtual hosts qui permettent de cloisonner des environnements avec des groupes d'applications, de clients et utilisateurs différents (dev/preprod/prod par exemple) sur une même instance physique. Chaque hôte virtuel agit comme un conteneur logique qui contient des échanges, des files d'attente et des autorisations spécifiques à cet hôte ;
- un quality Of Service (QOS) pour prioriser les messages. Cela se fait principalement en contrôlant le nombre de messages préchargés par le client ou consommateur et en spécifiant si ce contrôle s'applique globalement à tous les consommateurs ou individuellement
Principaux composants
RabbitMQ transporte les messages depuis les producers vers les consumers. Le broker utilise les exchanges et bindings pour savoir si il doit délivrer ou non, le message dans la queue.
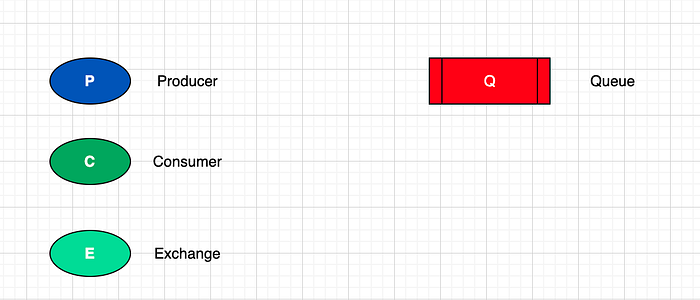
- Un producer est un service qui envoie des messages. Par exemple cela peut être M. Dupont qui souhaite envoyer une lettre à sa femme.
- Un consumer est un service qui reçoit les messages. En l'occurence, ce serait Mme Dupont dans notre exemple.
- Une queue est une entité qui stocke des messages (entre le producer et un ou plusieurs consumers) avant qu'ils soient consommés. Dans notre exemple, cela serait la boîte aux lettres de M. et Mme Dupont qui stocke les messages avant qu'ils soient récupérés et lus.
- Un exchange reçoit les messages et les envoie dans les queues pertinentes. Il joue le rôle de distributeur qui dirige vos messages vers les files d'attente appropriées en fonction de règles de routage que vous définissez. Dans notre exemple, cela serait le service de la Poste qui va acheminer la lettre dans la bonne boîte aux lettres en fonction des informations disponibles.
- Les informations / règles qui ont permis d'acheminer le message sont appelées des bindings. Dans notre exemple cela serait l'adresse postale.
Le flux classique est donc un producer qui va envoyer un message dans un exchange, responsable du bon acheminement. Ce dernier va, en fonction du binding, envoyer le message vers la ou les queues pertinentes. Ensuite un consumer va consommer les messages.
De quoi sont composés les messages ?
Comme une requête HTTP, il contient un payload (le contenu) et des attributs. En particulier, le message porte souvent des informations qui permettent de le faire transiter dans la ou les bonnes queues, on les appelle routing keys.
Comment les exchanges fonctionnent ?
Comme mentionné plus haut, l'exchange est globalement un routeur de message. Selon certaines règles, il va délivrer les messages aux queues pertinentes. Par défaut, l'exchange est amq.default : Il se lie (binde) avec toutes les queues ayant une routing key égale au nom de la queue.
Les types d'exchange les plus courants sont :
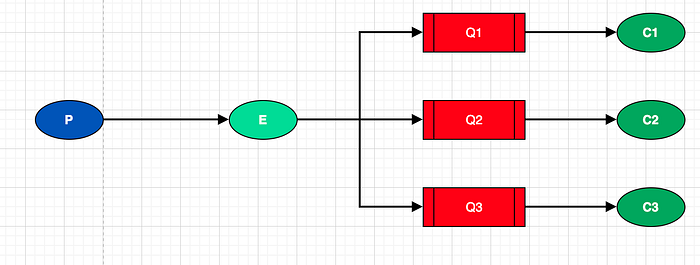
- Fanout
Délivre les messages à toutes les queues bindées à l'exchange.
