
"Gather together those things that change for the same reason, and separate those things that change for different reasons." — Single-responsibility principle, Robert C Martin.
A utopian goal for us in the data management and analytics profession is being able to map all your data into a single data model. But as data professionals we know that,
- Not all data is of equal value.
- Data comes in a variety of forms and often is not compatible with each other.
- Because of the above reasons, data is also landed in an analytics platform with different data quality. Beyond what is identified as critical data elements, how do data scientists discover what is valuable?
- Data often needs to be mastered, giving a 360 view on everything about that data may require applying matching rules to find a golden record across an organisation's data landscape.
- Data producers have their own priorities that are often at loggerheads with data analytics consumers. Data producer's own applications are meant to be encapsulated and yet data consumers have their own data needs for that data output.
- Software engineers adopting microservices are now compelled to make their data available in a variety of forms designed not to burden their own efficiency by adhering to data contracts (published APIs or a schema registry of an event driven architecture) they own.
If you're attempting to design a single data model to represent all the important data for your business does consolidating that to a Data Vault make sense? It can.
How did we get here? For the past few years Data Mesh has gained in popularity and traction amongst the most data-savvy organisations in the world. But why has Gartner declared Data Mesh "obsolete before plateau" in their annual Data Management hype cycle? Why do we see sceptics publishing articles like "Is Data Mesh Fool's Gold?" and the very topical substack article eloquently titled "Data is not a Microservice" declaring that a completely decentralised data analytics platform is not practical for your analytical data users?
Let's discuss the above paradox by going back to why data models exist in the first place.
Top Down: Business Architecture
Business architecture represents holistic, multidimensional business views of capabilities, end-to-end value delivery, information, and organisational structure, and the relationships among these business views and strategies, products, policies, initiatives, and stakeholders.
The practice of business architecture is often the first knowledge area of enterprise architecture frameworks that informs all other architecture knowledge areas dependent on it, these are:
· Application architecture — represents the specification and structural partitioning of technology-based automation into business logic, user experience, and data perspectives as an enabler of business architecture and strategy.
· Data architecture — represents integration of value specifications for qualitative and quantitative variables and their alignment with business architecture and strategy.
· Technology architecture — represents the logical and physical interconnection of infrastructure elements to enable the deployment and management of data architecture, application architecture, business architecture, and strategy.

Why should data engineers care? The latter knowledge areas of Enterprise Architecture do not exist without the business need for it. All knowledge areas below business architecture exist only to automate business architecture with everything encompassed by that discipline. Even if your enterprise is a start-up, you are practicing business architecture even if not formally. Should your endeavour scale to an enterprise covering multiple capabilities and find success with supporting and benefiting from thousands to millions of customers then it will become more abundantly clear that you need to map your business capabilities, values streams, and information to the best practices to automate your business processes.
Large or small, your enterprise is based on serving business objects with other business objects forming units of work or transactions. Essentially, we are mapping your business processes which when transacted emits data we want to capture and make useful for analytics to find opportunities to improve and enhance the customer experience and your own bottom line. It seems like a lot to understand and spend time deciphering, like most disciplines you must start at base principles and develop all other areas using those principles. As a customer-focussed enterprise relying on data, you need to understand the basic tenets applicable to all data. Your data will contain:
- Business objects, their definition and how to uniquely identify it.
- Unit of work or transaction, basically the business process bringing these business objects together forming recorded relationships.
- Descriptive attributes describing the business object or the transaction and historically tracking the changes to the state of that data.
These are the very things we track in a data vault,

Yes, data vault table objects are all you need to map your organization into a data model for the enterprise. From this point of view, is the data vault monolithic? Do we need to "boil the ocean" when building a data vault? Not it all, let's decipher this portion by going bottom-up!
Bottom Up: Independent Pipelines
"Software will eat the world" — Marc Andreessen
Applications automate business processes (as we have established), whatever the customer does, interacts with or purchases we track and pull/push into the analytics platform persisted as data, the comprehendible structure for us humans to make sense of and fulfil the analytical function.