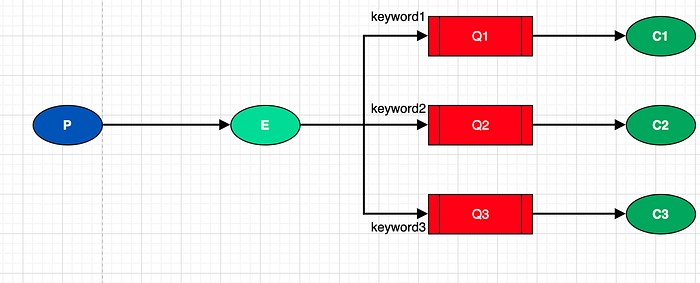
- Direct
Ne transfère que les messages utilisant la routing_key liée à la queue (par exemple, on ne binde que les messages correspondant à 'warning' dans la queue attaché à ce mot-clé).
- Topic
Ne transfère que les messages qui correspondent au pattern défini par la routing_key. Ce pattern s'appuie sur ces caractères :
- * se substitue à un mot
- # se substitue à 0 mot ou plus
- il en existe d'autres ( https://www.rabbitmq.com/tutorials/tutorial-four-python.html)
Maintenant qu'on a vu les bases sur le fonctionnement de RabbitMQ, voici quelques commandes communes.
Quelques commandes
- Lister les queues sur le serveur
rabbitmqctl list_queues- Lister les messages non traités (unacknowledged)
rabbitmqctl list_queues name messages_ready messages_unacknowledged- Lister les exchanges
rabbitmqctl list_exchangesRéalisation d'un premier flux de messages avec Python
Le but de l'article n'est pas d'expliciter l'installation de RMQ, vous pouvez vous référer à cette page pour l'installation. Nous supposerons ici qu'une version locale est installée et fonctionnelle.
Le code ci-dessous permet de mieux comprendre les composants de la librairie python-rmq-module-1.1.0. Il est alors possible ensuite, en à peine quelques lignes de code, de reproduire cet exemple avec la librairie.
Process
Ici nous allons simplement produire un message délivré dans une queue (via la routing_key) puis le consommer.
Pour cela, on créé deux fichier producer.py (resp. consumer.py) correspondant à notre producer (resp. consumer). Il faudra installer la librairie pika.
Production (producer.py)
Pour produire des messages, nous devons a minima :
- Etablir une connexion avec le serveur RabbitMQ (ici 'localhost' par exemple)
# Creating the connection
connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost'))- Créer un channel pour gérer les interactions
channel = connection.channel()- Déclarer une queue (on verra ensuite que dans la pratique on passe par des exchanges)
# Declaring a queue
channel.declare_queue(queue='test')- Publier un message avec basic_publish()
# Publishing message
channel.basic_publish(exchange='',
routing_key='test',
body='Hello World!')- Fermer la connexion une fois le message délivré et la connexion plus utile
# Closing the connection
connection.close()Nous sommes capables de publier des messages dans une queue 'test' ! Voyons la consommation désormais.
Consommation (consume.py)
- De la même façon, on doit déclarer une queue dans un channel ouvert avec le serveur RabbitMQ.
- On va ensuite consommer les messages (par exemple avec basic_consume() ) depuis la queue définie par la routing_key. La consommation des messages s'appuie sur une fonction callback qui sera activée pour chaque message intercepté ! (Ici elle affiche (print) le message reçu.)
def callback(ch, method, properties, body):
'''Callback function called when pika receive a message '''
print(f"Received {body}")
# This callack function will receive messages from our 'hello' queue
channel.basic_consume(queue='test',
auto_ack=True,
on_message_callback=callback
)Task/queues
Dans le process d'exemple ci-dessus, l'opération de traitement du message par le worker n'est pas coûteuse. En réalité les tâches réalisées par les consumers prennent du temps. Par défaut, RabbitMQ va distribuer les tâches aux uns après les autres de sorte que les consumers reçoivent en moyenne le même nombre de tâches.
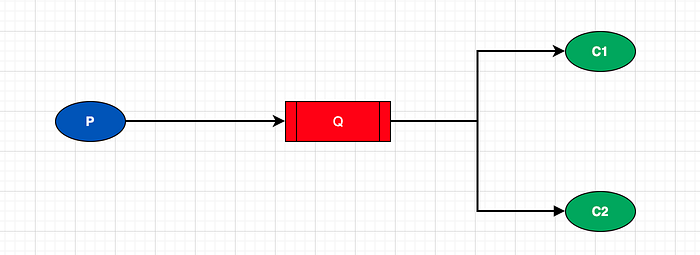
Mais que se passe-t-il si un consumer cesse de fonctionner ?