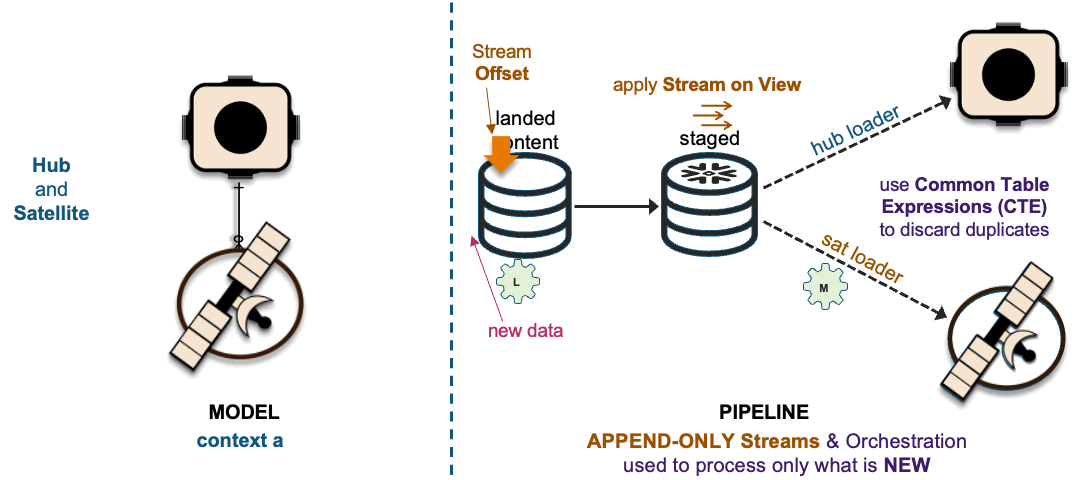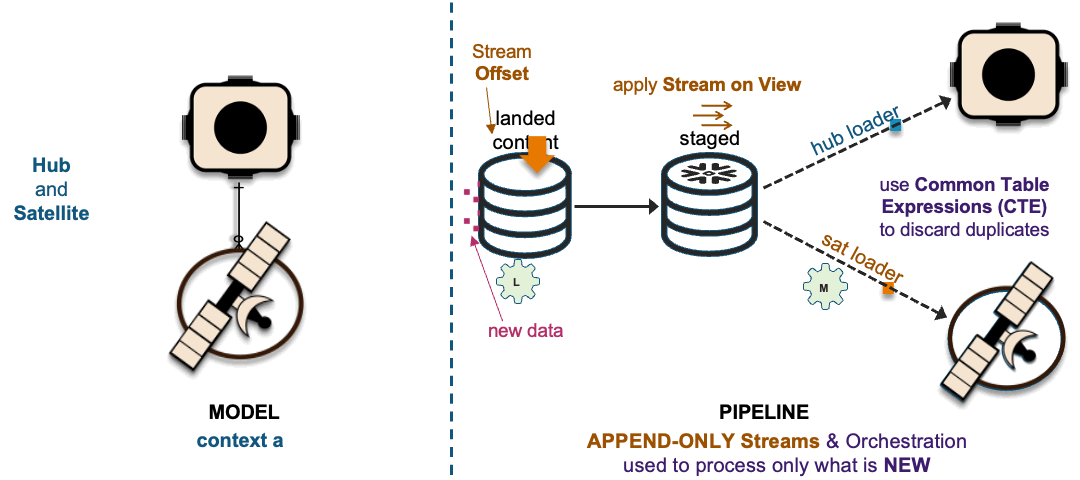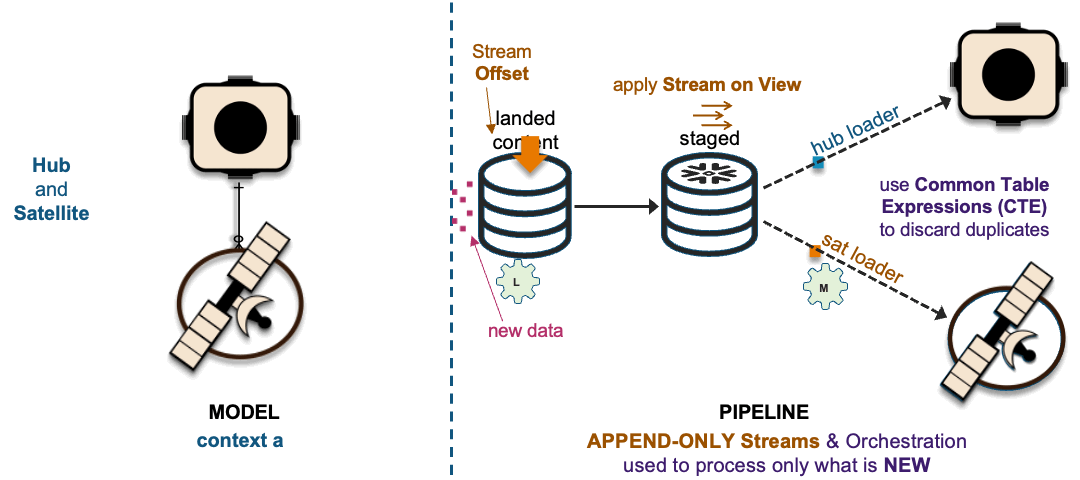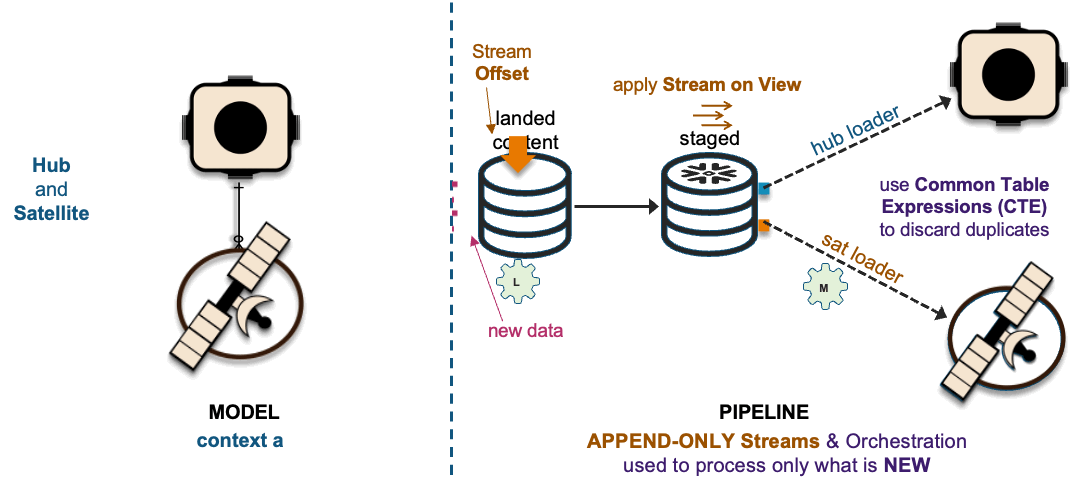
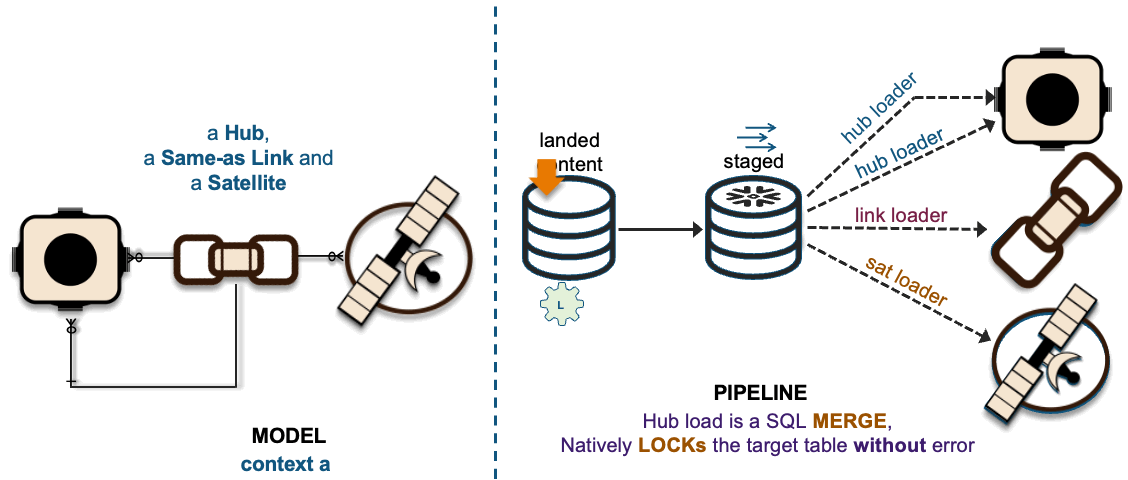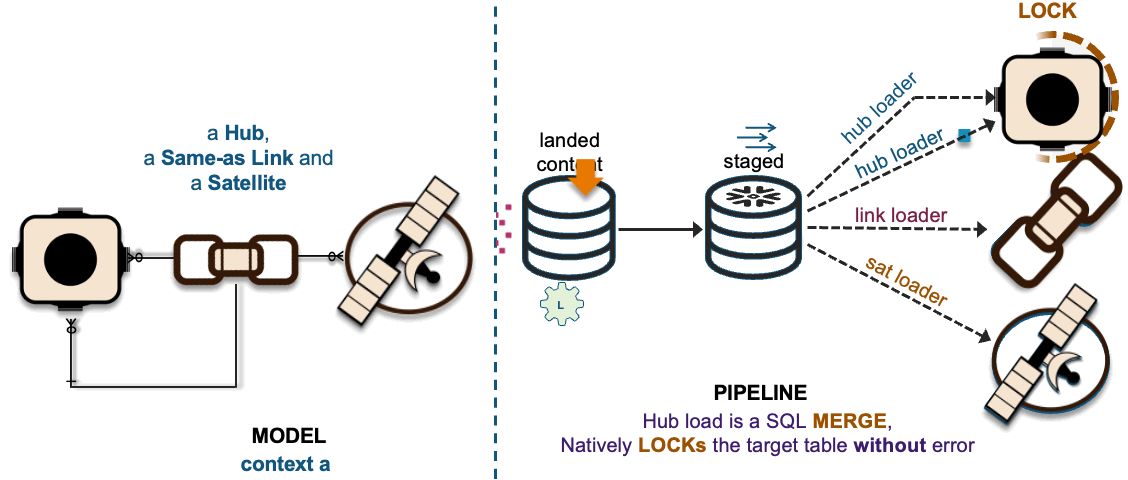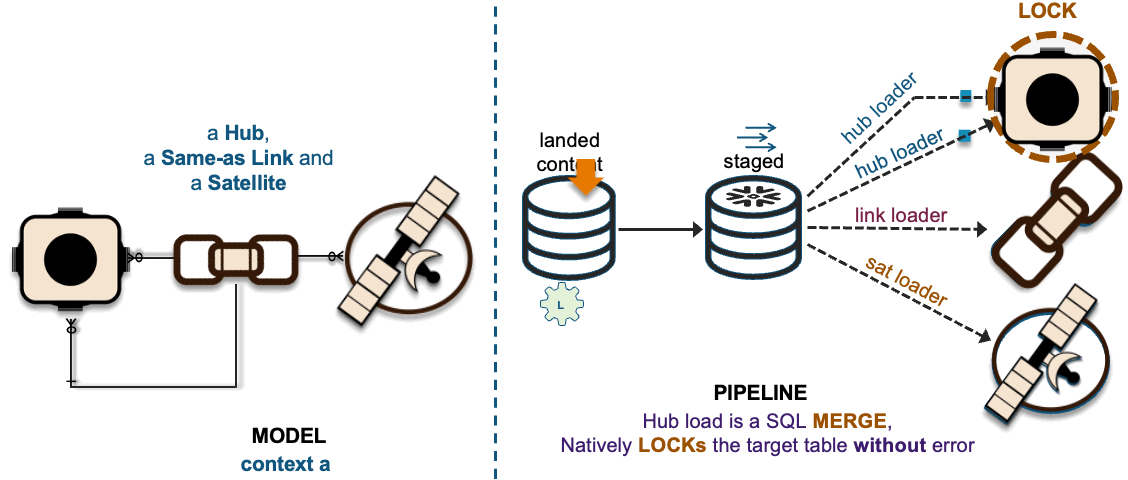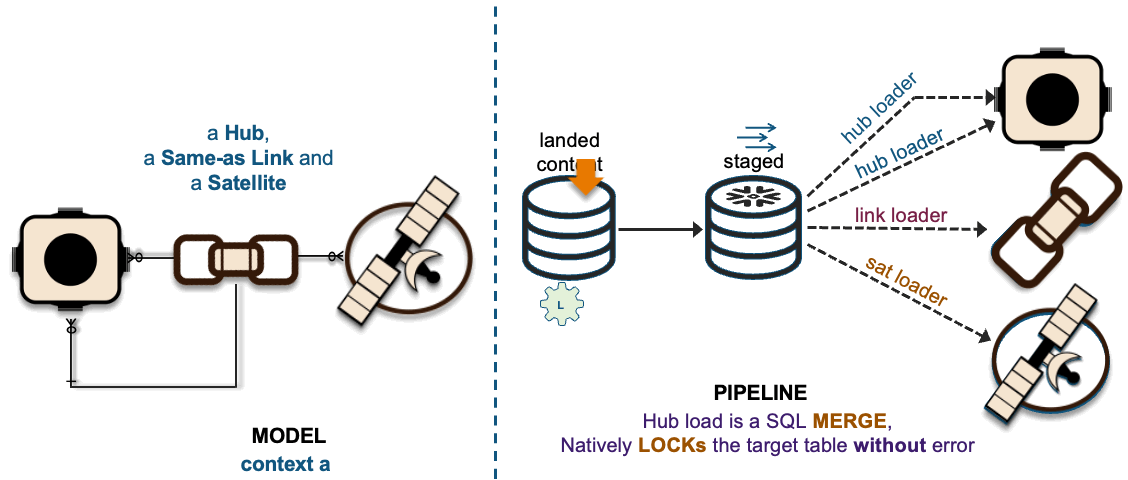
1xHub + 1xSat ~ 1xHub-Loader + 1xSat-Loader
The recording of these interactions is effectively mapped to data vault hub, link, and satellite tables. On the left in the above image, we have a simple hub and satellite data