En l'état actuel, si on ouvrait plusieurs consumers et l'un d'eux mourrait, on perdrait les messages ! La connexion est perdue.
Heureusement RabbitMQ est capable de récupérer les tâches si un worker meurt.
En effet, on peut labelliser un message comme traité ou non par le worker (acknowledgement). Dès que le message a fini d'être traité, il est labellisé comme acknowledged. S'il n'a pas été traité entièrement (labellisé unacknowledged), dans le cas où le worker meurt, le message va être délivré à un autre. De cette façon, même si un worker meurt, le message ne sera pas perdu !

Pour mettre en place ce système de façon basique, on ajoute dans la fonction callback :
ch.basic_ack(delivery_tag = method.delivery_tag)Afin de mieux délivrer les messages, on peut forcer un worker à ne traiter qu'un message à la fois. Cela permet de délivrer les messages au worker pertinent plutôt que celui qui est occupé. Il suffit de préciser dans le consumer :
channel.basic_qos(prefetch_count=1)Et que se passe-t-il si le serveur stoppe ?
Les tâches sont perdues ! Mais encore une fois, on peut éviter cette situation.
Pour éviter de perdre définitivement les messages, on doit marquer les queues et les messages comme durables :
- Déclarer les queues comme durables (dans le consumer et producer)
channel.queue_declare(queue='task_queue_test', durable=True)- Publier les messages de façon persistante
channel.basic_publish(exchange='',
routing_key='task-queue_test',
body=message,
properties=pika.BasicProperties(
delivery_mode = 2, # make message persistent
)
)Maintenant nous avons limité le risque de perdre des messages !
Fanout Exchange
Pour l'instant, nous n'avons pas utilisé d'exchanges. Or c'est ce qui nous permet de dispatcher les messages selon les queues pertinentes. Le dispatch le plus basique est le fanout qui transfère les messages à toute queue rattachée à l'exchange.
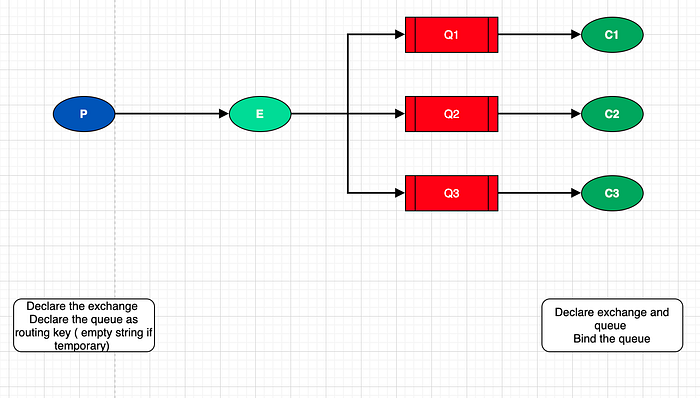
Dans un premier temps, nous devons déclarer l'exchange (dans le consumer et le producer) :
channel.exchange_declare(exchange='fanout_test',
exchange_type='fanout')On n'a pas besoin de déclarer de queue pour produire les messages ici ! On envoie sur l'exchange !
On peut publier sans déclarer de queue et en particulier sans préciser de routing_key (ignoré pour le fanout)
channel.basic_publish(exchange='fanout_test',
routing_key='', # no routing key
body=message,
properties=pika.BasicProperties(
delivery_mode = 2,
)
)Dans la plupart des cas, avec un fanout, la queue n'est pas importante et sera temporaire. On laisse donc RabbitMQ la nommer. Pour cela il suffit de mettre un empty string ' '. Lorsque la connexion avec le consumer sera fermée, la queue sera supprimée (c'est pour cela qu'on dit qu'elle est temporaire). Pour le préciser on ajoute exclusive=True dans la déclaration de la queue côté consumer :
result = channel.queue_declare(queue='',
exclusive=True, durable=True)Je dois finalement transférer les message à consommer par le consumer :
queue_name = result.method.queue
channel.queue_bind(exchange='fanout_test',queue=queue_name)Il ne reste plus qu'à consommer sur la queue en question :
channel.basic_consume(queue=queue_name,
on_message_callback=callback
)En ajoutant un consumer, on a donc créé une queue temporaire sur l'exchange fanout_test et à partir de laquelle les messages sont consommés !