vault model and on the right is how the data pipeline is deployed on Snowflake. If you would like to learn more about the Streams on View pattern depicted above please visit this link.
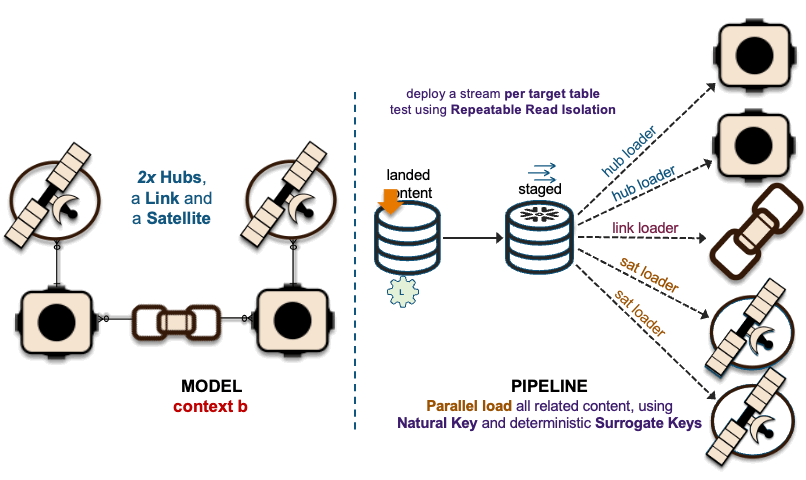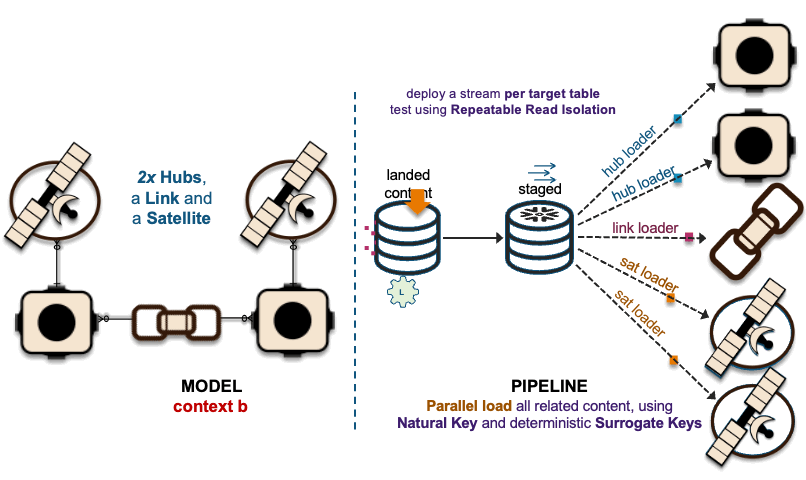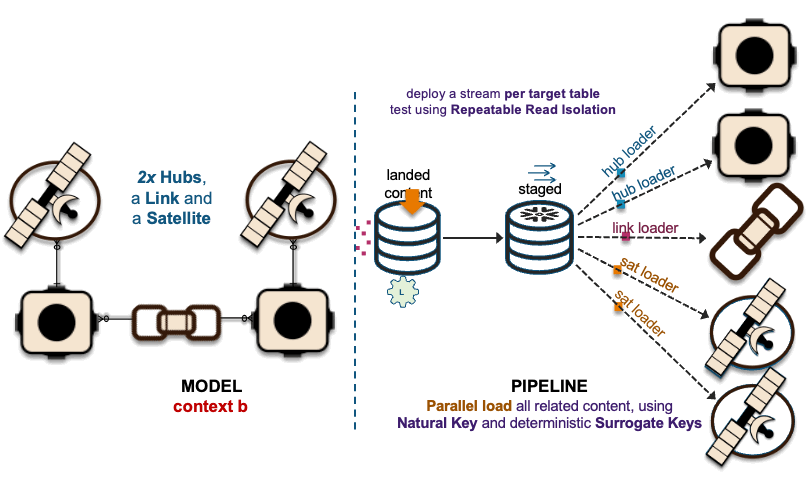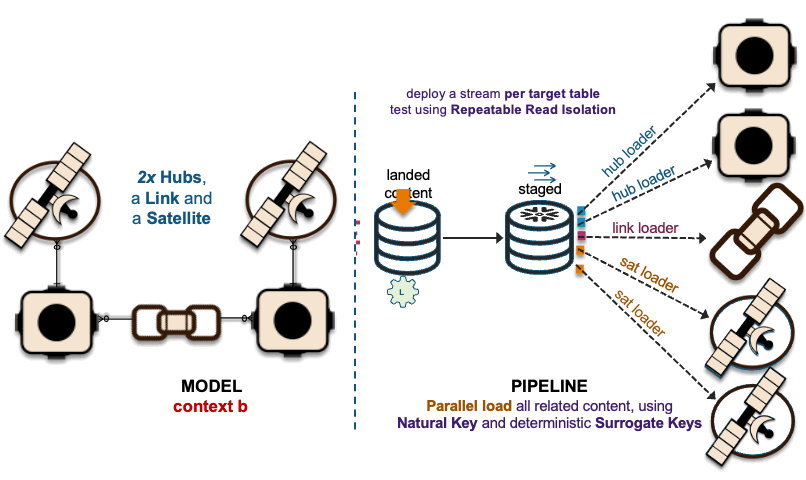
2xHub + 1xLink + 2xSat ~ 2xHub-Loaders + 1xLink-Loader + 2xSat-Loaders
What makes the data vault ideal for these interactions is the fact that we store the integration between,
- Business processes and value streams by business objects and how they are represented in those source systems (business process automation software).
- Raw and transformed business process outcomes (business vault) integrated around that business object or unit or work (transactions).