Direct exchange
L'exchange Direct revient à transférer des messages à partir de mots-clés (correspondant à la routing_key lorsqu'on produit le message). Par exemple, je peux avoir une queue qui traite que des logs 'warning', une autre pour les logs 'info' etc.
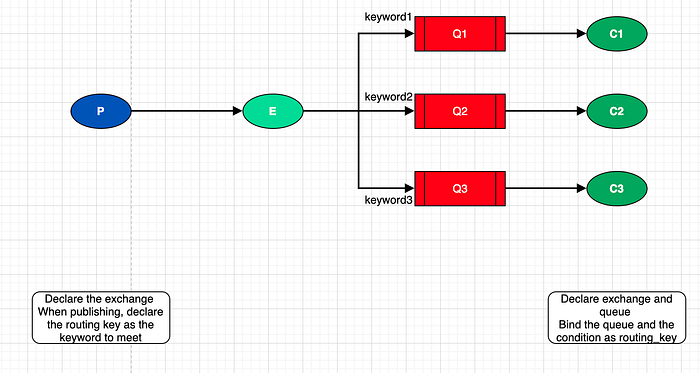
Pour transférer les messages, on vérifie donc qu'ils correspondent au mot-clé spécifié avec la routing key. Le message est délivré à la queue bindée avec ce mot-clé.
Tout d'abord (encore une fois), on doit préciser l'exchange (côté consumer et producer) :
channel.exchange_declare(exchange='direct_test',
exchange_type='direct')puis la clé pour binder les messages dans le producer :
channel.basic_publish(exchange='direct_test',
routing_key=keyword1, # On précise la clé de binding ici
body=message,
properties=pika.BasicProperties(
delivery_mode = 2
)
)On peut ensuite consommer les messages en bindant avec la bonne queue et la condition de la routing_key
result = channel.queue_declare(queue='', exclusive=True)
queue_name = result.method.queue
channel.queue_bind(exchange='direct_test',
queue=queue_name,
routing_key=keyword1)On peut donc ajouter une routing_key pour binder les messages vers des queues spécifiques qui correspondent à la clé.
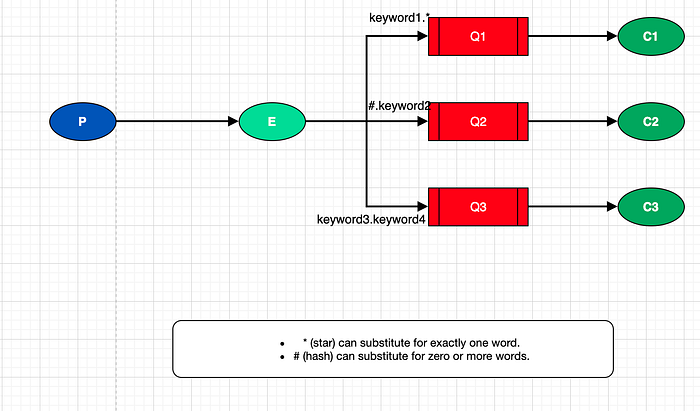
Topics
Il s'agit pour les topics, du même fonctionnement que l'exchange direct mais pour plusieurs mots-clés. Il y a deux règles spécifiques pour binder les messages :
- * peut substituer exactement 1 mot
- # peut substituer 0 mot ou plus
- d'autres
A noter qu'on peut avoir autant de mots-clés que voulu
Nous avons parcouru les éléments principaux qui composent RabbitMQ. Nous avons aussi vu du code basique pour implémenter les systèmes de messages communs et comprendre les différences.
Ces concepts permettent de mieux comprendre l'implémentation de la librairie python-rmq-module-1.1.0 afin de faciliter l'interface avec RabbitMQ en python. A vous de jouer pour les évolutions !