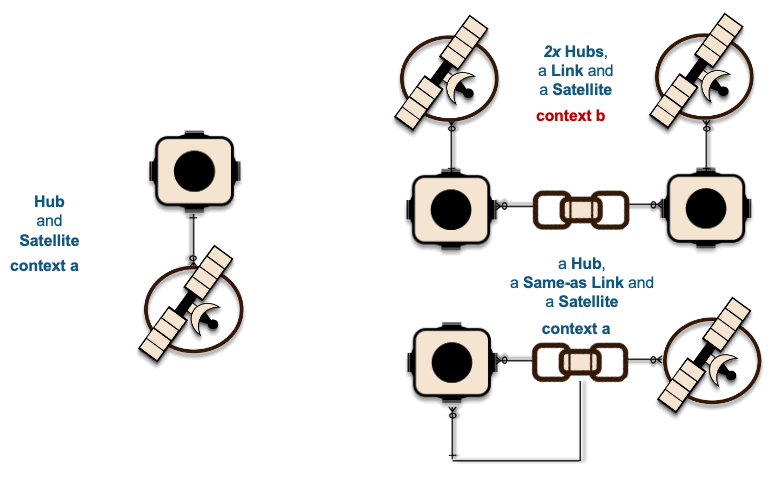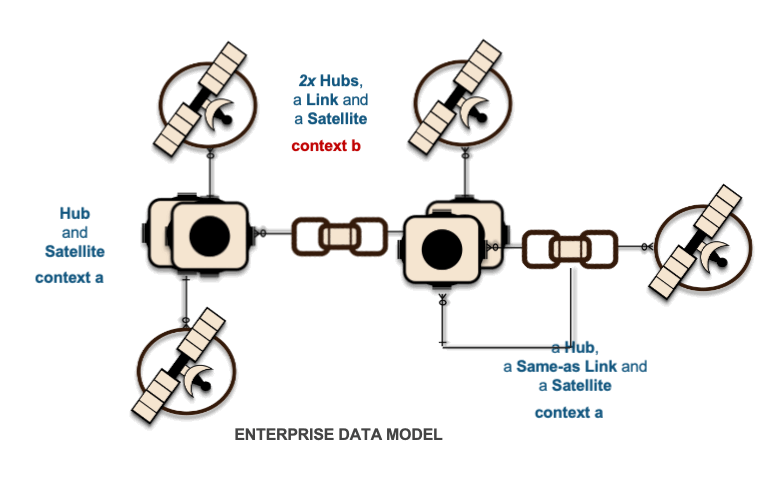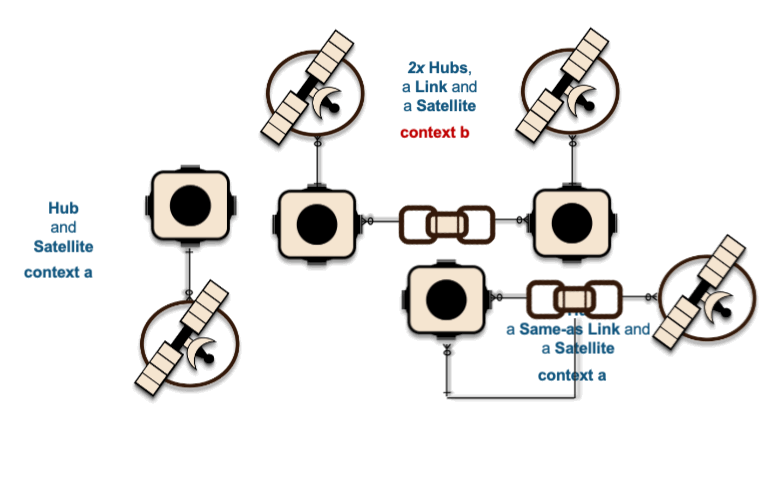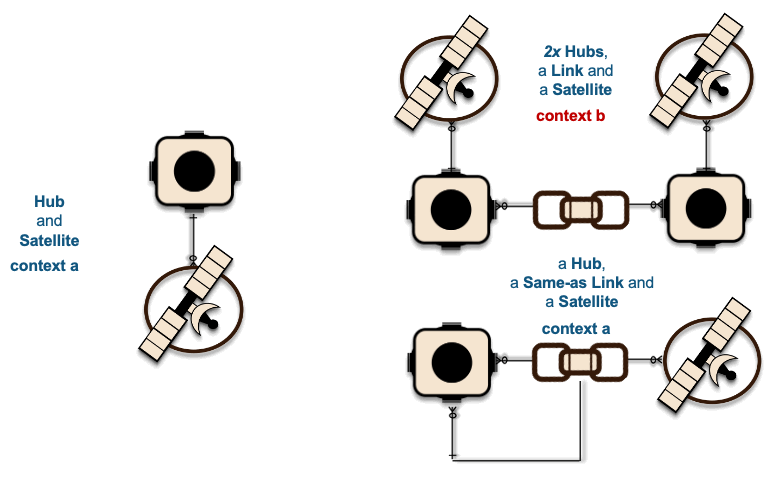
The image above depicts how these interactions are deployed as data vault table objects, because using surrogate hash keys is deterministic, all related elements from a single business process output state are captured in multiple hub tables, a link table depicting the unit of work and the associated satellite tables captured the descriptive content.
1xHub + 1xLink + 1xSat ~ 2xHub-Loaders + 1xLink-Loader + 1xSat-Loaders
Especially in an enterprise with a large portfolio of source systems there may be an effort to bring those disparate business key representations through master data management business rules. The result of which is a match-merged MDM id we can use as a business key to represent that integration within data vault. This interaction will relate two or more business keys to the same hub table and leave the decision up to you to decide which is the appropriate business key to represent that business object to your business.
Loading to a common hub table at the same time is a common activity within data vault and to ensure that independent data processing threads does not leave the hub table with duplicate keys; we change the SQL INSERT syntax to SQL MERGE and Snowflake will handle which data pipeline thread loads new records first. To learn more about this pattern click this link.
Each domain loading to an enterprise data model does not need to be in contention with other domains loading to the same data vault. Let's elaborate a little on this point.
The Middle: Passive Integration
"A system of Business Intelligence containing the necessary components needed to accomplish enterprise vision in Data Warehousing and Information Delivery" — Dan Linstedt, Data Vault inventor
Enterprise vision, represents that integration of data and business but what makes data vault unique in comparison to other data modelling techniques?
- It is non-destructive to change. Should a change in data model be required we simply:
o Add to the data model if it's new data. Integrate to an existing hub table or deploy a new one. Add new link tables if new business processes are being captured. New satellite tables if a new change state is captured.
o Turn off data pipelines if portions of the data model are no longer needed. It does not affect existing data modelling artefacts and it would be up to you if the content is persisted and for how long.
o Support schema drift for existing satellite tables.
- Enables information marts to become disposable. Should an information mart change be needed you can just as easily drop the information mart and redeploy them because all your auditable data is still within the data vault.
- Single version of the facts. Modelled in one enterprise data vault as efficiently structured modelling artefacts for unique business keys, unique relationships and true changes for those keys and relationships.
- Passive integration based on that business key, as independent data vault models are built by different domains, they in fact integrate to a single enterprise data vault model.
- Eventual Consistency of the enterprise data model, we emphasise the need for the enterprise data vault model governance but allow for independent streams to build their portions of the data vault as needed.
1xHub + 1xSat ~ 1xHub-Loader + 1xSat-Loader
2xHub + 1xLink + 2xSat ~ 2xHub-Loaders + 1xLink-Loader + 2xSat-Loaders
1xHub + 1xLink + 1xSat ~ 2xHub-Loaders + 1xLink-Loader + 1xSat-Loaders
2xHubs +2xLinks+4Sats ~ 5xHub-Loaders + 2xLink-Loaders + 4xSat-Loaders
At the world-wide data vault consortium in 2019, Bill Inmon updated his definition of what a data warehouse is:
"A data warehouse is a subject-oriented, integrated (by business key), time-variant and non-volatile collection of data in support of management's decision-making process, and/or in support of auditability as a system-of-record." — Bill Inmon, father of the data warehouse
We discussed these points and how data vault and data mesh can co-exist in the same platform in this article drawing the lessons from DDD. We further discussed business architecture and data vault recipes here and further elaborated on data vault thinking here.
In Closing
What the above implies is that a data vault way of delivering analytics has implications to your platform architecture (scalable and automated) and agile delivery (parallel teams, centralised data governance); a data-centric scalable model for delivering business value that aligns to business architecture. When integrating by business key (the hub tables) we can easily gather everything we need to know about a business object as raw vault link and satellite tables no matter which engine produced that business rule outcome. Raw vault if the business rule engine came from a source-system application and business vault if that business rule engine is executed within the data analytics platform.
The other effect not highlighted enough in other data vault literature is how the data vault patterns use Snowflake's OLAP join algorithms to bring this data together, i.e., why EQUI-JOINs matter. We discussed these patterns ad nauseam in these articles,
- Data Vault on Snowflake: Point-in-Time (PIT) constructs & Join-Trees — an explanation on Right Deep Join Trees and Hash Joins, bit.ly/3PNZJgr
- Data Vault on Snowflake: Expanding to Dimensional Models — reusing existing Data Vault table artefacts to produce a Star Schema, bit.ly/3qHKHSS
- Data Vault Mysteries… Zero Keys & Ghost Records, bit.ly/3vjTXdg
No matter the data model you will need to perform SQL joins between data brought into the analytics platform and data vault includes the minimal patterns needed to do that efficiently. We will explore these themes and more in the coming weeks, until next time!
The views expressed in this article are that of my own, you should test implementation performance before committing to this implementation. The author provides no guarantees in this regard.